
1.Crisscrossed Captions:画像とテキストの意味的類似性の探求(3/3)まとめ
・文対文タスクと画像対文タスクでトレーニングされたマルチタスクモデルが最も優秀だった
・文対文のトレーニングを追加すると画像対文、文対画像でパフォーマンスが向上した
・CxCで異なる形式間および同じ形式内の特徴表現を学習する優れたモデルの研究が推進される
2.Crisscrossed Captionsの評価
以下、ai.googleblog.comより「Crisscrossed Captions: Semantic Similarity for Images and Text」の意訳です。元記事の投稿は2021年5月6日、Zarana ParekhさんとJason Baldridgeさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Robert Bye on Unsplash
CxCを使った評価
MS-COCOは、次の3つの検索タスクをサポートしています。
・画像を指定して、評価セット内の他のキャプションから一致するキャプションを見つける検索
・キャプションを指定して、評価セット内の他の画像から対応する画像を見つける検索
・キャプションを指定して、評価セット内の他のキャプションのコキャプションを見つける検索
MS-COCOのペアは不完全です。ある画像に対して作成されたキャプションが時には別の画像にも適用される場合があるのですが、これらの関連性はデータセット内で補足されていません。
CxCは、これらの既存の検索タスク向けに新しく有効なペアを設定して強化し、画像を使って画像を検索するタスクも新たにサポートします。
CxCは、段階的に類似性をスコア付けしているため、モデルが付与するランキングと人間が付与するランキング間の相関を測定することもできます。
一般に、類似性検索の指標は類似性スコアが高いペアのみに焦点を当てていますが、CxCの相関スコアは、類似性の相対的な順序を考慮しているため、類似性スコアが低いアイテム(不一致)も含みます。
画像とキャプションを共通セットとして使用してこれらの評価を行うと、キャプション対画像、キャプション対キャプション、および画像対画像をそれぞれ単体の関連付けとして使った場合と比較して、異なった形式間(inter-modal)を対象とする学習における価値が高まります。
CxCを使った評価の有用性を示すために、一連の実験を実行しました。
テキストエンコーダーとしてBERT-baseを使用し、画像エンコーダーとしてEfficientNet-B4を使用して、3つのデュアルエンコーダー(DE)モデルを構築しました。
・両側に共有テキストエンコーダーを使用するテキスト対テキスト(DE_T2T)モデル
・前述のテキストエンコーダーと画像エンコーダーを使用し、画像エンコーダーの出力と一致するようにテキストエンコーダーの上にレイヤーを含む画像対テキストモデル(DE_I2T)
・テキスト対テキストタスクと画像対テキストタスクの重み付けされた組み合わせでトレーニングされたマルチタスクモデル(DE_I2T + T2T)
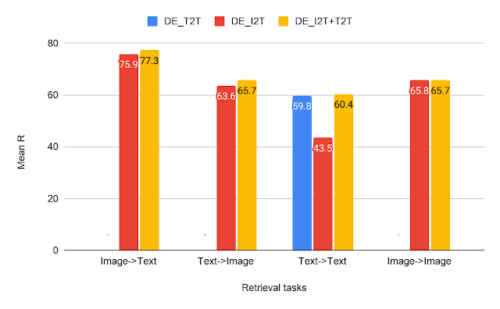
CxC検索結果
4つの検索タスクすべてにおけるテキスト対テキスト(T2T)、画像対テキスト(I2T)、およびマルチタスク(I2T + T2T)デュアルエンコーダーモデルの比較
検索タスクの結果から、画像対テキストおよびテキスト対画像検索タスクでは、DE_I2T + T2T(黄色のバー)の方がDE_I2T(赤いバー)よりもパフォーマンスが高いことがわかります。
従って同形式内(テキスト対テキスト)トレーニングタスクを追加すると、異なった形式間(画像対テキスト、テキスト対画像)のパフォーマンスが向上しました。
他の2つの同形式内タスク(テキスト対テキストとイメージ対イメージ)に関しては、DE_I2T + T2Tは両方で強力でバランスの取れたパフォーマンスを示しています。
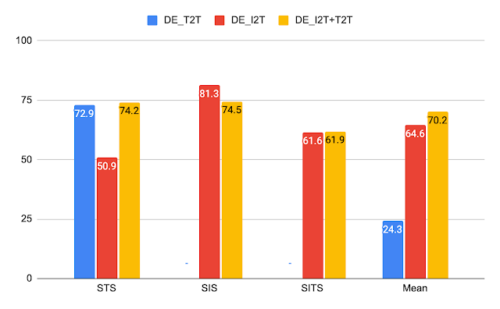
前述のモデルと同じモデルのCxC相関結果
相関タスクの場合、DE_I2TはSIS(Semantic Image Similarity)で最高のパフォーマンスを発揮し、DE_I2T + T2Tは全体的に最高のパフォーマンスを発揮します。
相関スコアは、DE_I2Tが画像でのみ良好に機能することも示しています。SISでは最高スコアですが、STS(Semantic Text Similarity)スコアでははるかに劣っています。テキスト-テキスト損失をDE_I2Tトレーニング(DE_I2T + T2T)に追加すると、全体的なパフォーマンスのバランスが向上します。
CxCデータセットは、オリジナルのMS-COCO画像とキャプションのペアよりも、画像とキャプション間関係の完全なセットを提供します。新しい評価もリリースされており、詳細は論文に記載されています。
私達は、CxCによって可能になった新たなタスクについて最先端を推進することを研究コミュニティに奨励したいと考えています。CxCにより異なる形式間および同じ形式内の特徴表現を共同で学習する優れたモデルの研究を推進する事ができます。
謝辞
コアチームには、Daniel Cer, Yinfei Yang, Austin Watersが含まれます。CxCの定式化に関する情報を提供してくれたJulia Hockenmaierに感謝します。Googleデータコンピューティングチーム、特にツールとアノテーションのサポートを提供してくれたAshwin KakarlaとMohd Majeedに感謝します。Yuan ZhangとEugene Ieは論文の初期バージョンについてコメントをくれました。
Daphne Luongはデータ収集に関して重大なサポートを提供してくれました。
3.Crisscrossed Captions:画像とテキストの意味的類似性の探求(3/3)関連リンク
1)ai.googleblog.com
Crisscrossed Captions: Semantic Similarity for Images and Text
2)www.aclweb.org
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
3)github.com
google-research-datasets / Crisscrossed-Captions
