
1.XMC-GAN:クロスモーダルな対照学習でテキストから画像を生成(2/2)まとめ
・XMC-GAN は各データセットで最先端のスコアを実現し他の手法より評価者に好まれた
・特により複雑なOpenImagesでもXMC-GAN は高品質の結果を生成できた。
・XMC-GANは自然言語の記述から画像を生成するアプリケーションに向けた大きな進歩
2.XMC-GANの性能
以下、ai.googleblog.comより「Cross-Modal Contrastive Learning for Text-to-Image Generation」の意訳です。元記事の投稿は2021年5月26日、Han ZhangさんとJing Yu Kohさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Mohamed Nohassi on Unsplash
評価結果
XMC-GANを3つの難しいデータセットに適用しました。
最初のものは MS-COCO画像データセット内のMS-COCO descriptionsコレクションであり、他の 2 つはLocalized Narrativesで注釈が付けられたデータセットであり、そのうちの 1 つは MS-COCO 画像にLocalized Narrativesを付与したデータセット(これを LN-COCO と呼びます)で、もう 1 つは OpenImage DatasetについてLocalized Narrativesを付与したデータセット(LN-OpenImages)です。
XMC-GAN は、それぞれに新しい最先端のスコアを実現していることがわかります。XMC-GANによって生成された画像は、他の手法を使用して生成されたものよりも高品質な風景を示しています。MS-COCOでは、XMC-GANは最先端のフレシェインセプション距離(FID:Fréchet inception distance)スコアを24.7から9.3に改善し、人間の評価者に非常に好まれています。

MS-COCO で生成された画像から選択した定性的結果
同様に、人間の評価者は、XMC-GANで生成された画像の画質を77.3%の確率で好みました。
また、74.1%が他の 3 つの最先端のアプローチ(CP-GAN、SD-GAN、 および OP-GAN)よりXMC-GANを好みました。
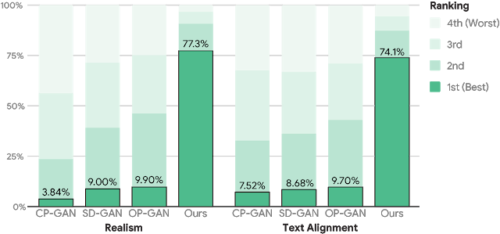
画質とテキストの配置に関する MS-COCO の人間による評価。
評価者は、生成された画像を最高から最低までランク付け(匿名化および順序ランダム化)して評価しています。
XMC-GAN は、より長くより詳細な説明を含む、難しい Localized Narratives データセットにも適切に一般化します。私達の以前の研究 TReCS は、画像生成の品質を向上させるために、マウス トレース入力を使用してローカライズされたナラティブのテキストから画像への生成に取り組んでいます。
マウス トレース アノテーションを受け取っていないにもかかわらず、XMC-GAN は LN-COCO での画像生成で TReCS を大幅に上回り、最先端の FID を 48.7 から 14.1 に向上させることができます。マウス トレースやその他の追加入力を XMC-GAN などのエンド ツー エンド モデルに組み込むことは、将来の研究で興味深いものになるでしょう。
さらに、LN-OpenImages でのトレーニングと評価も行いました。これは、データセットがはるかに大きく、より幅広い主題をカバーし、より複雑な画像 (1画像内に平均 8.4 個の物体が含まれる)なため、MS-COCO よりも困難です。私たちの知る限り、XMC-GAN は Open Images でトレーニングおよび評価された最初のテキストから画像への合成モデルです。 XMC-GAN は高品質の結果を生成でき、この非常に困難なタスクで 26.9 という強力なベンチマーク FID スコアを設定します。

Open Images 上の実際の画像と生成された画像のランダム サンプル
結論と今後の課題
本研究では、テキストから画像を合成するGAN モデルをトレーニングするためのクロスモーダル対照学習フレームワークを紹介しました。画像とテキストの間の対応を強制するいくつかのクロスモーダル対照的な損失を調査しました。XMC-GAN は、人間による評価と定量的な評価基準の両方で顕著な改善を確立しました。複数のデータセットと従来モデルの比較でこれを確かめました。
長くて詳細な説明を含め、入力の説明によく一致する高品質の画像を生成し、よりシンプルで直接実行可能なモデルです。これは、自然言語の記述から画像を生成するためのクリエイティブなアプリケーションに向けた大きな進歩であると考えています。この調査を続ける中で、私たちは AI の原則に従って、責任あるアプローチ、潜在的なアプリケーション、リスクの軽減を継続的に評価しています。
謝辞
本研究は Jason Baldridge, Honglak Lee, そして Yinfei Yang との共同作品です。有益なフィードバックをいただいたKevin Murphy, Zizhao Zhang, Dilip Krishnanに感謝します。また、人間による評価を実施してくださった Google データ コンピューティング チームにも感謝いたします。
また、Google Research チームからの総合的なサポートにも感謝しています。
3.XMC-GAN:クロスモーダルな対照学習でテキストから画像を生成(2/2)関連リンク
1)ai.googleblog.com
Cross-Modal Contrastive Learning for Text-to-Image Generation
2)arxiv.org
Cross-Modal Contrastive Learning for Text-to-Image Generation
3)magenta.tensorflow.org
Magenta

