1.Googleマップでインドの言葉の翻字を改善(1/2)まとめ
・日本だと「Google 渋谷」でも「グーグル 渋谷」でも渋谷のGoogle入居ビルを捜せる
・同じ単語を別の文字で書く事を翻字(transliteration)と言い多言語では困難になる
・10言語以上が混在するインドでも翻字変換を意識するようにGoogleMapを改善
2.transliterationとtranscriptionの違い
以下、ai.googleblog.comより「Improving Indian Language Transliterations in Google Maps」の意訳です。元記事の投稿は2021年1月22日、Cibu JohnyさんとSaumya Dalalさんによる投稿です。
元記事タイトルにある「transliteration」はNLP研究分野では「翻字」とするのが適切なようなので、本稿では「翻字」としますが、音訳、字訳、文字変換、文字転写、訳字、など様々な訳を持つ単語です。
要は「本当はその国の文字を使って書きたいのだがそれができないので他国の文字を使って書く事」です。主に技術的な理由で起こる事ではありますが、慣れ親しんだ文字を使って表現するという利便性もあります。
一番イメージしやすいのは日本語をローマ字表記する事などです。
しかし、本文中にもあるのですが、「翻字」は「可逆性を優先」するので、厳密にいうとローマ字化などの「発音を優先した変換」は、「転写」(transcription)と見なす区分もあります。ただし、広義の 「翻字」には「転写」も含まれるとする区分もあるので 「翻字」でも良いようです。
ややこしいですが、日本だと「Google 渋谷」でも「グーグル 渋谷」でも渋谷のGoogleが入居しているビルがGoogle Map上に出てきますが、インドは多言語が混在しているので、そんなに簡単に同じ事が実現出来ないのですが、頑張りました、と言うお話です。
アイキャッチ画像のクレジットはPhoto by Pop & Zebra on Unsplash
世界で2番目に多くのインターネットユーザーを抱えるインドの人口の約75%が、英語ではなく主にインドの言語を使用してインターネットを使っています。
今後5年間で、その数は90%に増加すると予想されます。 次世代の10億人のユーザーがGoogleマップにできるだけアクセスできるようにするには、ユーザーがGoogleマップを好みの言語で使用できるようにし、世界中のどこでも探索できるようにする必要があります。
ただし、インドのGoogleマップ上に表示される名称(POIs、places of interest、関心のある場所)のほとんどは、インド語の文字として表記されているわけではありません。これらの名前は英語表記であることが多く、ラテン文字を使った頭字語やインド語の単語や名前と組み合わせることができます。
このような混合言語表現に対処するには、単語の音声特性も考慮しながら、翻訳元言語と翻訳先言語に基づいて、ある文字から別の文字に文字を変換する翻字システムが必要です。
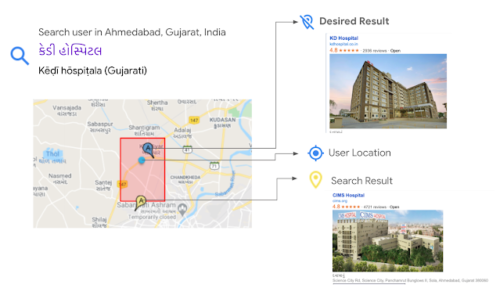
例えば、グジャラート州アーメダバードで、近くの病院「KD病院」を探しているユーザーについて考えてみます。
彼らは、インドで6番目に広く話されている言語であるグジャラート語の文字で、検索語「કેડીહોસ્પિટલ」を入力します。ここで、「કેડી(kay-dee)」は頭字語KDの発音であり、「હોસ્પિટલ」が「病院」です。
この検索では、Googleマップは病院を探すように指示されている事を知っていますが、「કેડી」がKDであることを理解していないため、別の病院であるCIMSを見つけてしまいます。インドで検索対象となる「関心のある場所(POIs)」はグジャラート文字で表現できる名前が比較的少ないため、目的の結果ではなく、ユーザーには意図と異なった結果が表示されてしまいます。
この課題に対処するために、ラテン語文字でかかれたPOIsの名称をインドで良く使われている10の言語(ヒンディー語、バングラ語、マラーティー語、テルグ語、タミル語、グジャラート語、カンナダ語、マラヤーラム語、パンジャブ語、オディア語)に変換する学習モデルのアンサンブルを構築しました。このアンサンブルを使用して、インドの数百万のPOIにこれらの言語の名前を追加し、一部の言語では対応範囲をほぼ20倍に増やしました。これにより、英語を話さない何百万人もの既存のインド人ユーザーがすぐに恩恵を受け、医師、病院、食料品店、銀行、バス停、駅、その他の重要なサービスを自国語で見つけることができるようになりました。
翻字 vs 転写 vs 翻訳
私達の目標は、参照元のラテン文字の名前からインドの言語に固有の文字を使って正しく表記する翻字システムを設計することでした。例えば、デーバナーガリー文字は、ヒンディー語とマラーティー語(マハラシュトラ州ナグプールの地方の言語)の両方の言語の文字です。ナグプールのPOIである「NITガーデン」と「チャンドラマーニーガーデン」のラテン文字の名前を翻字すると、特定の言語の表記法に従って文字で表現すると、それぞれ「एनआईटीगार्डन」と「चंद्रमणीगार्डन」になります。
翻字(transliteration)されたPOI名称は翻訳(Translation)ではないことに注意が必要です。翻字は、同じ単語を別の文字で書くことだけに関係します。
英字新聞がキリル文字を読めない読者のためにキリル文字の「Горбачёв」を「Gorbachev(ゴルバチョフ)」と書く事に似ています。
例えば、前述の文字変換されたPOIの2番目の単語はまだ「garden」と発音されます。グジャラート語の例文の2番目の単語もまだ「hospital」です。これらは、他の文字で書かれただけであり英語の単語「garden」と「hospital」のままです。
実際、一般的な英語の単語は、その地方の文字で記述されている場合でも、インドのPOI名で頻繁に使用されます。これらの文字で名前がどのように表記されるかは、主にその発音によって決まります。したがって、頭字語NITのएनआईटीは、英語の単語「nit」ではなく、「en-aye-tee」と発音されます。NITがこの地域の一般的な頭字語であることを知っていることは、正しい翻字を導き出すときに使用できる根拠の1つです。
また、翻字(transliteration)という用語を使用していますが、書記体系(訳注:日本語でいえば、ひらがな、カタカナ、漢字)間で直接マッピングする際のNLPコミュニティの慣習に従っています。文字に関係なく、南アジア言語のローマ字は、一般的に発音主導型です。従って、これらの手法を翻字(transliteration)ではなく転写(transcription)と呼ぶこともできます。
ただし、これらの言語をラテン文字を使って表記しても発音が比較的粗くしか捕捉できないので、文字間のマッピングは引き続きタスクであり、説明する必要のある文字固有の対応が多数残っています。 これは、ラテン文字の標準的な綴り字の少なさとその結果としての変動性と相まって、タスクを困難にします。
3.Googleマップでインドの言葉の翻字を改善(1/2)関連リンク
1)ai.googleblog.com
Improving Indian Language Transliterations in Google Maps
