
1.SoundStream:ビットレート可変なニューラルオーディオコーデック(2/2)まとめ
・理想的なコーデックはネットワーク状態に応じてビットレートを変更できる能力が必要
・SoundStreamは「量子化器ドロップアウト」と呼ばれる新手法でこれを実現
・SoundStreamは、Lyraの次の改良バージョンの一部としてリリースされる予定
2.SoundStreamのサンプル
以下、ai.googleblog.comより「SoundStream: An End-to-End Neural Audio Codec」の意訳です。元記事の投稿は2021年8月12日、Neil ZeghidourさんとMarco Tagliasacchiさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Kelly Sikkema on Unsplash
音声データの送信中にネットワーク状態が変化する可能性があるため、理想的なコーデックは「ビットレートが可変」であり、ネットワーク状態に応じてビットレートを低から高に変更できる必要があります。ほとんどの従来のコーデックは規模の拡大縮小が可能ですが、従来の学習可能なコーデックは、ビットレート毎に特別にトレーニングおよびモデルを展開する必要があります。
この制限を回避するために、SoundStreamは量子化層の数がビットレートを制御するという事実を活用し、「量子化器ドロップアウト(quantizer dropout)」と呼ばれる新しい方法を提案します。トレーニング中に、さまざまなビットレートをシミュレートするために、いくつかの量子化レイヤーをランダムにドロップします。これにより、デコーダーは着信オーディオストリームの任意のビットレートで適切に動作するようになり、SoundStreamが「規模の拡大縮小が可能」になり、単一のトレーニング済みモデルが任意のビットレートで動作し、これらのビットレート用に特別にトレーニングされたモデルと同様に動作できるようになります。
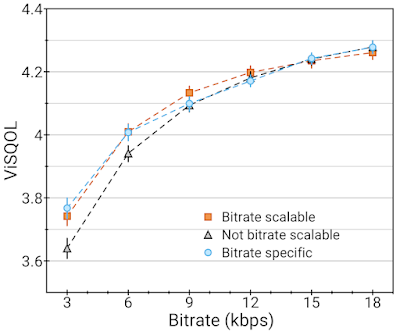
量子化器ドロップアウトあり(ビットレート可変)、量子化器ドロップアウトなし(ビットレート可変ではない)で18 kbpsでトレーニングされたSoundStreamモデルの比較(高いほど良い)。可変数の量子化器で評価されるか、固定ビットレート(ビットレート固有)でトレーニングおよび評価されています。量子化器のドロップアウトのおかげで、ビットレート可変モデル(すべてのビットレートに対して単一のモデル)は、ビットレート固定のモデル(ビットレート毎に異なるモデル)と比較しても品質が下がることはありません。
最先端のオーディオコーデック
3kbpsのSoundStreamは12kbpsのOpusを上回り、9.6 kbpsのEVSの品質に近づきますが、使用するビット数は3.2倍から4倍少なくなります。
つまり、SoundStreamを使用してオーディオをエンコードすると、使用する帯域幅が大幅に少なくなりますが、同程度の品質が得られます。更に、同じビットレートで、SoundStreamは、自己回帰ネットワークに基づく現在のバージョンのLyraよりも優れています。
すでに製品展開され、本番環境での使用に最適化されているLyraとは異なり、SoundStreamはまだ実験段階にあります。将来的には、LyraはSoundStreamのコンポーネントを組み込んで、より高いオーディオ品質と複雑さの軽減の両方を提供する予定です。
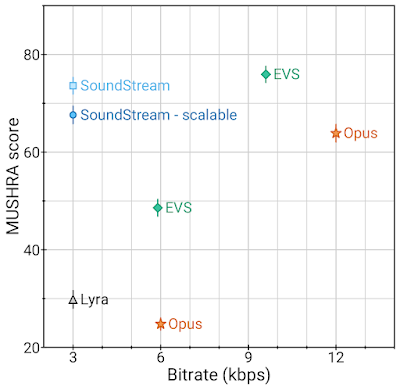
3kbpsのSoundStreamと最先端のコーデック
MUSHRAスコアは主観的な品質を示しています(高いほど良い)
Opus、EVS、およびオリジナルLyraコーデックと比較した上記のSoundStreamのパフォーマンス比較デモで使用したサンプルの一部を以下に示します。
Speech
Reference
Lyra (3kbps)
Opus (6kbps)
EVS (5.9kbps)
SoundStream (3kbps)
Music
Reference
Lyra (3kbps)
Opus (6kbps)
EVS (5.9kbps)
SoundStream (3kbps)
共同オーディオ圧縮と増強
従来のオーディオ処理パイプラインでは、圧縮と増強(enhancement、バックグラウンドノイズの除去)は通常、さまざまなモジュールによって実行されます。
たとえば、オーディオが圧縮される前の送信機側、またはオーディオがデコードされた後の受信機側でオーディオ増強アルゴリズムを適用することができます。このような設定では、個々の処理ステップの遅延が全体の遅延に寄与します。
私達は逆に、全体的な処理時間を増やすことなく、同じモデルで圧縮と増強を一緒に実行できるようにSoundStreamを設計します。次の例では、ノイズ除去を動的にアクティブ化および非アクティブ化することにより、圧縮とバックグラウンドノイズ抑制を組み合わせることができることを示します。(5秒間のノイズ除去なし、5秒間のノイズ除去なし、5秒間のノイズ除去なしなど)
Original noisy audio
Denoised output
Denoised outputでは5秒ごとにノイズ除去のオンとオフを切り替えています。
結論
ビデオのストリーミング再生中であれ、電話会議中であれ、オーディオを送信する必要があるときはいつでも、効率的な圧縮が必要です。SoundStreamは、機械学習主導のオーディオコーデックを改善するための重要なステップです。OpusやEVSなどの最先端のコーデックよりも優れており、オンデマンドでオーディオを増強でき、多数のモデルをリリースする必要はなく単一のビットレード可変モデルのみの展開が必要です。
SoundStreamは、Lyraの次の改良バージョンの一部としてリリースされます。SoundStreamをLyraと統合することにより、開発者は既存のLyra APIとツールを活用して作業を行い、柔軟性と優れた音質の両方を提供できます。また、実験用に別のTensorFlowモデルとしてリリースします。
謝辞
本稿で解説した研究は、Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund そして Marco Tagliasacchiによって実施されました。
Googleの同僚達から受け取った、この作業に関するすべてのディスカッションとフィードバックに感謝します。
3.SoundStream:ビットレート可変なニューラルオーディオコーデック(2/2)関連リンク
1)ai.googleblog.com
SoundStream: An End-to-End Neural Audio Codec
2)arxiv.org
SoundStream: An End-to-End Neural Audio Codec
3)google-research.github.io
Audio samples for “SoundStream: An End-to-End Neural Audio Codec”

