
1.RxR:多言語の案内指示に対応する能力を測るベンチマーク(2/2)まとめ
・RxRには約1,000万語が含まれており既存のデータセットの約10倍の規模
・RxRを使い現在の最良のモデルであっても人間の半分程度のスコアである事が判明
・RxRを開発する際に使ったツールPanGEAは公開されておりコンペも継続開催予定
2.RxRを使ったコンペ
以下、ai.googleblog.comより「RxR: A Multilingual Benchmark for Navigation Instruction Following」の意訳です。元記事の投稿は2021年1月21日、Alexander KuさんとPeter Andersonさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Patrick Hendry on Unsplash
RxRの規模
合計で、RxRには約1,000万語が含まれており、R2RやTouchdown/Retouchdownなどの既存のデータセットの約10倍になります。静止画像やテキストデータに基づくタスクと比較して、動きや環境との相互作用による学習を必要とする言語タスクは、通常、大規模なトレーニングデータが不足しているため、これは重要です。
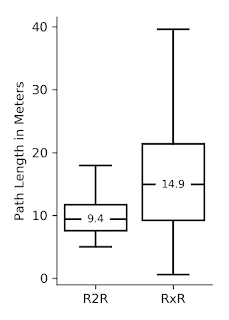
RxRは、他のデータセットで発生した道筋構築における既知の偏りにも対処できます。例えば、すべての道筋の長さが同じで、ゴールまで近道を進む事ができるR2Rなどです。
対照的に、RxRの道筋は平均して長く、予測が難しいため、データセットでトレーニングされたモデルは道筋をたどる事が難しくなり、タスクを遂行する際に言語によるヒントの役割をより重視するようになります。RxRのサイズ、範囲、および詳細は、英語などの高リソース言語の優位性を減らしながら、言語学習の土台となる研究のフロンティアを拡大します。
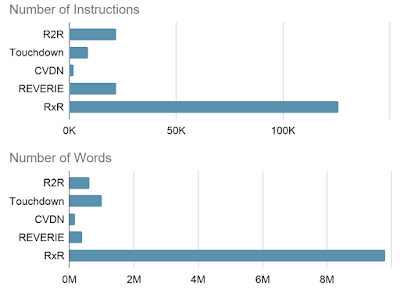
左:RxRは、同様の既存のデータセットよりも規模が1桁大きいです。
右:R2Rと比較すると、RxRの典型的な道筋はより長く、予測が難しいため、追跡が難しくなります。
RxRを使った比較
RxRデータセットをよりよく特徴付けて理解するために、オープンソースフレームワークVALANと多言語BERTモデルから得た言語特徴表現を使用して、RxRでさまざまなエージェントをトレーニングしました。
トレーニング中にフォロワー注釈とガイド注釈を含めることで結果が改善され、独立してトレーニングされた単一言語エージェントが単一の多言語エージェントよりも優れていることがわかりました。
概念的には、これらのエージェントの評価は簡単です。
「エージェントは意図した道筋をたどりましたか?」
経験的に、VLNエージェントがたどる道筋と参照道筋の間の類似性をNDTWを使用して測定します。これは、100(完全な対応)から0(完全に間違っている)の範囲で道筋の忠実度を正規化した尺度です。
同じ道筋でも道筋間に自然なブレがあるため、3言語のフォロワー注釈の平均スコアは79.5です。対照的に、最良のモデル(3つの独立してトレーニングされた単一言語エージェント。各言語に1つ)は、RxRテストセットでNDTWスコア41.5を達成しました。これはランダム(15.4)よりもはるかに優れていますが、人間のパフォーマンスをはるかに下回っています。
言語モデリングの進歩は、GLUEやSuperGLUEなどのテキストのみの言語理解ベンチマークの改善の余地を急速に侵食し続けていますが、言語を物理世界に接続するRxRのようなベンチマークにはかなりの改善の余地があります。
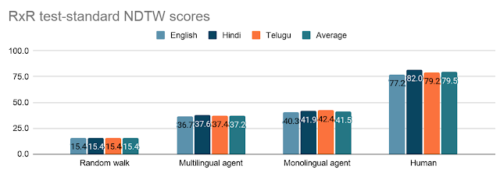
RxRテスト標準分割の多言語および単一言語の指示に従ったエージェントの結果
パフォーマンスはランダムウォークよりもはるかに優れていますが、このタスクで人間のパフォーマンスに到達するにはまだかなりの余地があります。
コンペ
この分野でのさらなる研究を促進するために、自然言語の案内に従うことができる計算エージェントの開発に挑戦する機械学習コミュニティのための継続的なコンペであるRxRチャレンジを開始します。
参加するには、参加者は、提供されたRxRテストの指示に応じてエージェントがたどった道筋をアップロードします。最も困難な設定(本稿と論文内で報告)では、全てのテスト環境が初見の環境となります。ただし、エージェントが事前にトレーニングを受けているか、テスト環境を探索している設定でも受け入れ可能です。詳細と最新の結果については、チャレンジのWebサイトai.google.comの「Room-Across-Room (RxR)」にアクセスしてください。
PanGEA
また、RxRデータセットを収集するために開発したカスタムのWebベースの注釈作業付けツールもリリースしています。パノラマグラフ環境注釈ツールキット(PanGEA: Panoramic Graph Environment Annotation toolkit)は、Matterport3DやStreetLearnなどのパノラマグラフ環境で音声およびテキストの注釈を収集するための軽量でカスタマイズ可能なコードベースです。これには、音声録音と仮想ポーズトラッキングのほか、結果のポーズトレースを手動記録に合わせるためのツールが含まれています。詳細については、PanGEAのgithubページをご覧ください。
謝辞
著者等は、この研究に貢献してくれたRoma Patel, Eugene Ie, Jason Baldridgeに感謝します。また、すべての注釈作業者、テルグ語の注釈を分析してくれたSneha Kudugunta、このプロジェクトのツールと注釈のサポートをしてくれたIgor Karpov、Ashwin Kakarla、Christina Liu、画像機能のサポートをしてくれたAustin WatersとSuWang、データ収集のエグゼクティブサポートを提供してくれたDaphne Luongにも感謝します。
3.RxR:多言語の案内指示に対応する能力を測るベンチマーク(2/2)関連リンク
1)ai.googleblog.com
RxR: A Multilingual Benchmark for Navigation Instruction Following
2)www.aclweb.org
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
3)ai.google.com
Room-Across-Room (RxR)
4)github.com
google-research / pangea
