
1.SimGAN:敵対的強化学習を使い正確な物理シミュレータを構築(2/2)まとめ
・GANは現実世界の軌道と区別できない合成軌道を生成するためにも使用できる
・これによりシステム同定を手動ではなくGANを使用して実行する事ができる
・SimGANはドメインのランダム化や直接微調整を上回る性能を発揮した
2.SimGANの性能
以下、ai.googleblog.comより「Learning an Accurate Physics Simulator via Adversarial Reinforcement Learning」の意訳です。元記事の投稿は2021年6月16日、Yifeng JiangさんとJie Tanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Rob Lambert on Unsplash
シミュレータを学習させるためにGANを使用
前述のシミュレーションパラメータ関数の学習に成功すると、実際のロボットで収集されたものと同様の軌道を生成できるハイブリッドシミュレータが得られます。
この学習を可能にする鍵は、軌道間の類似性の指標を定義することです。GANは、発表当初は同じ分布または「スタイル」を共有する合成画像を少数の実画像から生成する目的で使われていました。しかし、GANは現実世界の軌道と区別できない合成軌道を生成するためにも使用できます。
GANには、新しい実体を生成する事を学習するジェネレーターと、新しい実体がトレーニングデータにどの程度類似しているかを評価するディスクリミネーターの2つの主要部分があります。この場合、学習可能なハイブリッドシミュレーターはGANジェネレーターとして機能し、GANディスクリミネーターは類似性スコアを提供します。
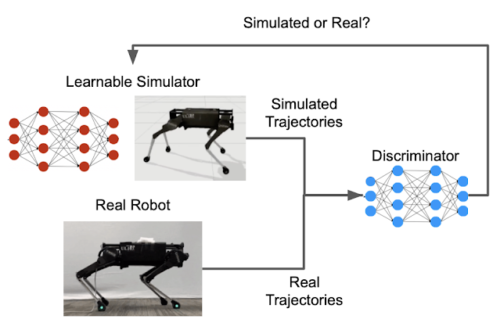
GANディスクリミネーターは、シミュレーション内のロボットと現実世界のロボットの動きを比較する類似性指標を提供します。
シミュレーションモデルのパラメータを実世界で収集されたデータに適合させることは、システム同定(SysID:System Identification)と呼ばれるプロセスであり、多くの工学分野で一般的に行われています。たとえば、変形可能な表面の剛性パラメータは、さまざまな圧力下での表面の変位を測定することで特定できます。このプロセスは通常、手動で行うには面倒ですが、GANを使用するとはるかに効率的になります。
たとえば、SysIDは、シミュレートされた軌道と実際の軌道の間の不一致について、手動設計した指標を必要とすることがよくあります。GANを使用すると、このような指標はディスクリミネーターによって自動的に学習されます。
さらに、不一致指標を計算するためには、従来のSysIDでは、シミュレートされた各軌道を、同じ制御ポリシーを使用して生成された対応する実際の軌道とペアリングする必要があります。GANのディスクリミネーターは、入力として1つの軌道のみを取り、それが実世界で収集された可能性を計算するため、この1対1のペアリングを行う必要はありません。
強化学習を使用してシミュレーターを学習し、ポリシーを改善
すべてをまとめて、シミュレーション学習を強化学習(RL:Reinforcement Learning)問題として定式化します。ニューラルネットワークは、少数の実世界の軌道から状態に依存する接触と運動のパラメーターを学習します。このニューラルネットワークは、シミュレートされた軌道と実際の軌道の間の誤差を最小限に抑えるように最適化されています。
長期間にわたってこのエラーを最小限に抑えることが重要であることに注意してください。より遠い未来を正確に予測するシミュレーションは、より良い制御ポリシーにつながります。RLは、シングルステップの報酬を最適化するだけでなく、時間の経過とともに蓄積された報酬を最適化するため、これに非常に適しています。
ハイブリッドシミュレーターが学習され、より正確になった後、RLを再度使用して、シミュレーション内でロボットの制御ポリシーを調整します。(たとえば、以下に示すように、地表を歩く)
