
1.COVID-19疫学のための機械学習ベースのフレームワーク(2/2)まとめ
・COVID19 ForecastHubに登録されている他のモデルをほぼ上回った
・本フレームワークでは仮定に基づいてシミュレーションができる
・特定のグループでモデルの精度が悪化しない事も確かめられている
2.GoogleのCOVID-19感染予測の予測精度
以下、ai.googleblog.comより「An ML-Based Framework for COVID-19 Epidemiology」の意訳です。元記事は2021年10月13日、Joel ShorさんとSercan Arikさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Dimitar Donovski on Unsplash
予測精度
毎日、モデルをトレーニングして、28日後のCOVID-19関連の結果(主に死亡と症例数)を予測します。COVID-19に関連する結果の累積値と週ごとの増分値の両方を使用して、国全体のスコアと場所レベルのスコアの両方の平均絶対パーセント率(MAPE:Mean Absolute Percentage Error)を報告します。
私たちのフレームワークを、COVID19 ForecastHubに登録されている米国の他のモデルと比較しました。MAPEでは、私達のモデルは1つを除く他の33のモデルすべてを上回っています。この1つは私達のモデルの予測も含めたアンサンブル予測で、精度差は統計的に有意ではありません。
また、予測の不確実性を使用して、予測が正確である可能性が高いかどうかを推定しました。モデルが不確実であると見なす予測を拒否した場合、リリースする予測の精度を向上させることができます。これが可能なのは、モデルの不確実性が適切に調整されているためです。
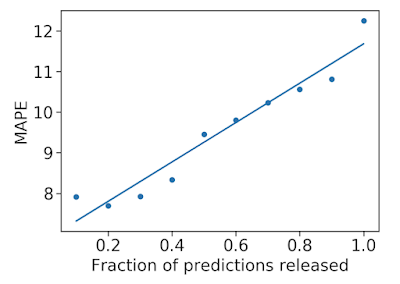
不確実な予測を削除すると、平均平均誤差率(MAPE、低いほど良い)が減少し、精度が向上します。
パンデミック管理のポリシーと戦略をシミュレートするWhat-Ifツール
過去のデータから得られる最も可能性の高いシナリオを理解することに加えて、意思決定者は、さまざまな決定が将来の結果にどのように影響するか、たとえば、学校の閉鎖、移動制限、さまざまな予防接種戦略の影響を理解することに関心があります。
このフレームワークでは、特定の変数の予測値を反実例に置き換えることで、反実例分析(counterfactual analysis)を行うことができます。シミュレーションの結果は、急速な病気の拡大が抑えられるまで、非医薬品的介入(NPI:Non-Pharmaceutical Interventions)を早急に緩和することのリスクを補強するものでした。同様に、日本でのシミュレーションでは、高いワクチン接種率を維持しながら非常事態宣言を維持することで、感染率が大幅に低下することが示されました。
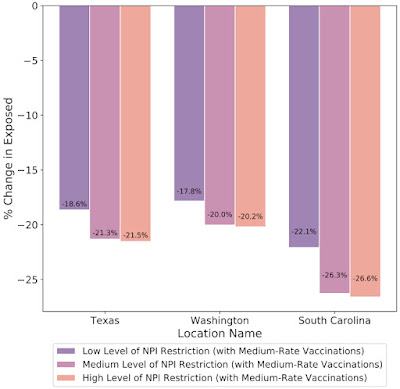
テキサス、ワシントン、サウスカロライナでの2021年3月1日の予測日に異なる非医薬品介入(NPI)を想定して予測した、曝露した個人の変化率に関する仮定シミュレーション。NPI制限の増加は、曝露した人々の数の大幅な減少に関連しています。
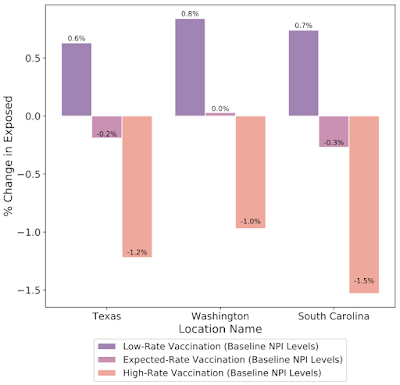
テキサス、ワシントン、サウスカロライナでの2021年3月1日の予測日に異なる予防接種率を想定して予測した、曝露した個人の変化率に関するwhat-ifシミュレーション。ワクチン接種率の上昇も、これらの場合の曝露数を減らすために重要な役割を果たします。
公平性分析
モデルが不当に偏った意思決定を作成または強化しないようにするために、AI原則に沿って、特定のサブグループでモデルの精度が悪いかどうかを定量化することにより、米国と日本の予測に対して個別に公平性分析を実行しました。
これらのカテゴリには、米国の年齢、性別、収入、民族、日本の年齢、性別、収入、出身国が含まれます。
すべてのケースで、COVID-19の死亡数と各サブグループで発生するケースを制御した後、これらのグループ間で一貫したエラーパターンは示されませんでした。
