
1.GoogleはAI開発競争における防壁を持っていません!OpenAIもです!まとめ
・Google社内から流出したとされる文章がGoogleはOpen Sourceの取り組みからもっと学ぶべきという趣旨を主張していた
・Googleが巨費をかけた大規模モデルで苦戦していることを100ドルと130億パラメータと数週間で実現しているとの事
・イラスト生成AIで起こったカスタマイズしたモデルの流行は大規模言語モデル界隈でも起こっていく可能性はあるかもしれない
2.AI開発競争における競争優位性とは?
以下、www.semianalysis.comより「Google “We Have No Moat, And Neither Does OpenAI”」の意訳です。私はhardmaruさんのTwitterで知りましたが、Google社内文章の流出とされています。一部報道によれば執筆者の方も既に特定されているようですが特に公式のコメントはないようです。後半の時系列の部分が大企業の中の人から見るとそんな風に見えているのかと特に面白い所です。
アイキャッチ画像は防壁(Moat)のない城とそれを防衛する人
私たちはOpenAIを気にかけながら、どちらが次のマイルストーンを達成するのか、次の一手は何かを予測してきました。
しかし、厳しい現実は、私たちもOpenAIもこの競争に勝てる立場にないことです。争っている間に、第三勢力がこっそりと私たちのシェアを奪っています。
もちろん、オープンソースのことを話しています。はっきり言って、私たちに圧勝しています。私たちが「重要なオープンな問題(major open problems)」と考えていることは、すでに解決され、人々の手に行き渡っています。いくつか例を挙げると、
・LLM(大規模言語モデル)をスマートフォンで動かす
Pixel 6で基盤モデルが5トークン/秒で動作しています。
・規模拡大可能な個人用AI
一晩でノートパソコンで個人向けAIを微調整できます。
・責任あるリリース
これは「解決した」というより「無関係になった」ものです。制限が一切ないイラスト生成モデルが満載のウェブサイトがあり、テキスト生成モデルもそれに続くでしょう。
・マルチモーダリティ
マルチモーダル能力を試されるScienceQAの最先端スコアを出したモデルは1時間で学習されました。
私たちのモデルはまだわずかに品質面で優れていますが、その差は驚くほど速く縮まっています。オープンソースのモデルは、速く、カスタマイズ可能で、プライバシーが高く、そして能力があります。彼らは、私たちが1000万ドルをかけた5400億パラメータのモデルで苦戦していることを、100ドルと130億パラメータで実現しています。そして、それを数か月ではなく数週間でやってのけます。これは私たちにとって重大な意味を持ちます。
・私達は誰も真似できない秘伝のタレを持っているわけではありません。私たちの最善の希望は、Googleの外で他の人がやっていることから学び、協力することです。第三者との連携を優先すべきです。
・品質が同等で無料で制限のない代替品がある場合、人々は制限のあるモデルにお金を払いません。私たちが実際に価値を付加している場所を検討すべきです。
・巨大なモデルは私たちの動きを遅くしています。長期的には、素早く反復できるモデルが最善です。
200億パラメータ未満のモデルで可能なことがわかったので、小さなモデルのバリエーションを作る事を後回しにせず、真剣に取り組むべきです。
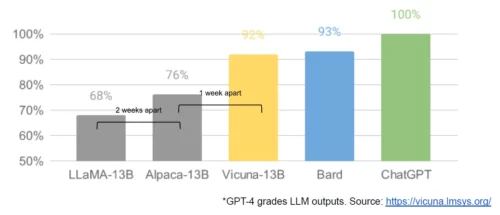
[lmsys.org/blog/2023-03-30-vicuna/] より引用
何が起こったのか
3月初めに、オープンソースコミュニティは、Meta社がLLaMAを公開した事により、初めて実用的な基盤モデルを手に入れました。そのモデルは指示調整(instruction tuning)や会話調整(conversation tuning)がなく、人間のフィードバックを使った強化学習(RLHF)も行われていませんでした。それでも、コミュニティはすぐに彼らが手に入れたものの意義を理解しました。
素晴らしい革新が続出し、主要な開発の間にわずかな日数しかありませんでした。(詳細は後述の時系列を参照してください)。それからほんの1か月後の今、指示調整、量子化(quantization)、品質の向上、人間による評価、マルチモーダル、RLHFなど、相互に構築された多くの変種が存在しています。
最も重要なことは、誰もが改良できる程度に規模の問題を解決していることです。新しいアイデアの多くは一般の人々から来ています。トレーニングや実験を行う際の参入障壁は下がりました。大規模な研究組織が総力を結集せずとも、1人が1晩でそして高性能なノートパソコン上で行う事ができます。
これが予想できた理由
多くの点で、これは誰にとっても驚きではないはずです。オープンソースのLLMにおける現在のルネッサンスは、画像生成のルネッサンスが先駆けとなっています。コミュニティはこの類似性を見逃しておらず、多くの人々がこれをLLMの「Stable Diffusionが公開された瞬間」と呼んでいます。
どちらの場合も、低ランク適応(LoRA:Low Rank Adaptation)と呼ばれる大幅に安価な微調整の仕組みと、規模を拡大する上での重要なブレークスルー(画像合成用のlatent diffusion、LLM用のChinchilla)によって、低コストで広く参入が可能となりました。どちらの場合も、十分に高品質なモデルへのアクセスが、世界中の個人や機関からのアイデアと反復の続々とした展開を引き起こしました。どちらの場合も、これは大手企業を迅速に凌駕しました。
これらの貢献は、画像生成の分野で重要な役割を果たし、 Stable DiffusionをDall-Eとは異なる道へと導きました。オープンなモデルを持つことで、Dall-Eでは実現しなかった製品の統合、マーケットプレイス、ユーザーインターフェース、イノベーションが生まれました。
その効果は明白であり、文化的影響において急速な支配が見られ、OpenAIのソリューションはますます無関係となりました。LLMについても同じことが起こるかどうかはまだ分かりませんが、広範な構造要素は同じです。
私たちが見落としていたもの
オープンソースの最近の成功の原動力となった技術革新は、私たちがまだ苦しんでいる問題を直接解決しています。彼らの仕事にもっと注意を払うことで、車輪の再発明を避けることができるかもしれません。
LoRAは、私たちがもっと注意を払うべき、信じられないほど強力な技術です
LoRAは、モデルの更新を低ランクの因数分解として表現することで、更新行列のサイズを最大で数千分の一に削減します。これにより、わずかなコストと時間でモデルの微調整が可能になります。一般消費者向けハードウェアで数時間以内に言語モデルをパーソナライズできるようになることは、特に、新しい多様な知識をほぼリアルタイムで取り込むことを目指す場合、大きな意味を持ちます。
この技術は、Googleの最も野心的なプロジェクトに直接影響を与えるにもかかわらず、Google内部で十分に活用されていません。
モデルをゼロから再トレーニングするのは困難な道です
LoRAが効果的なのは、他の微調整同様、積み重ねが可能な点です。指示調整のような改良を施し、他の貢献者が対話、推論、ツールの使用などを追加する際に活用することができるのです。個々の微調整は低ランクなものであったとしても、その合計が低ランクである必要はなく、時間の経過とともにフルランクのモデルにアップデートが蓄積されます。
つまり、より良いデータセットやタスクが利用できるようになれば、完全に調整をやりなす事なく、安価にモデルを最新に保つことができるのです。
これに対して、巨大なモデルをゼロからトレーニングすると、事前トレーニングだけでなく、その上で行われた反復的な改善も捨ててしまうことになります。オープンソースの世界では、このような改良が主流になるまでに時間はかかりませんでした。完全な再トレーニングは非常にコストがかかるからです。
新しいアプリケーションやアイデアが、本当に全く新しいモデルを必要とするのかどうか、よく考える必要があります。もし、モデルの重みを直接再利用できないような大きなアーキテクチャの改良が本当にあるのなら、前世代の機能をできるだけ多く保持できるような、より積極的な蒸留(distillation )の形態に投資すべきです。
小さなモデルでより速く反復できるのであれば、大きなモデルの方が能力が高いとは長期的には言えない
LoRAのアップデートは、最も一般的なモデルサイズで非常に安く(~100ドル)作成することができます。
つまり、アイデアさえあれば、ほとんど誰でもアップデートを作成し、配布することができるのです。トレーニング時間は1日以内が普通です。このペースなら、微調整の積み重ねが、サイズのハンデを克服するのにそれほど時間はかからないでしょう。
実際、エンジニアの工数という点では、これらのモデルによる改善のペースは、私たちの最大のバリエーションでできることを大きく上回っており、最高のものはすでにChatGPTとほとんど見分けがつかないほどになっています。地球上で最も大きなモデルを維持することに集中することは、実は私たちを不利な立場に追いやることになります。
データサイズよりもデータクオリティの方がモデルの品質が向上する
これらのプロジェクトの多くは、小規模で高度にまとめられたデータセットでトレーニングすることで時間を節約しています。
これは、データのスケーリング法則にある程度の柔軟性があることを示唆しています。
このようなデータセットの存在は「より大きなデータセットが常に良い結果をもたらす」という従来の仮定が、必ずしも真実ではない可能性があります。Google以外でもトレーニングを行う際の標準的な方法として急速に普及しています。これらのデータセットは、合成的な方法(例えば、既存のモデルから最良の応答をフィルタリングする)や他のプロジェクトからの拾い物を使って構築されており、どちらもGoogleでは主流ではありません。幸いなことに、これらの高品質なデータセットはオープンソースであるため、無料で利用することができます。
オープンソースと直接競合するのは負け組
この最近の進展は、私たちのビジネス戦略に直接的、即座に影響を与えるものです。利用制限のない無料の高品質な代替品があれば、誰が利用制限のあるGoogle製品にお金を払うでしょうか?
そして、私たちは追いつくことができると期待すべきではありません。現代のインターネットがオープンソースで動いているのには、理由があります。オープンソースには、私たちには真似のできない大きな利点があります。
彼らが私たちを必要とする以上に、私たちは彼らを必要としています。
私たちの技術を秘密にしておくことは、常に微妙な命題でした。Googleの研究者は定期的に他社に移籍しているので、私たちが知っていることをすべて知っていると考えてよいし、そのパイプラインが開かれている限り、そうであり続けるでしょう。
しかし、LLMでの最先端の研究が手頃な価格で受けられるようになった今、テクノロジーにおける競争優位性を維持することはさらに難しくなっています。世界中の研究機関が互いの研究を土台にして、私たちの能力をはるかに上回る広範な方法で解決策を探っているのです。私たちは、外部のイノベーションによってその価値が薄れる中、自分たちの秘密を固く守ることもできますし、互いに学び合うこともできます。
個人は法人と同じ程度にライセンスによる制約を受けない
このイノベーションの多くは、Metaから流出したモデルの重みの上で起こっています(訳注:MetaのLLaMAはMetaに利用申請をした人のみに公開されるはずだったのですが、誰かが広く知られているモデル公開サイトにアップロードしたため、一気に広がりました)。
真にオープンなモデルがより良くなるにつれて、この状況は必然的に変わっていくでしょうが、重要なのは、待つ必要がないということです。法的にカバーされる「個人的な使用(personal use)」と、個人を訴追することの非現実性により、個人はこれらの技術をホットなうちに入手することができます。
自分自身が顧客であることは、用途を理解していると言う事です
アニメ絵の生成からHDRの地形図まで、画像生成の領域で人々が制作しているモデルを見ると、膨大な創造性が溢れています。これらのモデルは、それぞれのサブジャンルに深く入り込んでいる人たちが使い、作り上げたものであり、私たちには到底及ばない深い知識と共感があります。
エコシステムを所有し、オープンソースを活用する
逆説的ですが、この中で明らかに勝者なのはMetaです。流出したモデルが彼らのものであったため、彼らは事実上、地球全体分の無償労働力を獲得したことになります。オープンソースの革新のほとんどは、彼らが公開したアーキテクチャの上で起こっているので、彼らがそれを直接製品に取り入れるのを止めることはできません。
エコシステムを所有することの価値は、いくら強調してもしすぎることはありません。Google自身も、ChromeやAndroidなどのオープンソース製品で、このパラダイムをうまく利用しています。イノベーションが起こるプラットフォームを所有することで、Googleはオピニオンリーダーとして、また方向性を決定する者として確固たる地位を築き、自分よりも大きなアイデアに関する物語を形成する能力を獲得しています。
自分たちのモデルを厳しく管理すればするほど、オープンな選択肢はより魅力的になります。GoogleとOpenAIは、自分たちのモデルがどのように使われるかを厳しく管理できるようなリリースパターンに守備的に引き寄せられました。しかし、このコントロールは虚構です。LLMを公式な許可なしで使おうとする者は、自由に利用できるモデルの中から好きなものを選べばよいのです。
Googleは、オープンソースコミュニティのリーダーとしての地位を確立し、より広範な会話を無視するのではなく、協力することで主導権を握るべきです。これはおそらく、小さなULMバリアントのモデルウェイトを公開するような、不快なステップを踏むことを意味します。これは必然的に、私たちのモデルに対するコントロールをある程度放棄することを意味します。しかし、この妥協は避けられないものです。イノベーションを推進することと、それをコントロールすることの両方を望むことはできないのです。
エピローグ OpenAIはどうでしょうか?
オープンソースの話は、OpenAIの現在の閉鎖的な方針からすると、不公平に感じるかもしれません。彼らが共有しないのに、なぜ私たちが共有しなければならないのでしょうか?しかし、実際のところ、私たちはすでに、上級研究者の引き抜きという形で、彼らとすべてを共有しているのです。その流れを止めない限り、秘密主義は無意味なものです。
そして結局のところ、OpenAIは重要ではありません。彼らは、オープンソースに対する姿勢において、私たちと同じ間違いを犯しており、優位性を維持する能力は必然的に疑問視されています。オープンソースの選択肢は、彼らがその姿勢を変えない限り、いずれ彼らを駆逐する可能性があり、またそうなるでしょう。この点で、少なくとも私たちは先手を打つことができるのです。
付録)時系列
2023年2月24日 – LLaMAの発表
Meta社、LLaMAを発表、コードをオープンソースとして一般公開。重みは限定公開。この時点では、LLaMAは指示や会話のチューニングはされていませんでした。現在の多くのモデルと同様に、比較的小さなモデル(70億、130億、330億、650億のパラメータで利用可能)で、比較的長い時間訓練されているため、そのサイズに比してかなり高性能でした。
2023年3月3日 – 避けては通れない出来事
1週間もしないうちにLLaMAが流出。コミュニティへのインパクトは計り知れません。既存のライセンスは商用利用はできない事とされていますが、突然、誰でも実験できるようになりました。これ以降、イノベーションが次々と起こるようになります。
2023年3月12日 – トースター上で動く言語モデル
それから1週間余り、Artem AndreenkoはRaspberry Piでモデルを動作させることに成功しました。この時点では、メモリへの重みの出し入れが必要なため、モデルの動作が遅すぎて実用的とは言えません。とはいえ、これをきっかけに、ミニ化の取り組みが一気に進むことになります。
2023年3月13日 ノートパソコンを使って微調整
その翌日、スタンフォード大学はLLaMAに指示調整(instruction tuning)を追加したAlpacaをリリースします。しかし、実際の重みよりも重要なのは、Eric Wangのalpaca-loraレポでは、低ランクの微調整を使用して、このトレーニングを「(ハイエンドモデルではあるが消費者向けGPUである)RTX 4090 1台で数時間以内に」実行したことでした。
突然、誰でもモデルを微調整して何でもできるようになり、低予算の微調整プロジェクトで底辺への競争が始まりました。論文には、数百ドル程度の費用をかけたことが誇らしげに書かれています。さらに、低ランクのアップデートは、オリジナルの重みとは別に簡単に配布できるため、Meta社のオリジナルライセンスから独立したものとなっています。誰でも共有し、適用することができるのです。
2023年3月18日 – 今こそ高速化の時!