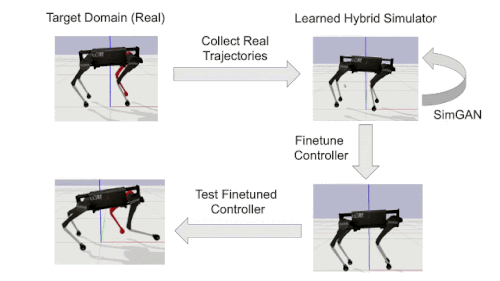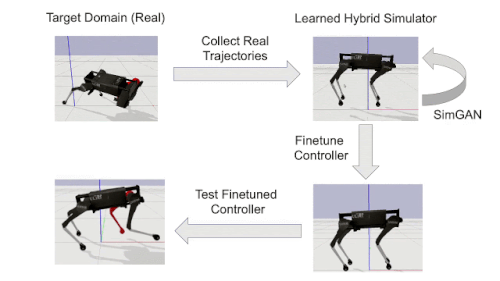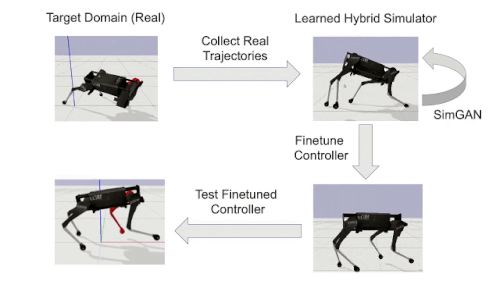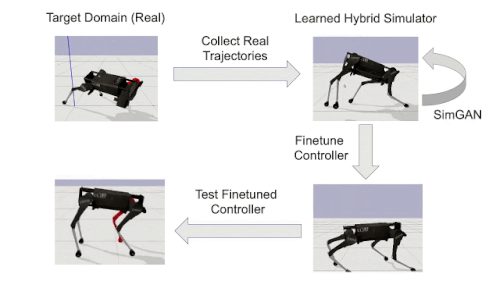
時計回りに矢印に沿った解説
(左上)ターゲットドメインで失敗するロボットの少数の試行を記録します。(たとえば、赤い脚が非常に重くなるように変更して)
(右上)ターゲットドメインで収集した軌道に一致するようにハイブリッドシミュレーターを学習
(右下)学習したシミュレーターで制御ポリシーを調整
(左下)ターゲットドメインで直接、洗練されたコントローラーをテスト
SimGANの評価
2020年は新型コロナウイルスのため現実世界のロボットを使うために出社する事が制限されており、現実世界の代替として2番目の異なるシミュレーション(ターゲットドメイン)を作成しました。
ソースドメインとターゲットドメイン間の違いは、さまざまなシミュレーションと現実世界のギャップを概算するのに十分な大きさです。(たとえば、片足を重くしたり、硬い床ではなく変形可能な表面を歩いたりさせます)
これらの変更についての知識を持たないハイブリッドシミュレーターが、ターゲットドメインのダイナミクスに一致することを学習できるかどうか、およびこの学習したシミュレーターの洗練されたポリシーをターゲットドメインに正常に展開できるかどうかを評価しました。

ホッパーと4脚ロボットのターゲットドメイン(変形可能なフロア)での初期ポリシーと洗練されたポリシーのパフォーマンスの比較
以下の定量的な結果は、SimGANが、ドメインのランダム化(DR:domain randomization)やターゲットドメインでの直接微調整(FT:finetuning in target domains)など、複数の最先端の比較対象基準よりも優れていることを示しています。
4脚ロボットの3つの異なるターゲットドメインでの異なるsim-to-realへの転移方法を使用したポリシーパフォーマンスの比較。変形可能な表面での移動、モーターの弱体化、およびボディの重量増加の3パターンの比較
結論
シミュレーションと現実世界のギャップは、ロボットが強化学習の力を利用することを妨げる主要なボトルネックの1つです。少量の実世界データのみを使用しながら、実世界のダイナミクスをより忠実にモデル化できるシミュレーターを学習することで、この課題に取り組んでいます。
このシミュレーターで改良された制御ポリシーは、正常に展開できます。これを実現するために、学習可能なコンポーネントで古典物理シミュレーターを拡張し、敵対的強化学習を使用してこのハイブリッドシミュレーターをトレーニングします。
これまで、移動タスクへの適用をテストしてきましたが、このフレームワークを案内タスクや操縦タスクなどの他のロボット学習タスクに適用することで、汎用的なフレームワークを構築したいと考えています。
謝辞
論文の共著者であるTingnan Zhang, Daniel Ho, Yunfei Bai, C. Karen Liu, そして Sergey Levineに感謝します。また、GoogleのRoboticsのチームメンバーの議論とフィードバックにも感謝します。
3.SimGAN:敵対的強化学習を使い正確な物理シミュレータを構築(2/2)関連リンク
1)ai.googleblog.com
Learning an Accurate Physics Simulator via Adversarial Reinforcement Learning
2)arxiv.org
SimGAN: Hybrid Simulator Identification for Domain Adaptation via Adversarial Reinforcement Learning

