1.MURAL:ヒンディー語で野菜を入れない素の麺が入った丼を検索されても対応画像を探せる人工知能(1/2)まとめ
・翻訳ペアを用いて共同で学習させるとリソース不足言語のクロスモーダル検索能力を向上可
・また、マルチモーダルモデルは言語同士の関係性に新たな視点を加える事ができる
・マルチモーダルモデルが暗黙的に学習する様々な関係はさらなる調査が必要と考えられる
2.MURALを使った言語のクラスタリング
以下、ai.googleblog.comより「MURAL: Multimodal, Multi-task Retrieval Across Languages」の意訳です。元記事は2021年11月30日、Aashi JainさんとYinfei Yangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Annie Spratt on Unsplash
多言語に対応する画像-テキスト、テキスト-画像検索
MURALの能力を実証するために、クロスモーダル検索(文章を使って関連する画像を検索する、またはその逆)タスクを選択しました。
そして、リソースが豊富な言語をカバーする様々な学術的な画像-テキストデータセットに対するスコアを調べました。
それらのデータセットには、MS-COCO(およびその日本語版、STAIR)、Flickr30K(英語)、 Multi30K(ドイツ語、フランス語、チェコ語に拡張)、XTD(よくリソースが使われる7言語によるテストのみのセット。イタリア語、スペイン語、ロシア語、中国語、ポーランド語、トルコ語、韓国語)を含めました。
リソースが豊富な言語に加え、最近発表されたWikipedia Image-Text(WIT)データセットでもMURALを評価しました。このデータセットは108言語をカバーし、リソースが豊富な言語(英語、フランス語、中国語など)とリソースが不足している(スワヒリ語、ヒンディー語など)の両方を幅広くカバーしています。
MURALは、リソースが十分ある言語とリソースが十分ない言語で評価したゼロショットと微調整の両方の設定で、M3P、UC2、ALIGNなどの先行する最先端モデルよりも常に優れた性能を発揮しました。リソース不足の言語では、最新モデルのALIGNと比較して、顕著な性能向上が見られました。
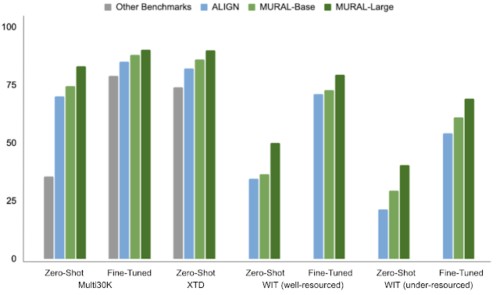
様々な多言語画像・テキスト検索ベンチマークにおける平均再現率(Mean recall)
平均再現率は、画像テキストデータセットにおけるクロスモーダル検索性能を評価するために用いられる一般的な指標です。(高いほど良い)。これは、6つの測定値を平均したRecall@N(すなわち、最初に検索されたN枚の画像の中に、基準となる画像が現れる確率)を測定します。N=[1,5,10]の「画像→テキスト検索」と「テキスト→画像検索」の6つの測定の平均値です。なお、XTDスコアでは、「テキスト→画像検索」のRecall@10を報告しています。
検索性能の分析
また、WITデータセットにおいて、英語(en)とヒンディー語(hi)のゼロショット検索事例をALIGNとMURALで比較分析しました。
ヒンディー語のようなリソースが乏しい言語では、MURALはALIGNに比べて検索性能が向上しており、これはテキストの持つ意味(semantics)をより良く理解していることを反映しています。

ヒンディー語テキストに対するWITデータセットのText→Image検索タスクにおいて、ALIGNとMURALで検索した上位5画像の比較。ヒンディー語の「एक तश्तरी पर बिना मसाले या सब्ज़ी केरी हुई सादी स्पगॅत्ती」は英訳すると「A bowl containing plain noodles without any spices or vegetables」(調味料や野菜を入れないプレーンな麺が入った丼)となります。
フランス語のようなリソースが豊富な言語での「画像→テキスト検索」でも、MURALはいくつかの単語でより良い理解を示しています。例えば、「cadran solaire」(フランス語で「日時計」)というクエリに対して、MURALはALIGNよりも良い結果を返しますが、ALIGNは日時計を説明するテキストを一切検索しません(下図)。

同じ日時計(sundial)画像に対するALIGNとMURALのテキスト検索結果の上位5位までの比較
Embeddingsの可視化
例えば、従来の研究ではニューラル機械翻訳(NMT:Neural Machine Translation)モデルによって学習された特徴表現は、言語族に属するかどうかに基づいてクラスタを形成することが示されています。
