
1.WIT:ウィキペディアベースの画像-テキストデータセット(1/2)まとめ
・テキストにも視覚にも対応できるマルチモーダルなモデルは豊富なデータを必要とする
・既存のデータセットは質と量の両立が出来ておらず英語以外の言語への対応も不足
・WITはWikipediaの記事と画像か生成された大規模なマルチモーダル用データセット
2.WITとは?
以下、ai.googleblog.comより「Announcing WIT: A Wikipedia-Based Image-Text Dataset」の意訳です。元記事は2021年9月21日、Krishna SrinivasanさんとKarthik Ramanさんによる投稿です。
WITは日本語でもウィットで通じるかもしれませんが、機知、気転で、Whiteの意で使われる事もありますのでそこから連想した賢そうな白い鸚鵡のアイキャッチ画像のクレジットはPhoto by Mark Stoop on Unsplash
テキスト情報にも視覚情報にも対応できるマルチモーダルな視覚-言語モデル(visio-linguistic models)は、画像とテキストの関係をモデル化するために、豊富なデータセットを必要とします。
従来、これらのデータセットは、画像に手動で説明文を付けるか、インターネットからクローラーでデータを収集してimgタグ内に設定してあるalt-text文を画像に対する説明文として抽出することで作成されていました。
前者のアプローチではデータの品質が高くなる傾向がありますが、集中的に手動で注釈を付与する必要があるため、作成できるデータの量が制限されます。
一方、自動抽出アプローチではデータセットが大きくなる可能性がありますが、データ品質を確保するための経験則的と慎重なフィルタリング処理、または強力なパフォーマンスを実現するためにモデルの規模を拡大する事が必要です。
既存のデータセットの追加の欠点は、英語以外の言語への対応が不足している事です。この制限は自然に私たちを以下の疑問に導きました。「これらの制限を克服し、さまざまなコンテンツを含む高品質で大規模な多言語データセットを作成できるでしょうか?」
本日、ウィキペディアの記事とウィキメディアの画像に付与されたリンクから画像に関連付けられた複数の異なるテキスト選択を抽出することによって作成された、大規模なマルチモーダルデータセットである「Wikipedia-Based Image Text (WIT)データセット」を紹介します。
これには、高品質の画像テキストセットのみを保持するための厳密なフィルタリングが伴いました。SIGIR’21で発表された「WIT:Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning」で詳しく説明されているように、これにより、108の言語で1,150万の固有の画像を含む、3,750万の実体(entity)が豊富な画像-テキストのサンプルとして厳選されました。
WITデータセットは、クリエイティブコモンズライセンスの下でダウンロードして使用できます。また、ウィキメディアリサーチや他の外部の協力者と協力して、KaggleでWITデータセットとのコンテストを開催することを発表できることを嬉しく思います。
| Dataset | Images | Text | Contextual Text | Languages |
| Flickr30K | 32K | 158K | – | < 8 |
| SBU Captions | 1M | 1M | – | 1 |
| MS-COCO | 330K | 1.5M | – | < 4; 7 (test only) |
| CC-3M | 3.3M | 3.3M | – | 1 |
| CC-12M | 12M | 12M | – | 1 |
| WIT | 11.5M | 37.5M | ~119M | 108 |
従来のデータセットと比較して、WITは英語以外の対応言語が増え、サイズが大きくなっています。
WITデータセットのユニークな利点は次のとおりです。
・サイズ:WITは、公開されている画像-テキストデータの最大のマルチモーダルデータセットです。
・多言語:108の言語に対応しています。WITには他のデータセットの10倍以上の言語があります。
・コンテキスト情報:画像ごとに説明文が1つしかない一般的なマルチモーダルデータセットとは異なり、WITには多くのページレベルおよびセクションレベルの文脈情報が含まれています。
・現実世界の実体:幅広いナレッジベースであるウィキペディア内には、WITに収納された実世界の実体が豊富にあります。
・挑戦的なテストセット:EMNLPに受理された最近の研究結果では、すべての最先端モデルが、従来の評価セットと比較してWITで大幅に低いパフォーマンスを示しました。(たとえば、 再現率が最大30ポイント低下)
データセットの生成
WITの主な目標は、品質や概念の適用範囲を犠牲にすることなく、大規模なデータセットを作成することでした。したがって、私たちは現在、用可能な最大のオンライン百科事典であるウィキペディアを活用することから始めました。
入手可能な情報の深さの例については、以下のHalf Dome(カリフォルニア州ヨセミテ国立公園)のウィキペディアのページをごらんください。以下に示すように、この記事には、ページタイトル、メインページの説明、その他のコンテキスト情報やメタデータなど、画像に関連する多数の興味深いテキスト説明文と関連する文脈情報があります。
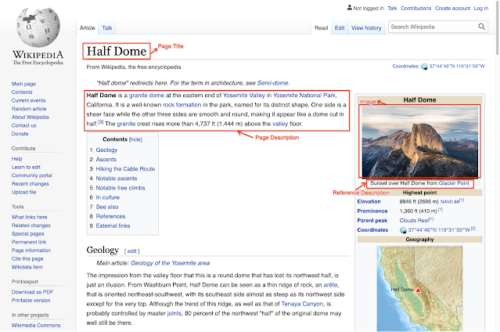
さまざまな画像関連のテキストが選択可能で文脈情報も含むウィキペディアページの例
Half Domeのウィキペディアページから:DAVIDILIFFによる写真。ライセンス:CCBY-SA3.0
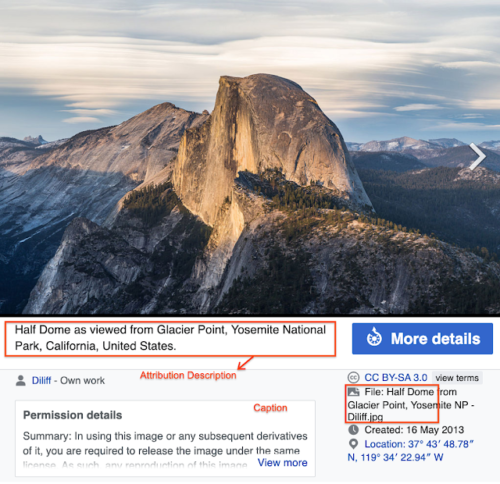
Half Domeのこの特定の画像のウィキペディアページの例
Half Domeのウィキペディアページから:DAVIDILIFFによる写真。 ライセンス:CCBY-SA3.0
画像が存在するウィキペディアのページを選択することから始め、次にさまざまな画像とテキストの関連付けと周囲の文脈を抽出しました。
データをさらに洗練するために、データ品質を確保する厳密なフィルタリングを実行しました。これには、画像説明文の可用性、長さ、品質を確保するためのテキストベースのフィルタリングが含まれていました。(たとえば、デフォルトで入力されるダミーテキストを削除することなど)。各画像が許可されたライセンスで特定のサイズに収まっている事を保証するための画像ベースのフィルタリングも行いました。
最後に、画像とテキストの実物に基づくフィルタリングにより、調査への適合性を確保しました。(たとえば、悪意のある表現として分類されたものを除外しました)。さらに、人間の編集者による評価のために画像キャプションセットをランダムにサンプリングしました。編集者は、サンプルの98%が画像と説明文の整合性が良好であることに圧倒的に同意しました。
3.WIT:ウィキペディアベースの画像-テキストデータセット(1/2)関連リンク
1)ai.googleblog.com
Announcing WIT: A Wikipedia-Based Image-Text Dataset
2)dl.acm.org
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
3)github.com
google-research-datasets / wit

