
1.FRILL:TensorFlow-Liteを使用したオンデバイスで動作可能な音声特徴表現(1/2)まとめ
・昨年、音声の特徴表現を比較するベンチマークと新しい音声特徴表現モデルTRILLを公開
・TRILLは有用だが単純な音声特徴を処理する信号処理操作よりも多くのメモリを必要とする
・FRILLはTRILLを教師に知識蒸留した生徒モデルでオンデバイスで高速動作可能なモデル
2.FRILLとは?
以下、ai.googleblog.comより「FRILL: On-Device Speech Representations using TensorFlow-Lite」の意訳です。元記事は2021年6月10日、Joel ShorさんとSachin Joglekarさんによる投稿です。
Joel ShorさんはGoogle Research Tokyoの人だそうです。
FRILLは、フリル。洋服などの端につけるひだ飾りで、これもフリルで良いのかな、とやや迷いながら選んだアイキャッチ画像のクレジットはPhoto by Michael Afonso on Unsplash
特徴表現学習(Representation learning)は、自然言語処理(BERTやALBERTなど)から画像分析や画像分類(InceptionレイヤーやSimCLRなど)に至るまで、様々な下流工程タスクに適用できる顕著な特徴を特定するためにモデルをトレーニングする機械学習(ML:Machine Learning)手法です。
昨年、音声の特徴表現を比較するためのベンチマークと、一般的に有用な新しい音声特徴表現モデル(TRILL:TRIpLet Loss network)を紹介しました。
TRILLは時間的近接性(temporal proximity)に基づいています。そして、時間的に近接して発生する音声を、embedding空間で時間的近接性を捕捉するために低次元のembeddingにマッピングしようとします。リリース以来、研究コミュニティは、年齢分類、ビデオサムネイルの選択、言語識別など、さまざまなタスクにTRILLを使用してきました。ただし、最先端のパフォーマンスを実現しているにもかかわらず、TRILLやその他のニューラルネットワークベースのアプローチは、ラウドネス、平均エネルギー、ピッチなどの単純な音声特徴を処理する信号処理操作よりも多くのメモリを必要とし、計算に時間がかかります。
Interspeech 2021に掲載される直近の論文「FRILL: A Non-Semantic Speech Embedding for Mobile Devices」では、TRILLの40%のサイズで、32倍以上高速に計算できる特徴セットを作成します。スマートフォン上で実行した際の平均低下精度は2%未満です。
これは、音声MLモデルの完全なオンデバイスアプリケーションに向けた重要なステップであり、AIの責任ある開発の重要な側面である、個々人の音声に最適化する能力の向上、ユーザーエクスペリエンスの向上、プライバシーの向上につながります。githubでFRILLを作成するためのコードと、TensorFlow Hubで事前トレーニングされたFRILLモデルをリリースします。
FRILL:小さく、高速なTRILL
TRILLアーキテクチャは、ResNet50の修正バージョンに基づいています。これは、携帯電話やスマートホームデバイスなどの制約のあるハードウェアに対して計算上の負担がかかるアーキテクチャです。一方、MobileNetV3のようなアーキテクチャは、ハードウェア対応のAutoMLを使用して設計されており、モバイルデバイスで適切に機能します。これを活用するために、知識蒸留(knowledge distillation)を活用して、MobileNetV3のパフォーマンスの利点とTRILLの表現を組み合わせています。
蒸留手法では、AudioSetデータセットを使って大きいモデル(教師:teacher)を学習させた後、小さいモデル(つまり、生徒:student)を大きいモデルの出力と一致させるように学習させます。
元のTRILLモデルは、時間的に近いオーディオの断片をクラスタでまとめる自己教師あり損失を最適化することで重みを学習しましたが、生徒モデルは、時間的マッチングを無視し、代わりにトレーニングデータのTRILL出力と一致させようとする完全教師あり損失を通じて重みを学習します。 完全教師あり学習信号は、多くの場合、自己教師あり学習よりも強力であり、より迅速にトレーニングすることができます。
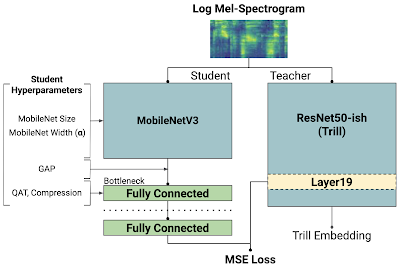
非意味的音声embeddingsのための知識蒸留
破線は生徒モデルの出力を示しています。「教師ネットワーク」はTRILLネットワークであり、「レイヤー19」が最もパフォーマンスの高い内部特徴表現でした。左側の「Student Hyperparameters」は、本研究で調査した選択肢であり144の異なるモデルです。これらのモデルは、TRILLのレイヤー19と一致するように、平均二乗誤差(MSE:Mean-Squared Error)でトレーニングされました。
最高の生徒モデルの選択
さまざまな生徒モデルを使用して蒸留を実行します。各モデルは、特定のアーキテクチャの組み合わせでトレーニングされています。(以下で説明します)
各生徒モデルの応答速度を測定するために、エッジデバイス上でTensorFlowモデルの実行を可能にするフレームワークであるTensorFlow Lite(TFLite)を活用します。
各候補モデルは、最初に32ビット浮動小数点推論用にTFLiteのflatbuffer形式に変換され、次にベンチマークのためにターゲットデバイス(この場合はPixel 1スマートフォン)に送信されます。これらの測定値は、すべての生徒モデルにおける遅延と品質のトレードオフを正確に評価し、変換プロセスでの品質の低下を最小限に抑えるのに役立ちます。
3.FRILL:TensorFlow-Liteを使用したオンデバイスで動作可能な音声特徴表現(1/2)関連リンク
1)ai.googleblog.com
FRILL: On-Device Speech Representations using TensorFlow-Lite
2)arxiv.org
FRILL: A Non-Semantic Speech Embedding for Mobile Devices
3)github.com
google-research/non_semantic_speech_benchmark/distillation/
4)tfhub.dev
nonsemantic-speech-benchmark/frill