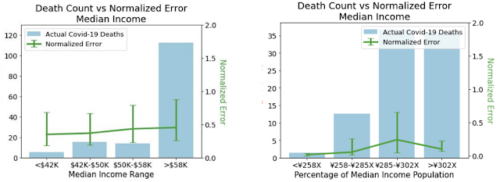
誤差を所得の中央値で正規化した図
両者を比較すると、誤差を正規化すると、誤差のパターンは持続しないことがわかります。
左:米国の収入の中央値による正規化されたエラー
右:日本の収入の中央値による正規化されたエラー
実際の使用例
モデルのパフォーマンスを測定するための定量分析に加えて、組織がモデル予測をどのように使用しているかを理解するために、米国と日本で構造化調査を実施しました。合計7つの組織が、モデルの適用可能性について次の結果を回答しました。
・組織の種類:学術界(3)、政府(2)、民間産業(2)
・主なユーザーの職務:アナリスト/科学者(3)、医療専門家(1)、統計家(2)、管理職(1)
・場所:アメリカ(4)、日本(3)
・使用された予測:確認された症例(7)、死亡(4)、入院(4)、ICU(3)、人工呼吸器(2)、感染(2)
・モデルのユースケース:リソース割り当て(2)、ビジネスプランニング(2)、シナリオプランニング(1)、COVIDの拡散の一般的な理解(1)、既存の予測の確認(1)
・使用頻度:毎日(1)、毎週(1)、毎月(1)
・モデルは役に立ちましたか?:はい(7)
いくつかの使用事例を共有すると、米国では、ハーバードグローバルヘルスインスティテュートとブラウンスクールオブパブリックヘルスが予測を使用して、メディアが一般の人々に知らせるために使用したCOVID-19テストターゲットの作成を支援しました。
米国国防総省は、予測を使用して、リソースを割り当てる場所を決定し、特定のイベントを考慮に入れるのに役立てました。日本では、このモデルを使用してビジネス上の意思決定を行いました。20都道府県以上に店舗を持つある大規模な多国籍企業は、この予測を使用して、売上予測をより適切に計画し、営業時間を調整しました。
制限と次のステップ
私たちのアプローチにはいくつかの制限があります。 第一に、入手可能なデータによって制限されています。信頼できる高品質の公開データがある場合にのみ、毎日の予測を公開することができます。たとえば、公共交通機関の利用状況は非常に役立つ可能性がありますが、その情報は公開されていません。
第二に、区画モデルはCovid-19疾患の伝播の非常に複雑なダイナミクスをモデル化できないため、モデル容量に起因する制限があります。
第三に、症例数と死亡数の分布は、米国と日本で大きく異なります。たとえば、日本のCOVID-19の症例と死亡のほとんどは、47の都道府県のいくつかに集中しており、他の都道府県は低い値になっています。
つまり、日本のすべての都道府県でうまく機能するように訓練された県ごとのモデルは、これらの比較的COVID-19のない都道府県からのデータを教師としながら、ノイズへの過剰適合を回避することの間で微妙なバランスをとらなければならないことがよくあります。
ワクチン接種者数の増加など、疾患のダイナミクスの大きな変化を考慮してモデルを更新しました。また、行政区、病院、民間組織との新たな取り組みにも拡大しています。
私たちの公開リリースが、現在進行中のパンデミックの課題に市民と政策立案者が取り組むのに引き続き役立つことを願っています。また、私たちの方法が、現在および将来の健康危機において疫学者と公衆衛生当局に役立つことを願っています。
謝辞
本論文は、Google内のさまざまなチームと世界中の協力者による懸命な努力の結果です。特に、慶應大学医学部、聖路加国際大学大学院公衆衛生大学院、東京大学大学院医学研究科の共著者に感謝します。
3.COVID-19疫学のための機械学習ベースのフレームワーク(2/2)関連リンク
1)ai.googleblog.com
An ML-Based Framework for COVID-19 Epidemiology
2)www.nature.com
A prospective evaluation of AI-augmented epidemiology to forecast COVID-19 in the USA and Japan
3)github.com
reichlab / covid19-forecast-hub
4)datastudio.google.com
COVID-19 感染予測 (日本版)

