
1.TimeDialとDisfl-QA:時の概念と流暢でない口語表現に対応するためのNLPデータセット(1/2)まとめ
・自然な会話の中には、流暢でない発話の中断、感嘆、繰り返し、再開、訂正などが含まれる
・また会話を理解するには、イベント間の時間的な関係についての推論する知識も必要になる
・時間的常識推論能力を測るTimeDialと文脈不一致に焦点を当てるDisfl-QAデータセットを開発
2.TimeDialとは?
以下、ai.googleblog.comより「Two New Datasets for Conversational NLP: TimeDial and Disfl-QA」の意訳です。元記事は2021年8月4日、Aditya GuptaさんとShyam Upadhyayさんによる投稿です。
真の会話型チャットボット実現には今回のお話のような人間でさえ戸惑いそうな言い回しやGPT-3さえ苦戦するシビアなQAなどに対応可能にならねばなりませんが、BlenderBot 2.0のような最先端のチャットボットが何処まで対応できているのか気になります。
アイキャッチ画像のクレジットはPhoto by Vitolda Klein on Unsplash
自然言語処理(NLP:Natural Language Processing)の重要な課題は、現実世界での発話に固有のさまざまな言語現象を理解して推論できる会話エージェントを構築することです。
たとえば、人々は自分が言おうとしていることを常に正確に計画しているわけではないため、自然な会話の中には、流暢でない発話の中断が含まれることがよくあります。
このような発話の中断は、単純に(感嘆、繰り返し、再開、訂正などで)、文の連続性を壊すだけの場合もあれば、フレーズの根本的な意味が変化する、より複雑な意味を持つ場合もあります。
さらに、会話を理解するには、イベントが別のイベントの前後にあるかどうかなど、時間的な関係についての知識も必要になることがよくあります。ただし、現在のNLPモデルに基づいて構築された会話型エージェントは、時間的な関係や流暢でない発話に直面すると苦労することが多く、パフォーマンスの向上の進捗は遅れています。これは、部分的には、そのような興味深い会話および音声現象を含むデータセットの欠如によるものです。
研究コミュニティ内でこの方向への関心をかき立てるために、対話における時間的常識推論(temporal commonsense reasoning)のためのTimeDialデータセットと、文脈の不一致に焦点を当てたDisfl-QAデータセットを紹介することに興奮しています。
TimeDialは、時間的理解を目的とした新しい「複数選択式の時間概念補完タスク(multiple choice span filling task)」を提示し、約1,100を超える対話の注釈付きテストセットを備えています。
Disfl-QAは、情報探索の設定における文脈の不一致を含む最初のデータセットです。すなわちWikipediaの一節を使った流暢でない質問応答を含む最初のデータセットであり、最大12,000の人間が注釈を付けた流暢でない質問が含まれています。
これらのベンチマークデータセットは、この種の最初のものであり、人間のパフォーマンスと現在の最先端のNLPモデルとの間に大きなギャップがあることを示します。
TimeDialデータセット
人々は、対話内のイベントの期間、頻度、または相対的な順序など、日常の時間的概念について簡単に推論できますが、そのようなタスクは会話エージェントにとって困難な場合があります。例えば、現在のNLPモデルは、推論のための基本レベルの世界知識を前提としている、または会話の順番を超えた時間的概念間の明示的および暗黙的な相互依存性を理解し、知識の空白を埋めるタスクがある場合、選択が不十分になることがよくあります 。
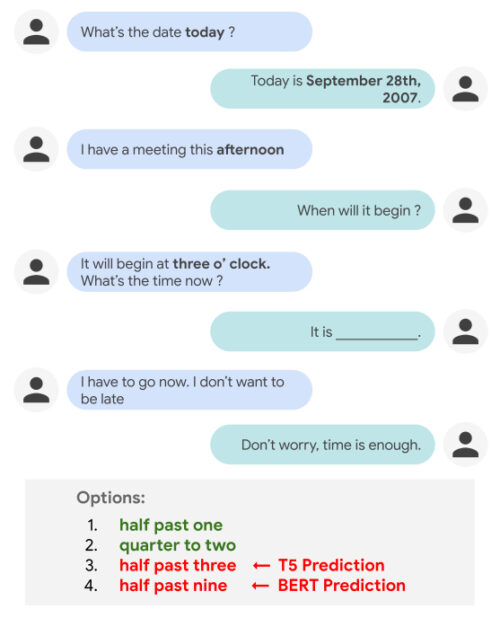
「1時半(half past one)」と「1時45分(quarter to two)」は、「3時半(half past three)」や「9時半(half past nine)」よりも空欄を埋めるのにもっともらしい選択肢であると人間が判断するのは簡単です。
ただし、対話の中でこのような時間的推論を実行することは、NLPモデルにとって簡単ではありません。これは、現実世界の知識を必要とし(つまり、参加者がまだ会議に遅れていないことを知っている)、イベント間の時間的関係(「1時半」は「3時」の前、「3時半」は「後」です)を理解する必要があるためです。実際、T5やBERTのような現在の最先端モデルは、「3時半」(T5)と「9時半」(BERT)という間違った答えを選んでしまいます。
TimeDialベンチマークデータセット(DailyDialog multi-turn dialog corpusから派生)は、対話内のモデルの時間的常識推論能力を測定します。データセット内の約1500の各対話は、回答を複数選択する形式で表示されます。この設定では、時間が一か所空白で隠されており、モデルは4つの選択肢のリストから正解を全て見つけて空白を埋めるように求められます。
私たちの実験では、人間はこれらの多肢選択問題に(97.8%の精度で)簡単に答えることができますが、最先端の事前トレーニング済み言語モデルは依然としてこの課題セットに苦労しています。
3つの異なるモデリングパラダイムで実験をしました。
(i)BERTを使用して4つの選択肢を分類
(ii)BERT-MLMを使用して対話内のマスク部分を充填
(iii)T5を使用した生成手法
全てのモデルがこのチャレンジセットで苦労しており、最高のスコアを出したモデルであっても73%にすぎないことがわかります。
| Model | 2-best Accuracy |
| Human | 97.80% |
| BERT – Classification | 50.00% |
| BERT – Mask Filling | 68.50% |
| T5 – Generation | 73.00% |
定性的エラー分析は、事前にトレーニングされた言語モデルが、文脈に対して真の推論を行うのではなく、浅い、偽の特徴(特にテキストマッチング)に依存することが多いことを示しています。
TimeDialに必要な種類の時間的常識推論を実行できるNLPモデルを構築するには、一般的なテキスト特徴表現内で時間的オブジェクトがどのように特徴表現にされるのかを再考する必要がある可能性があります。
3.TimeDialとDisfl-QA:時の概念と流暢でない口語表現に対応するためのNLPデータセット(1/2)関連リンク
1)ai.googleblog.com
Two New Datasets for Conversational NLP: TimeDial and Disfl-QA
2)arxiv.org
TIMEDIAL: Temporal Commonsense Reasoning in Dialog
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering

