
1.HPP:ロボット同士が待ち合わせできるようにするモデルベース強化学習(2/3)まとめ
・システムは予測、計画、および制御の3つのモジュールから構成されている
・各エージェントは自分自身の動き用と他のエージェント用の予測モデルを学習
・予測を使って計画モジュールが落ち合う場所の確信分布を作って誘導を行う
2.HPPのトレーニング
以下、ai.googleblog.comより「Model-Based RL for Decentralized Multi-agent Navigation」の意訳です。元記事の投稿は2021年4月28日、Rose E. WangさんとAleksandra Faustさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Matthieu Collin on Unsplash。
予測、計画、および制御の統合
標準的な誘導パイプラインと同様に、学習ベースのシステムは3つのモジュールから構成されています。予測(prediction)、計画(planning)、および制御(control)です。
各エージェントは、予測モデルを使用して、エージェントの動きを学習し、自分自身(ego-agent)および他のエージェントの将来の位置を独自の観察(リモートセンシング技術のLiDARやチームの位置情報など)やナビゲーションパターンに基いて予測します。
従って、各エージェントは2つの予測モデルを学習します。1つは自分自身の動き用で、もう1つは他のエージェント用です。これらのモーション予測器は予測モジュールを構成し、各エージェントの計画モジュールによって使用されます。
予測モジュールの出力(つまり各エージェントの場所の推定)は計画モジュールにとって有用な情報です。ego-agentと他のエージェントの両方に、ego-agent自身のセンサー観測が使われる可能性が最も高く、これは、さまざまな目標位置を評価し、チームが落ち合う可能性のある全ての目標位置に確信分布(belief distribution)を維持します
確信分布は、予測モデルによって提供される評価を使用して定期的に更新されます。エージェントは、この確信分布からサンプリングして、誘導する必要のある目標位置を更新します。
選択された目標位置は、エージェントの制御モジュールに渡されます。制御モジュールには、障害物が多い環境の特定の場所に移動できる、事前にトレーニングされた不完全なナビゲーションポリシーが実装されています。次に、制御ポリシーによって、ロボットが実行するアクションが決定されます。
他のエージェントを観察し、確信分布を更新し、更新された目標位置に誘導するこのプロセスは、エージェントが正常に落ち合うまで繰り返されます。
階層的な計画と制御を使う事は珍しいことではありませんが、私達の研究は、センサー情報に基づく予測モジュールを使用して、分散型マルチエージェントシステムの制御と計画の間のコミュニケーションを循環させます。
予測モデルのトレーニング
HPPは、各エージェントが障害物を回避できる隠された、おそらく最適ではない制御ポリシーによって制御されていると仮定して、シミュレーションでモーション予測器をトレーニングします。主な問題は、他のエージェントのセンサー観測と制御ポリシーにアクセスせずに予測モデルをトレーニングすることにあります。
予測器は、自己教師によってトレーニングされます。トレーニングデータを収集するために、全てのエージェントと障害物を環境内にランダムに配置し、各エージェントにランダムな目標(他のエージェントからは不明)を与えます。
エージェントがそれぞれの目標に向かって進むと、各エージェントは経験を記録します。ここでいう経験は、センサーを使った観察と全てのエージェント(自分自身と他のエージェント)のポーズです。
次に、記録された経験から、エージェントは、自分自身を含むチーム内のエージェント(target agent)毎に個別の予測器を学習します。
トレーニングデータセットは、ego-agentの初期センサー観測、つまりtarget agentのポーズと目標で構成され、将来のエゴ観測とtarget agentのポーズでラベル付けされています。目標位置とラベルは、記録された経験から推測されます。
その結果、予測器は、target agentの想定される目標位置を条件として、現在および将来のego-agentの観察とtarget agentのポーズの時間的因果関係を学習します。
言い換えれば、モデルは、現在に基づいて各エージェントが将来どこにいるかを予測します。予測器のトレーニングには、実行時にエージェントが利用できる情報のみが使用されます。そのため、特定の環境に依存せず、様々な環境で実行できます。
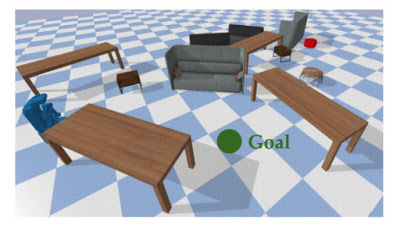
モデル予測モデルのトレーニング環境
環境はランダムに満たされた障害物で満たされています。すべてのエージェント(左部の青、右上の赤)に同じランダムな目標(中央の緑)が与えられ、独自の制御モジュールを使用してそれに向かって移動します。
3.HPP:ロボット同士が待ち合わせできるようにするモデルベース強化学習(2/3)関連リンク
1)ai.googleblog.com
Model-Based RL for Decentralized Multi-agent Navigation
2)arxiv.org
Model-based Reinforcement Learning for Decentralized Multiagent Rendezvous
