
1.Omnimattes:動画内の影や砂埃も切出す事ができる最先端の人工知能(2/2)まとめ
・画像を操作する手法は、偽情報を生成するために悪用される可能性があるので留意が必要
・オムニマットは現状の制限としてカメラ位置が固定していないと画面が乱れる時がある
・画像の相関関係を学習するためのCNNの機能と制限を完全に理解することも必要となる
2.オムニマットを使った動画の時間操作
以下、ai.googleblog.comより「Introducing Omnimattes: A New Approach to Matte Generation using Layered Neural Rendering」の意訳です。元記事は2021年8月31日、Forrester ColeさんとTali Dekelさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Richard Sagredo on Unsplash
オムニマットシステムの詳細を以下に示します。前処理では、ユーザーは処理対象を選択し、それぞれのレイヤーを指定します。各被写体用のセグメンテーションマスクは、MaskRCNNなどの既製のセグメンテーションネットワークを使用して抽出され、背景に対するカメラの変換は、標準のカメラ安定化ツールを使用して検出されます。
ランダムノイズ画像は、照合元の背景フレームで定義され、カメラ変換を使用してサンプリングされ、フレームごとのノイズ画像が生成されます。ノイズ画像は、ランダムではあっても時間の経過とともに一貫している背景を追跡する画像特徴を提供し、CNNが背景色を再構築することを学習するための自然な入力を提供します。
レンダリングCNNは、セグメンテーションマスクとフレームごとのノイズ画像を入力として受け取り、各レイヤーの透明度を捕捉するRGBカラー画像とアルファマップを生成します。これらの出力は、従来のアルファ ブレンディングを使用して併合され、出力フレームが生成されます。
CNNは、マスクに捕捉されていない効果(影、反射、煙など)を見つけて特定の前景レイヤーに関連付け、対象のアルファにセグメンテーションマスクが大まかに含まれるようにすることで、入力フレームを再構築するようにゼロからトレーニングされます。前景レイヤーが前景要素のみを捕捉し、静止背景をキャプチャしないようにするために、スパース性の損失も前景のアルファに適用されます。
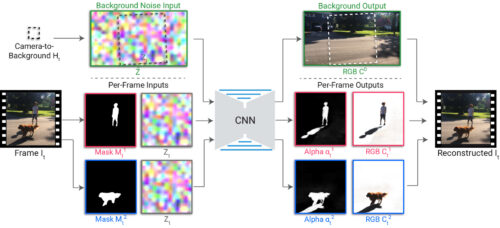
新しいレンダリングネットワークは、ビデオごとにトレーニングされます。
ネットワークには単一の入力ビデオを再構築する事のみが求められるため、以下に示すように、各被写体の効果を分離することに加えて、微細な構造と速い動きを捕捉することができます。
ウォーキングの例では、オムニマットには公園のベンチの羽根板に投影された影が含まれています。テニスの例では、薄い影とテニスボールさえも捕捉されます。サッカーの例では、プレーヤーの影とボールが適切なレイヤーに分解されます。(プレーヤーの足がボールによって遮られると、わずかなエラーが発生しています)



この基本モデルはすでにうまく機能していますが、オプティカルフローやテクスチャ座標などの追加のバッファでCNNの入力を増やすことで、結果を改善できます。
オムニマットを使ったアプリケーション
オムニマットが生成されたら、どのように使用できるでしょうか?
上に示したように、複合レイヤーから対象物のレイヤーを削除するだけで、物体を削除できます。複合レイヤー内で対象物のレイヤーを繰り返すことで、物体を複製することもできます。
以下の例では、馬のビデオがパノラマ写真内に展開されており、馬が数回複製されてストロボ写真効果が生成されています。馬が地面や障害物に投げかける影が正しく捕捉されていることに注目してください。

より繊細ですが強力なアプリケーションは、被写体の時間軸を再調整することです。
時間操作はフィルムで広く使用されていますが、通常、被写体ごとに別々のショットと制御された撮影環境が必要です。
オムニマットを使った分解により、各レイヤーの再生速度を個別に変更するだけで、後処理のみを使用して日常のビデオにリタイミング効果を適用する事が可能になります。オムニマットは標準のRGBA画像であるため、このリタイミング編集は従来のビデオ編集ソフトウェアを使用して実行できます。
以下のビデオは、お子様ごとに1つずつ、3つのレイヤーに分解されています。お子様の最初の同期されていないジャンプは、レイヤーの再生速度を調整するだけで調整され、水中での水しぶきや反射のリアルなリタイミング効果を生み出します。

元ビデオ(左)では、各子供は異なる時間にジャンプします。編集後(右)、みんなで同時にジャンプします。
画像を操作する新しい手法は、偽情報や誤解を招く情報を生成するために悪用される可能性があるため、責任を持って開発および適用する必要があることを考慮することが重要です。
私たちの技術はAIの原則に従って開発され、ビデオ内にすでに存在するコンテンツの再配置のみを許可しますが、これらの例に示すように、単純な再配置でもビデオの効果を大幅に変えることができます。研究者はこれらのリスクに注意する必要があります。
今後の研究
オムニマットの品質を向上させるためのエキサイティングな方向性がいくつかあります。
実用的なレベルでは、このシステムは現在、カメラの位置が固定されており、背景がパノラマでモデル化できる場合のみをサポートしています。カメラ位置が移動すると、パノラマモデルは背景全体を正確に補足できず、一部の背景要素が前景レイヤーを乱す可能性があります。(上で紹介した画像内も時折乱れています)
部屋の中を歩いたり、通りを歩いたりするなど、完全に一般的なカメラの動きを処理するには、3D背景モデルが必要になります。動く物体や効果の存在下での3Dシーンの再構築は、依然として困難な研究課題ですが、最近の進歩が期待されています。
理論レベルでは、相関を学習するCNNの機能は強力ですが、それでもやや理論的に解明されていない部分があり、必ずしも期待される層の分解につながるとは限りません。私たちのシステムでは、自動結果が不完全な場合に手動で編集できますが、より良い解決策は、画像の相関関係を学習するためのCNNの機能と制限を完全に理解することです。このような理解は、ノイズ除去、修復、およびレイヤー分解以外の多くの他のビデオ編集アプリケーションの改善につながる可能性があります。
謝辞
オックスフォード大学のErika Luは、Googleでの2回のインターンシップ中にオムニマットシステムを開発しました。
Googleの研究者であるForrester Cole, Tali Dekel, Michael Rubinstein, William T. Freeman and David Salesin、オックスフォード大学の研究者であるWeidi XieとAndrew Zissermanと共同です。
サンプルビデオに出演することに同意してくれた作者の友人や家族に感謝します。「horse jump low」、「lucia」、「tennis」の動画は、DAVIS 2016データセットからのものです。サッカービデオは、Online Soccer Skillsの許可を得て使用しています。車のドリフトビデオはShutterstockからライセンス供与されました。
3.Omnimattes:動画内の影や砂埃も切出す事ができる最先端の人工知能(2/2)関連リンク
1)ai.googleblog.com
Introducing Omnimattes: A New Approach to Matte Generation using Layered Neural Rendering
2)arxiv.org
Omnimatte: Associating Objects and Their Effects in Video
3)omnimatte.github.io
Omnimatte: Associating Objects and Their Effects in Video

