
1.データサイエンス用のライブラリトップ5まとめ
・有益なデータサイエンスライブラリ5点について書かれた記事を別観点からもう一つ紹介
・Pandas Profiling、NLTK、TextBlob、pyLDAvis、NetworkXの5ライブラリ
・一連のデータ解析業務を実行する際に有用なツールと考えると参考になるラインナップ
2.オススメのデータサイエンス用のライブラリ
以下、towardsdatascience.comより「The Top 5 Data Science Libraries」の意訳です。元記事の投稿は2020年12月9日、Matt Przybylaさんによる投稿です。
先日のオススメPythonライブラリ特集の前半にも後半にも被ってないライブラリがあったので面白いな、と思って読んでみたのですが、良く考えると先日のライブラリはgithubを必須条件としていたので、そのあたりの違いかもしれません。
アイキャッチ画像のクレジットはPhoto by Daniel on Unsplash
データサイエンティストにとって最も便利でユニークなPythonライブラリ、パッケージ、モジュール、およびプラットフォームを詳しく見てみましょう。
前書き
有益なデータサイエンスライブラリ、パッケージ、プラットフォーム、モジュールについて詳しく解説している記事がいくつかあるので、上位ライブラリだけでなく、機能的な重複を減らすために一つのライブラリを選択するように最善を尽くしました。
プロのデータサイエンティストとして、日常業務としてデータの処理に多くの時間を費やしていると聞いただけでなく、それを経験しました。
pandas_profilingのように、これから説明するライブラリのいくつかは、それを念頭に置いています。更に、数値データだけでなく、多くの前処理を必要とするテキストデータも、nltk、textblob、pyldavisなどのライブラリで扱ってきました。
最後に、これらのライブラリのいくつかは、networkxのように視覚化ツールとしてもうまく機能します。以下では、概要と具体的な利点、インストールに関するいくつかのコード、およびこれらの有益なライブラリの使用方法の例について説明します。より優れたデータサイエンティストになるのに役立つこれらのライブラリについて詳しく知りたい場合は、読み続けてください。
(1)Pandas Profiling
pandas_profilingライブラリは、探索的なデータ分析に力を注いでいるデータサイエンティストにとって不可欠な(ほとんどの場合、少なくとも当初はそうすべき)ライブラリです。
名前が示すように、pandasを使用してデータ、より具体的にはpandasのデータフレームをプロファイリングします。HTMLレポートとして見栄えの良い視覚化で確認できる特徴の一部を次に示します。
・型推論
・一意の値
・欠測値
・分位数統計(中央値など)
・記述統計(歪度など)
・ヒストグラム
・相関関係(例:ピアソン)
・テキスト分析
インストール方法
pipの場合は
pip install -U pandas-profiling[notebook] jupyter nbextension enable --py widgetsnbextension # 以下のやり方も私の環境では動いています。 pip install pandas-profiling import pandas_profiling
例
以下は、プロファイルレポート機能からアクセスできる視覚化の1つの例です。
簡単に理解できる、色分けされた相関図を見ることができます。
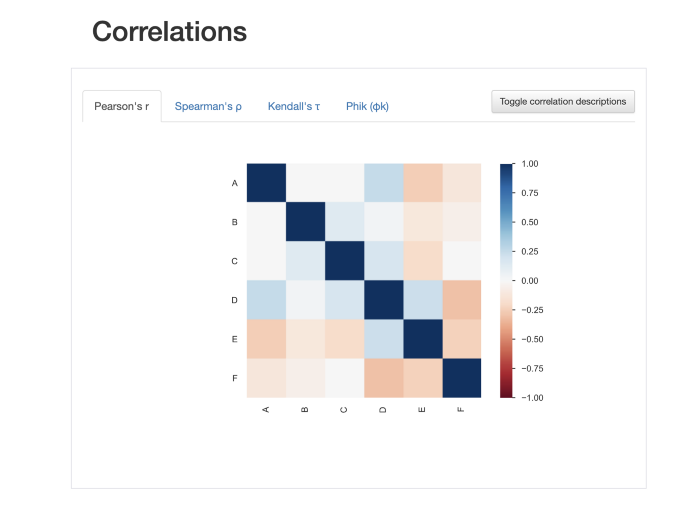
相関プロットの例。原著者によるスクリーンショット
制限事項
もしあなたのデータセットが大規模である場合、このプロファイルレポート作成にはかなりの時間がかかる可能性があります。私の解決策は、単に小さなデータセットを使用するか、データセット全体を代表する小さなデータセットをサンプリングすることです。次に、より効率的な可能性のある様々なデータフレーム計算と方法論を使用して、より深く掘り下げることができます。
全体として、データサイエンスのプロセス/モデルと機械学習アルゴリズムにデータを取り込む前に、データの整合性とパターンを確認するのに最適な方法です。
(2)NLTK
いくつかのデータサイエンスプロジェクトやテキストを含む用例に携わってきた私は、この人気がある強力なツールキットであるnltkを高く評価するようになりました。
nltkに一般的に関連付けられている用語は、NLP、つまり自然言語処理です。これは、テキストの要約をより簡単に組み込むデータサイエンス(およびその他の分野)の分野です。
この場合、Pythonプログラミングを使用します。nltkをインポートすると、すべてのメリットを享受し、テキストの分析を簡単に開始できます。
nltkでアクセスできる機能の一部を次に示します。
・テキストのトークン化(例:tokenizing textを[“tokenizing”, “text”]に分割する)
・POS(part-of-speech)のタグ付け
・ステミングとレンマ化(StemmingとLemmatization)
インストール方法
pip install nltk import nltk
例
import nltk thing_to_tokenize = "a long sentence with words" tokens = nltk.word_tokenize(thing_to_tokenize) tokens # returns: # ["a", "long", "sentence", "with", "words"]
なぜこれがあなたにとって役立つのでしょうか?
単純ですが、分析できるように各単語を分析することが重要です。単語と、場合によっては文字を区切る必要があります。次に、それらにタグを付けてカウントし、機械学習アルゴリズムでそれぞれの入力を使用して予測を作成できます。nltkを利用するもう1つの便利な機能は、テキストが感情分析に適していることです。感情分析は、多くのビジネス、特にカスタマーレビューのあるビジネスで重要です。感情分析について話したので、迅速な感情分析に役立つ別のライブラリを見てみましょう。
TextBlob
TextBlobは、nltkと同じ利点を数多く共有していますが、感情分析機能が優れています。
分析に加えて、ナイーブベイズとディシジョンツリーを利用した分類をサポートする機能もあります。TextBlobでアクセスできる機能の一部を次に示します。
・テキスのトークン化
・POSタグ付け
・分類
・スペル修正
・感情分析
インストール方法
pip install textblob from textblob import TextBlob
感情分析の例
review = TextBlob("here is a great text blob about wonderful Data Science")
review.sentiment
# returns:
# Sentiment(polarity=0.80, subjectivity = 0.44)
polarity(極性)は[-1.0, 1.0]の浮動小数点の範囲にあり、subjectivity(主観性)は[0.0, 1.0]の間にあると予想できます。
分類の例
from textblob.classifiers import NaiveBayesClassifier
training_data = [('sentence example good one', 'pos'), ('sentence example great two', 'pos'), ('sentence example bad three', 'neg'), ('sentence example worse four', 'neg')]
testing_data = [('sentence example good', 'pos'), ('sentence example great', 'pos')]
cl = NaiveBayesClassifier(training_data)
「pos」または「neg」出力を返すこの分類器を使用して、テキストを分類できます。
textblobのこれらの単純なコード行は、非常に強力で便利な感情分析と分類を提供します。
pyLDAvis
NLPで機能するもう1つのツールは、pyLDAvisです。
これは、対話的にトピックモデルを視覚化するツールのライブラリとして機能します。
例えば、通常、LDA(Latent Dirichlet Allocation、潜在的ディリクレ配分法)を使用してトピックモデリングを実行するとセル内に出力されるトピックは読みにくい形で表示されます。しかし、pyLDAvisのように、見栄えの良い要約を行うと、より有益で理解しやすくなります。
pyLDAvisでアクセスできる機能の一部を次に示します。
・上位30の最も顕著な用語を示す
・関連性基準をスライド操作で変更できる対話的なスライドバー
・x軸にPC1、y軸にPC2の上位トピックを表示
・サイズに応じたトピックを表示
・全体として、他のライブラリでは不可能な方法でトピックを視覚化する印象的な方法
インストール方法
pip install pyldavis import pyldavis
例
最良の使用例を確認出来るように、このデータサイエンスライブラリの多くのユニークで有益な属性を示すJupyter Notebookリファレンスをnbviewer.jupyter.orgで公開しています。
NetworkX
このデータサイエンスパッケージであるNetworkXは、生物学的、社会的、およびインフラストラクチャネットワークの視覚化にその強みを集中させています。
NetworkXで利用可能な機能の一部を次に示します。
・グラフ、ノード、およびエッジの作成
・グラフの要素を調べる
・グラフ構築
・グラフの属性
・マルチグラフ
・グラフジェネレータと操作
インストール方法
pip install networkx import networkx
例
# Creating a graph import networkx graph = networkx.Graph()
まとめ
ご覧のとおり、非常に簡単にアクセスできる便利なデータサイエンスライブラリがたくさんあります。 いくつかの探索的データ分析ライブラリ、自然言語処理ライブラリ(NLP)、およびグラフライブラリに光を当てました。
私たちが議論したトップのデータサイエンスライブラリ、プラットフォーム、パッケージ、およびモジュールは次のとおりです。
Pandas Profiling
NLTK
TextBlob
pyLDAvis
NetworkX
データサイエンスのツールと言語について詳しく知りたい場合は、towardsdatascience.comの他の記事を気軽に読んでみてください
3.データサイエンス用のライブラリトップ5関連リンク
1)towardsdatascience.com
The Top 5 Data Science Libraries
2)nbviewer.jupyter.org
pyLDAvis
3)pandas-profiling.github.io
Introduction — pandas-profiling 2.9.0 documentation
4)www.nltk.org
Natural Language Toolkit — NLTK 3.5 documentation
5)textblob.readthedocs.io
TextBlob: Simplified Text Processing — TextBlob 0.16.0 documentation
6)github.com
bmabey / pyLDAvis
7)networkx.org
Tutorial — NetworkX 2.5 documentation

