
1.取り返しのつかない行動を避ける可逆性を意識した自己教師型強化学習(3/3)まとめ
・時間的順序をモデル化して行動可逆性を予測し探索と制御を効率化出来る事を示した
・自己教師型であるため行動の可逆性に関する事前知識を必要とせず様々な環境に適している
・安全性を保つ事が重要なアプリケーション等にどのように適用できるかをさらに研究予定
2.デッドロックを禁止せずにパズルを解く
以下、ai.googleblog.comより「Self-Supervised Reversibility-Aware Reinforcement Learning」の意訳です。元記事の投稿は2021年11月3日、Johan Ferretさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by National Cancer Institute on Unsplas
(3)倉庫番のデッドロック回避
倉庫番ゲームは、倉庫の管理人を操作して、箱がそれ以上動かせなくなる状況(箱を4隅に押し込む事や場合によっては壁に隣接させてしまう場合など)を避けながら箱を目標位置に押し込むパズルゲームです。

倉庫番をクリアするためのアクション
箱(黄色の四角に赤い×印)をエージェントが押して、目的地(赤の枠線に・)に押し込まなければなりません。エージェントは箱を引っ張ることができないため、壁に押し付けられた箱は、壁から離れることができず、つまり「デッドロック(deadlocked)」となります。
標準的なRLモデルでは、初期のエージェントはランダムに近い形で環境を探索し、その結果、頻繁に行き詰まってしまいます。このようなRLエージェントは、倉庫番パズルを解けないか、非常に効率が悪いのです。

ランダムに探索するエージェントは、すぐにデッドロックに陥り、レベルをクリアすることができません。(例えば、壁の右端の箱を押しつけてしまうと元に戻すことができません)
最先端のモデルフリーRLエージェントであるIMPALAとIMPALA+RAEエージェントの倉庫番環境でのパフォーマンスを比較しまた。その結果、IMPALA+RAEを併用したエージェントの方がデッドロックの頻度が少なく、優れたスコアが得られることがわかりました。
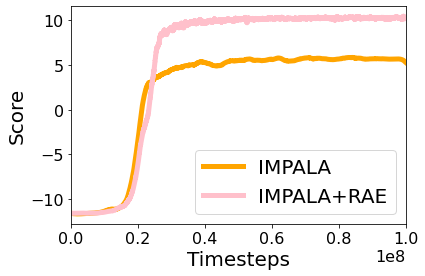
IMPALAとIMPALA+RAEに倉庫番の1000レベルを実行させた際のスコアです。ベストスコアはレベルに依存し、10に近い値となります。
このタスクは、非常にバランスの悪い学習問題であるため、不可逆的なアクションの検出が困難です。実際に不可逆的な行動は全体の1%程度ですが、その他の多くの行動は可逆的であることを示すのが難しいためです。なぜなら、エージェントがいくつかの追加ステップを経なければ元に戻せないからです。
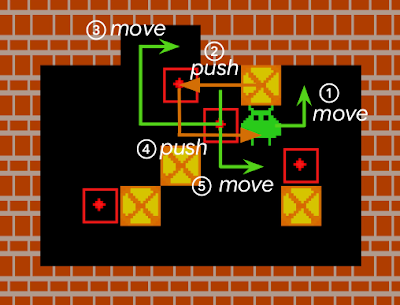
ある動作を元に戻すことは、時に自明ではありません。ここに示す例では箱が壁に押しつけられていますが、まだ元に戻すことができます。しかし、この状況を元に戻すには、少なくとも5つの個別操作が必要であり、エージェントによる17の異なるアクションが必要になります。(それぞれの番号のついた操作はエージェントによる複数のアクションの結果です)
推定では、倉庫番のレベルの約半分は、少なくとも1つの不可逆的な行動を必要とします。(例えば、少なくとも1つの目的地が壁に隣接しているなど)。IMPALA+RAEはほぼすべてのレベルを解くことができるので、RAEはエージェントが不可逆的な行動をとることを妨げないことを意味します。
結論
本論文ではRLエージェントがランダムに収集された軌道イベントの時間的順序をモデル化して学習することにより、行動の可逆性を予測し、より良い探索と制御を実現する手法を提案しました。
提案手法は自己教師型であり、行動の可逆性に関する事前知識を必要としないため、様々な環境に適しています。将来的には、これらのアイデアをより大規模なアプリケーションや安全性を保つ事が重要なアプリケーションにどのように適用できるかをさらに研究したいと考えています。
謝辞
本論文の共著者であるNathan Grinsztajn, Philippe Preux, Olivier Pietquin そして Matthieu Geistに感謝いたします。また、Bobak Shahriari, Théophane Weber, Damien Vincent, Alexis Jacq, Robert Dadashi, Léonard Hussenot, Nino Vieillard, Lukasz Stafiniak, Nikola Momchev, Sabela Ramosをはじめ、本研究について有益な議論やフィードバックをいただいたすべての方々に感謝いたします。
3.取り返しのつかない行動を避ける可逆性を意識した自己教師型強化学習(3/3)関連リンク
1)ai.googleblog.com
Self-Supervised Reversibility-Aware Reinforcement Learning
2)arxiv.org
There Is No Turning Back: A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning

