1.Transporter Networks:物体の再配置問題を改善してロボットの性能を向上(2/2)まとめ
・Transporter Netはサンプル効率が高く100回のデモで多くのタスクで90%以上の成功率
・Transporter Netsは適度な数のデモでさまざまなマルチステップの順次タスクを学習可能
・想定外の事態に対するリカバリや高レベルの計画に似た動作を学習し始めた事も観察された
2.Ravensベンチマークとは?
以下、ai.googleblog.comより「Rearranging the Visual World」の意訳です。元記事の投稿は2021年2月16日、Andy ZengさんとPete Florenceさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Rhys Moult on Unsplash
Ravens は、現実世界のセットアップに移行できなくなるような仮定の条件を回避できています。観測データには、RGB-D画像とカメラパラメータのみが含まれます。アクションはロボットの手などのポーズ(end effector poses)で、計算(inverse kinematics)により関節位置に転置できます。
これらの10タスクの実験は、Transporter Netが他のエンドツーエンドの手法よりもサンプル効率が桁違いに高く、わずか100回のデモンストレーションで多くのタスクで90%以上の成功率を達成できることを示しました。その一方、比較対象手法は同じ量のデータでは一般化するのに苦労しました。
これにより、現実のロボットでこれらのモデルをトレーニングするための十分なデモンストレーションデータを収集することがより実際に実行可能な選択肢になります。(以下に例を示します)
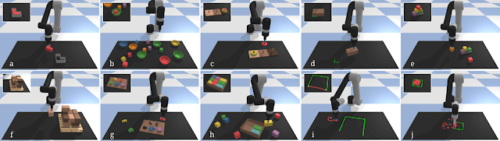
私達の新しいRavensベンチマークには、pushing操作やpick-and-placeなど、シミュレートされた10の視覚ベースの操作タスクが含まれています。実験によると、 Transporter Netsは、他のエンドツーエンドの手法よりもサンプル効率が桁違いに高くなっています。Ravensは、模倣学習メソッドのサンプル効率を評価するために確率的オラクル(stochastic oracle)が組み込まれたGymAPIを備えています。
ハイライト
10のデモンストレーション例から考えると、Transporter Netsは、プレートの積み重ね(驚くほどミスしやすい!)、ボックスの任意の角をテーブル上の印に合わせる、ブロックでピラミッドを構築するなどのマルチモーダルなタスクを学習できます。
![]()
Transporter Netsは、閉ループの視覚的フィードバックを活用することで、適度な数のデモンストレーションでさまざまなマルチステップの順次タスクを学習することができます。有名なアルゴリズム問題であるハノイの塔のディスク移動、ボックスのパレタイズ(box-palletizing:保管や輸送のために物をパレットと呼ばれる板に固定して積みあげる事)、トレーニング中に出現しなかった新しい物体キットの組み立てなど。
これらのタスクにはかなりの「長期的視野」が必要になります。つまり、タスクを解決するには、モデルが多くの個別の選択を正しく順序付ける必要があります。ポリシーはまた、積み上げた物体が転げ落ちる等の想定外の事態に対するリカバリー行動を学習する傾向があります(上図右端)。
![]()
これらの結果の驚くべき点の1つは、知覚だけでなく、モデルが高レベルの計画に似た動作を学習し始めたことです。例えば、有名なアルゴリズム問題である「ハノイの塔」を解決するには、モデルは次に移動するディスクが何かを選択する必要があります。これには、現在表示されているディスクとその位置に基づいてボードの状態を認識する必要があります。
ボックスパレタイズタスクでは、モデルはパレットの空きスペースを特定し、新しいボックスがそれらの空いた空間にどのように収まるかを特定する必要があります。
このような行動は非常に刺激的です。何故ならモデルが不変的な特性を織り込んで、より高レベルの操作パターンを学習することにその能力を集中できることを示唆しているためです。
Transporter Netは、2つのロボットハンドのポーズによって定義されたモーションプリミティブを使用するタスクを学習することもできます。小さな物体の山をターゲット区画に押し込んだり(下図中段)、変形可能なロープを使って正方形の2つの端点を接続(下図右端)したりする事ができます。これは、剛体の空間変位(rigid spatial displacements)が非剛体の空間変位の有用な事前確率として役立つ可能性があることを示唆しています。
![]()
結論
Transporter Netsは、ビジョンベースの操作を学習するための有望なアプローチをもたらしますが、制限がないわけではありません。例えば、ノイズの多い3Dデータの影響を受けやすい可能性があり、モーションプリミティブを使用したスパースウェイポイントベースの制御についてのみ実証しました。また、空間アクションスペースを超えて力またはトルクベースのアクションに拡張する方法は不明です。
しかし、全体として、私たちはこの作業の方向性に興奮しており、これまでに説明した応用事例を超えた拡張機能にインスピレーションを与えることを願っています。詳細については、私たちの論文をチェックしてください。
謝辞
本研究は、Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien, Maria Attarian, Travis Armstrong, Ivan Krasin, Dan Duong, Vikas Sindhwani, Johnny Leeによって行われました。執筆に関する有益なフィードバックを提供してくれたKen Goldberg, Razvan Surdulescu, Daniel Seita, Ayzaan Wahid, Vincent Vanhoucke, Anelia Angelova, Kendra Byrne、運用とハードウェアサポートについてはSean Snyder, Jonathan Vela, Larry Bisares, Michael Villanueva, Brandon Hurd、ソフトウェアインフラストラクチャについてはRobert Baruch、UIへの貢献についてはJared Braun、PyBulletのアドバイスのためのErwin Coumans、ビデオナレーションについてはLaura Graesserに特に感謝します。
3.Transporter Networks:物体の再配置問題を改善してロボットの性能を向上(2/2)関連リンク
1)ai.googleblog.com
Rearranging the Visual World
2)transporternets.github.io
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
3)github.com
google-research / ravens