私たちは、ゲルマン語族(Germanic)、ロマンス語族(Romance)、スラブ語族(Slavic)、ウラル語族(Uralic)、フィンランド語族(Finnic)、ケルト語族(Celtic)、フィンランド・ウゴル語族(Finno-Ugric)(ヨーロッパと西アジアで広く話されている)に属する言語のサブセットに対して同様の視覚化を行ってみました。
MURALのテキストEmbeddingsと、テキストのみのエンコーダであるLaBSEのテキストEmbeddingsを比較しました。
LabSEのEmbeddingsをグラフ化すると、言語ファミリーの影響を受けた言語が明確にクラスタ化されていることがわかります。例えば、ロマンス語(Romance languages、下図紫)はスラブ語(Slavic languages下図茶)とは異なる領域に分類されます。この結果は、NMTシステムで学習された中間特徴表現を調査した先行研究とも一致します。
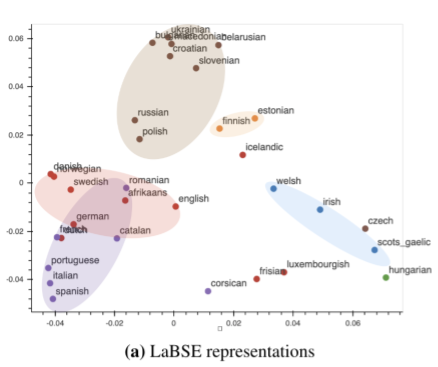
35言語のLaBSEのテキスト特徴表現を可視化したもの。言語は系譜の関連性に基づいて色分けされています。代表的な言語は以下の通りです。ゲルマン語(赤)-ドイツ語、英語、オランダ語。ウラル語(オレンジ)-フィンランド語、エストニア語。スラブ語(茶)-ポーランド語、ロシア語。ロマンス語(紫)-イタリア語、ポルトガル語、スペイン語。ゲール語(青)-ウェールズ語、アイルランド語。
LaBSEの可視化とは対照的に、マルチモーダルに学習したMURALのembeddingsでは、領域言語学(ある地理的な領域の言語や方言に共通する要素)や接触言語学(言語や方言が互いに影響しあい、交流する)に沿ったクラスタがいくつか見られます。
特に、MURALのembeddings空間では、ルーマニア語(ro)は、LaBSEよりも、バルカン半島の言語連合(Sprachbund:系統にかかわらず共通の文法的・音韻的特徴を示す言語群)に沿ってブルガリア語(bg)やマケドニア語(mk)といったスラブ系の言語と近い位置にあることがわかります。
また、言語接触の可能性から、フィンランドのエストニア語(et)、フィンランド語(fi)はスラブ語群に近いです。MURALが翻訳だけでなく画像にも軸足を置いていることは、テキストのみの設定で観察される言語ファミリーのクラスタリングを超えて、深い特徴表現で学習される言語関連性についての新たな視点を追加しているように見えます。
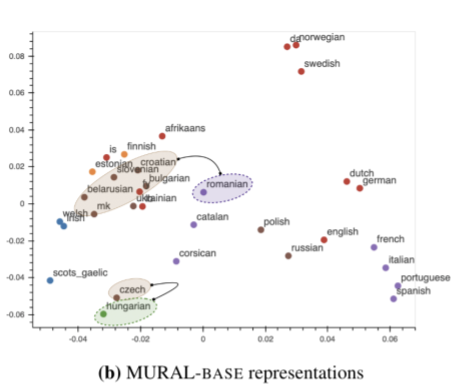
35言語に対するMURALのテキスト特徴表現の視覚化。色分けは上図と同じです。
最終コメント
本研究で得られた知見は、翻訳ペアを用いて共同で学習させると、リソース不足の多くの言語における画像-テキストペアのデータ不足を解消し、クロスモーダル性能を向上させることを示しています。
さらに、マルチモーダルモデルを用いて学習したテキスト表現に、領域言語学(areal linguistics)と接触言語学(contact linguistics)のヒントが観察されたことは興味深いです。
このことから、MURALなどのマルチモーダルモデルが暗黙的に学習する様々な関係について、さらに調査を行うことが必要と考えられます。最後に、私たちはこの研究が、リソースが豊富な言語以外にも、(画像やテキストで表現される)言語間の特徴表現と接続を学習するマルチモーダル、多言語空間におけるさらなる研究の促進につながることを期待しています。
謝辞
本研究は、Mandy Guo, Krishna Srinivasan, Ting Chen, Sneha Kudugunta, Chao Jia, 及び Jason Baldridgeとの共同研究です。Zarana Parekh, Orhan Firat, Yuqing Chen, Apu Shah, Anosh Raj, Daphne Luong、その他、このプロジェクトにフィードバックをくれた方々に感謝します。また、Google Research チームからの全般的な支援に感謝します。
3.MURAL:ヒンディー語で野菜を入れない素の麺が入った丼を検索されても対応画像を探せる人工知能(2/2)関連リンク
1)ai.googleblog.com
MURAL: Multimodal, Multi-task Retrieval Across Languages
2)arxiv.org
MURAL: Multimodal, Multitask Retrieval Across Languages