
1.データサイエンスと機械学習用のPython人気ライブラリ2020年版まとめ
・データサイエンス、データ視覚化、機械学習のためのPythonライブラリ上位38選
・一般的なデータサイエンス用ツールを対象とし、ニューラルベースと研究用途は対象外
・ニューラルネットワーク用と自然言語処理および視覚タスク用のライブラリは次回投稿で
2.データサイエンスと機械学習用のPython人気ライブラリ38選
以下、www.kdnuggets.comより「Top Python Libraries for Data Science, Data Visualization & Machine Learning」の意訳です。元記事の投稿は2020年11月、Matthew Mayoさんによる投稿です。
正直、初めて聞くライブラリの方が多かったです。
アイキャッチ画像のクレジットはPhoto by Todd Quackenbush on Unsplas
本投稿では、KDnuggetsのスタッフが最も良いと判断した、データサイエンス、データ視覚化、機械学習のための上位38のPythonライブラリをまとめています。私達が最後にオススメのPythonライブラリを選出してからからしばらく経ちました。そのため、新しいリストと共に2020年11月を始める事としました。
前回KDnuggetsでこれを行ったとき、編集者兼著者のDan Clarkは、Pythonのデータサイエンス関連の膨大な数のライブラリを、データサイエンスライブラリ、機械学習ライブラリ、ディープラーニングライブラリなどのいくつかのカテゴリに分類しました。ライブラリをカテゴリに分割することは本質的に恣意的ですが、以前の発表を踏襲する事は理にかなっています。
ただし、今回は、オープンソースのPythonデータサイエンスライブラリとして収集したものを2つに分割しました。最初の投稿(本投稿)は「データサイエンス、データ視覚化、機械学習」をカバーしており、一般的なタスクをカバーする(従来の)データサイエンスツールと考えることができます。来週公開される2番目の投稿では、ニューラルネットワークの構築に使用するライブラリと、自然言語処理およびコンピュータ視覚タスクを実行するライブラリについて説明します。
繰り返しになりますが、この分離と分類は恣意的であり、場合によっては他の手法より一方的な評価になりますが、読者にとって最も役立つことを期待して、使用目的毎にツールをグループ化するために最善を尽くしました。
本投稿に含まれるカテゴリは、一般的なデータサイエンス用ツールと見なされていると私達は考えます。非ニューラルネットワークの一般的なツール、研究用途ではなくデータサイエンス分野の実務家によって使用される可能性が高いものは次のとおりです。
(1)データ
データの管理、操作、およびその他の処理のためのライブラリ
(2)数学
多くのライブラリが一般的な数学的なタスクを実行できますが、本当投稿で扱ったツールは独占的な機能を備えています。
(3)機械学習
解釈可能なツールです。ニューラルネットワークを構築するツールや機械学習プロセスの自動化を目的としたライブラリは除外しています。
(4)機械学習の自動化
主に機械学習に関連するプロセスを自動化するために機能するライブラリです。
(5)データの視覚化
モデリングや前処理などではなく、主にデータの視覚化に関連する機能を提供するライブラリです。
(6)説明と調査
主にモデルまたはデータを調査および説明するためのライブラリです。
私達のリストは、私達のチームが合意して一緒に決定したライブラリで構成されており、一般的でよく使用されるPythonライブラリを代表しています。また、ライブラリに含めるためにGithubリポジトリを条件としました。
カテゴリは順不同で各カテゴリに含まれるライブラリも同様です。Githubのスターやその他の指標によって任意に順序を作成することを検討しましたが、ライブラリの認識された価値や重要性を明示的に逸脱しないようにするために取り止めました。従って。したがって、ここでのリストは完全にランダムです。ライブラリの説明は、何らかの形でGithubリポジトリから直接取得されています。
このデータの収集に貢献してくれたAhmed Anisと、KDnuggetsの残りのスタッフの意見、洞察、提案に感謝します。
以下の視覚化は、Gregory Piatetskyによるもので、各ライブラリをタイプ別に表し、スター数(Y軸)と貢献者数(X軸)でグラフ化し、各ツールの印の大きさは、ライブラリがGithubで行っているコミットの数を相対的に表現していることに注意してください。
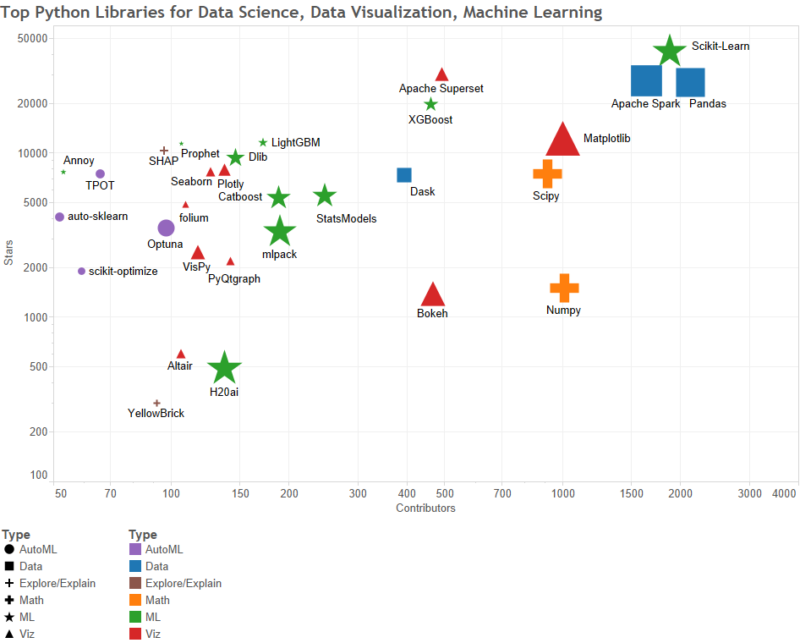
図1:データサイエンス、データ視覚化、機械学習のためのトップPythonライブラリ
スターの数と貢献者の数によってグラフ化されます。 相対的なサイズはコミット数を表現しています。
1.データ
(1) Apache Spark
スター:27600、コミット:28197、貢献者:1638
ApacheSpark-大規模なデータ処理のための統合分析エンジン
(2)Pandas
スター:26800、コミット:24300、貢献者:2126
Pandasは、「リレーショナル」または「ラベル付き」データを簡単かつ直感的に操作できるように設計された、高速で柔軟性のある表現力豊かなデータ構造を提供するPythonパッケージです。これは、Pythonで実用的な実世界のデータ分析を行うための基礎的な土台を高レベルで取り扱えるようになる事を目的としています。
(3)Dask
スター:7300、コミット:6149、貢献者:393
タスクスケジューリング機能付き並列コンピューティング
2.数学
(4)Scipy
スター:7500、コミット:24247、貢献者:914
SciPy(「SighPie」と発音)は、数学、科学、工学向けのオープンソースソフトウェアです。これには、統計、最適化、積分、線形代数、フーリエ変換、信号および画像処理、ODEソルバーなどのモジュールが含まれています。
(5)Numpy
スター:1500、コミット:24266、貢献者:1010
Pythonを使用した科学計算の基本パッケージ。
3.機械学習
(6)Scikit-Learn
スター:42500、コミット:26162、貢献者:1881
Scikit-learnは、SciPy上に構築された機械学習用のPythonモジュールであり、3-ClauseBSDライセンスの下で配布されています。
(7)XGBoost
スター:19900、コミット:5015、貢献者:461
Python、R、Java、Scala、C ++などに対応する、規模拡大可能で移植性能高い分散型勾配ブースティング(GBDT、GBRT、またはGBM)ライブラリ。
単一のマシン、Hadoop、Spark、Flink、およびDataFlowで実行されます
(8)LightGBM
スター:11600、コミット:2066、貢献者:172
デシジョンツリーアルゴリズムに基づく、高速で分散型の高性能勾配ブースティング(GBT、GBDT、GBRT、GBM、またはMART)フレームワーク。ランク付け、分類、その他多くの機械学習タスクに使用されます。
(9)Catboost
スター:5400、コミット:12936、貢献者:188
デシジョンツリーライブラリを使ったの高速で、規模拡大可能で、高性能な勾配ブースティング。
Python、R、Java、C ++のランキング、分類、回帰、その他の機械学習タスクに使用されます。CPUとGPUでの計算をサポートします。
(10)Dlib
スター:9500、コミット:7868、貢献者:146
Dlibは、機械学習アルゴリズムと、現実世界の問題を解決するためにC ++で複雑なソフトウェアを作成するためのツールを含む最新のC ++ツールキットです。dlib APIを介してPythonで使用できます
(11)Annoy
スター:7700、コミット:778、貢献者:53
メモリ使用量とディスクからの読み込み/保存に最適化されたC ++ / Pythonの近似最近傍探索
(12)H20ai
スター:500、コミット:27894、貢献者:137
よりスマートなアプリケーションのためのオープンソースの高速で規模拡大可能な機械学習プラットフォーム。
ディープラーニング、勾配ブースティングとXGBoost、ランダムフォレスト、一般化線形モデリング(ロジスティック回帰、エラスティックネット)、K-Means、PCA、スタックアンサンブル、自動機械学習(AutoML)など。
(13)StatsModels
スター:5600、コミット:13446、貢献者:247
Statsmodels:Pythonの統計モデリングと計量経済学
(14)mlpack
スター:3400、コミット:24575、貢献者:190
mlpackは、他の言語から利用できる、直感的で高速かつ柔軟なC ++機械学習ライブラリです。
(15)Pattern
スター:7600、コミット:1434、貢献者:20
Python用のWebマイニングモジュール。スクレイピング、自然言語処理、機械学習、ネットワーク分析、視覚化のためのツールが含まれています。
(16)Prophet
スター:11500、コミット:595、貢献者:106
線形または非線形の成長を伴う複数の季節性を持つ時系列データに対して高品質な予測を作成するためのツール。
4.機械学習の自動化
(17)TPOT
スター:7500、コミット:2282、貢献者:66
遺伝的プログラミングを使用して機械学習パイプラインを最適化するPython自動機械学習ツール。
(18)auto-sklearn
スター:4100、コミット:2343、貢献者:52
auto-sklearnは、自動化された機械学習ツールキットであり、scikit-learn推定器の完全互換品です。
(19)Hyperopt-sklearn
スター:1100、コミット:188、貢献者:18
Hyperopt-sklearnは、(ハイパーパラメータを自動選択する)Hyperoptをベースとしたモデル選択です。scikit-learnの機械学習アルゴリズムの中からの自動でモデルを選択します。
(20)SMAC-3
星:529、コミット:1882、貢献者:29
シーケンシャルモデルをベースとしたアルゴリズム構成
(21)scikit-optimize
スター:1900、コミット:1540、貢献者:59
Scikit-Optimize、またはskoptは、(非常に)高価でノイズの多いブラックボックス関数を最小限に抑えるためのシンプルで効率的なライブラリです。これは、シーケンシャルモデルベースの最適化のためのいくつかのメソッドを実装します。
(22)Nevergrad
スター:2700、コミット:663、貢献者:38
勾配のない最適化を実行するためのPython用ツールボックス
(23)Optuna
スター:3500、コミット:7749、貢献者:97
Optunaは、特に機械学習用に設計された自動ハイパーパラメータ最適化ソフトウェアフレームワークです。
5.データ視覚化
(24)Apache Superset
スター:30300、コミット:5833、貢献者:492
Apache Supersetは、データ視覚化およびデータ探索プラットフォームです。
(25)Matplotlib
スター:12300、コミット:36716、貢献者:1002
Matplotlibは、Pythonで静的、アニメーション、およびインタラクティブな視覚化を作成するための包括的なライブラリです。
(26)Plotly
スター:7900、コミット:4604、貢献者:137
Plotly.pyは、Python用の対話的なオープンソースのブラウザベースのグラフ作成ライブラリです。
(27)Seaborn
スター:7700、コミット:2702、貢献者:126
Seabornは、matplotlibに基づくPython視覚化ライブラリです。 魅力的な統計グラフィックを描画するための高レベルのインターフェイスを提供します。
(28)folium
スター:4900、コミット:1443、貢献者:109
Foliumは、Pythonエコシステムのデータラングリング(data wrangling:生データを別の形式に変換する事)の長所とLeaflet.jsライブラリのマッピングの長所に基づいて構築されています。Pythonでデータを操作し、Foliumを介してLeaflet mapで視覚化します。
(29)Bqplot
スター:2900、コミット:3178、貢献者:45
Bqplotは、Grammar of Graphics(訳注:どのようにして図示するかを系統だてて解説した有名な本)の構成に基づいた、Jupyterの2D視覚化システムです。
(30)VisPy
スター:2500、コミット:6352、貢献者:117
VisPyは、高性能で対話的な2D/3Dデータ視覚化ライブラリです。VisPyは、OpenGLライブラリを介して最新のグラフィックスプロセッシングユニット(GPU)の計算能力を活用して、非常に大きなデータセットを表示できます。
(31)PyQtgraph
スター:2200、コミット:2200、貢献者:142
科学/工学アプリケーション向けの高速なデータ視覚化およびGUIツール
(32)Bokeh
スター:1400、コミット:18726、貢献者:467
Bokehは、最新のWebブラウザー用の対話的な視覚化ライブラリです。用途の広いグラフィックスをエレガントに簡潔な構造を提供し、大規模なデータセットまたはストリーミングデータセットに対して高性能な双方向性を提供します。
(33)Altair
スター:600、コミット:3031、貢献者:106
Altairは、Python用の宣言型統計視覚化ライブラリです。 Altairを使用すると、データとその意味を理解するためにより多くの時間を費やすことができます。
6.説明と調査
(34)eli5
スター:2200、コミット:1198、貢献者:15
機械学習分類器をデバッグ/検査し、それらの予測を説明するためのライブラリ
(35)LIME
スター:800、コミット:501、貢献者:41
LIME:任意の機械学習分類器の予測を説明する
(36)SHAP
スター:10400、コミット:1376、貢献者:96
ゲーム理論的アプローチで機械学習モデルの出力を説明する
(37)YellowBrick
スター:300、コミット:825、貢献者:92
機械学習モデルの選択を容易にする視覚分析および診断ツール。
(38)pandas-profiling
スター:6200、コミット:704、貢献者:47
pandasのDataFrameオブジェクトからHTMLプロファイリングレポートを作成
3.データサイエンスと機械学習用のPython人気ライブラリ2020年版関連リンク
1)www.kdnuggets.com
Top Python Libraries for Data Science, Data Visualization & Machine Learning
2)github.com
apache / spark
pandas-dev / pandas
dask / dask
scipy / scipy
numpy / numpy
scikit-learn / scikit-learn
dmlc / xgboost
microsoft / LightGBM
catboost / catboost
davisking / dlib
spotify / annoy
h2oai / h2o-3
statsmodels / statsmodels
mlpack / mlpack
clips / pattern
facebook / prophet
EpistasisLab / tpot
automl / auto-sklearn
hyperopt / hyperopt-sklearn
automl / SMAC3
scikit-optimize / scikit-optimize
facebookresearch / nevergrad
optuna / optuna
apache / incubator-superset
matplotlib / matplotlib
plotly / plotly.py
mwaskom / seaborn
python-visualization / folium
bqplot / bqplot
vispy / vispy
pyqtgraph / pyqtgraph
bokeh / bokeh
altair-viz / altair
TeamHG-Memex / eli5
marcotcr / lime
slundberg / shap
DistrictDataLabs / yellowbrick
pandas-profiling / pandas-profiling