Georgi Gerganovは、4ビット量子化を使ってMacBookのCPUでLLaMAを実行。実用に耐えうる速度を持つ、最初の「GPUなし」ソリューションです。
2023年3月19日 – 130億モデルがGoogleのBardとの同等の性能を達成
翌日、大学間の共同研究によりVicunaがリリースされ、GPT-4による評価を使ってモデル出力の定性的な比較を行うことになりました。評価方法は疑わしいですが、このモデルは初期の亜種よりも大幅に改善されています。トレーニング費用:300ドルです。
注目すべきは、ChatGPTのAPIの制限を回避して、ChatGPTのデータを利用できたことです。彼らはShareGPTのようなサイトに投稿された「印象的な」ChatGPT対話の例をサンプリングしただけなのです。
2023年3月25日 – 自分の好きなモデルを選びましょう
Nomic は、モデルであり、さらに重要なエコシステムであるGPT4Allを作成します。初めて、モデル(Vicunaを含む)が一か所に集まっているのを見ました。トレーニング費用:100ドル
2023年3月28日 – オープンソース版GPT-3
Cerebras(GoogleのCerebraと混同しないでください)は、Chinchillaが示唆する最適な計算スケジュールとμパラメータ化が示唆する最適なスケーリングを使ってGPT-3アーキテクチャを訓練しました。この結果は、既存のGPT-3クローンを大きく上回るものであり、「野生」でのμパラメータ化の使用が初めて確認されたことになります。これらのモデルはゼロからトレーニングされたものであり、コミュニティはもはやLLaMAに依存していないことを意味します。
2023年3月28日 – 1時間でできるマルチモーダルトレーニング
LLaMA-Adapterは、新しいPEFT(Parameter Efficient Fine Tuning)技術を用い、1時間のトレーニングで指示調整とマルチモダリティを導入しています。印象的なことに、わずか120万の学習可能なパラメータでそれを実現しています。このモデルは、マルチモーダルなScienceQAで新しい最先端のスコアを達成しました。
2023年4月3日 – 本物の人間は130億のオープンモデルとChatGPTの違いを見分けられない
カリフォルニア大学バークレー校は、自由に利用できるデータを使って学習させた対話モデル、Koalaを発表しました。
彼らは、このモデルとChatGPTの間で実際の人間の嗜好を測定するという重要なステップを踏みました。ChatGPTはまだ若干の優位性を保っていますが、50%以上のユーザーがKoalaを好むか、あるいは好みを持たないことが分かりました。
トレーニング費用:100ドル
2023年4月15日 – ChatGPTレベルのオープンソースRLHF
Open Assistantは、RLHFを介してAlignmentのモデル、そしてより重要なデータセットを立ち上げました。
彼らのモデルは、人間の好みという点で、ChatGPTに近い(48.3%対51.7%)ものです。LLaMAに加えて、このデータセットがPythia-120億に適用できることを示し、モデルを実行するために完全にオープンなスタックを使用する選択肢を人々に与えています。さらに、このデータセットは公開されているため、RLHFを実現不可能なものから、小規模な実験者にとって安価で簡単なものにすることができます。
Webbigdataによる補足
「人間の好みという点でChatGPTに近いレベル」と言う件は少し判断が難しい所があるのかな、と思います。確か、fast.aiのJeremy HowardさんのTwitterで紹介されていた話だったと思うのですが、XXXモデルがchatGPTより好ましい回答をしたとされるケースは詳細をチェックすると「20代のお騒がせyoutuberと80代のバイデン大統領がボクシングで戦ったらどちらが勝つか理由も添えて答えてください」的なのがあったりします。
chatGPT「お騒がせyoutuberの方が若くてスタミナがあるので勝ちます」
XXX「老獪なバイデン大統領が勝ちます」
つまり、chatGPTの方が正しくとも、XXXの答えの方が面白かったのでXXXモデルが好ましい回答をしたとされているケースなどです。XXXが狙ってその回答をしたのならば凄いですが、おそらく違うでしょう。「人間にとって好ましい回答」の定義は中々むずかしそうで、結果だけを見て鵜呑みにはできないのです。
とは言え「小さなモデルでより速く反復できるのであれば、大きなモデルの方が能力が高いとは長期的には言えない」は、実際、その可能性はあるのかな、と思います。
多言語で揺り籠から墓場まであらゆる事に対応可能なGPT-4.0以降の全能力を常に必要とするタスクは実は限られるのではないかとも考えられます。
そうすると超大規模言語モデルを高いAPI使用料を払って使い続ける事は何らかのタイミングで見直され、イラスト生成AI界隈で特定のスタイルや絵柄だけに特化したモデルやLoRAが流行っているように言語モデル界隈も、特定の言語/タスクに特化したモデルや微調整が今後、流行っていく可能性はあるのかな、と思います。
また、学習に億単位のお金をかけたと言われるStable Diffusionですが、既に5万ドルでゼロから学習できる手法も発表されているので、コスト最適化に関する進歩はオープンソース界隈の強味が発揮される方向性なのかもしれないな、と思っています。
3.GoogleはAI開発競争における防壁を持っていません!OpenAIもです!関連リンク
1)www.semianalysis.com
Google “We Have No Moat, And Neither Does OpenAI”
2)lmsys.org
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality

