
1.MinDiff:機械学習モデルの不公平な偏見を軽減(2/2)まとめ
・分類器のエラー率のグループ間差異は不公平な偏見の重要な一部だが唯一の偏見ではない
・MinDiffが不公平な偏見に対処する手法や研究を前進させ、改善させる事を願っている
・MinDiffライブラリと関連するデモとドキュメントはtensorflow.orgで公開されている
2.MinDiffの性能
以下、ai.googleblog.comより「Mitigating Unfair Bias in ML Models with the MinDiff Framework」の意訳です。元記事の投稿は2020年11月16日、Flavien ProstさんとAlex Beutelさんによる投稿です。
現実世界は何らかの制約があるので機会均等に関する公平性は本当に難しいです。
例えば、地域Aに住む人達が地域Bに住む人達よりも住宅ローンを完済できない割合が高いとしたら、地域Aに住む人達の貸出審査を厳しくする発想が出てきます。しかし、地域Aに住む人たちが実は黒人が多く、地域Bに住む人たちは白人が多いと言う事になると、人種差別の側面が出てきてしまうので、地域Aと地域Bで審査基準は等しくして機会均等をしようと言う発想が出てきます。しかし、現実世界でこれをこのまま実行してしまうと、回収不能金額の総額が上がってしまうので、そのままでは経営危機に陥ってしまいます。そうすると、地域Aの貸倒れ金額が増える事のバランスを取るためには、地域Bの貸倒れ金額を減らそうという発想が出てきます。しかし、その結果、地域Bの貸出審査が従来より厳しくなり、本来ならば貸出審査に通っていたはずの地域B住民が借り入れする事が出来なくなる、という逆差別の側面が出てきてしまうのです。
上記は貸出問題として有名な事例ですが、人種、性別、地域、などでこの種の綱引きは様々な場面で見る事が出来き、現在のアメリカの分断問題なども根っこはこの辺りに存在します。地域Bの審査が通る立場の人であれば「機会均等は大変結構な事ですね」となりますが、地域Bの審査が通らない立場の人にとっては地域Aの人達が真面目にローンを返済しないのが原因なのに何故、私が割を食わなくてはならないのだ!と怒る人もいるわけです。
アイキャッチ画像のクレジットはPhoto by Jacalyn Beales on Unsplash
MinDiffフレームワーク
これらの設計要件を満たすために、過去数年にわたってMinDiffフレームワークを繰り返し開発しました。人口統計情報がほとんどわからないため、モデルのトレーニング目標を「偏見の除去に特に焦点を当てた目標」に拡張する手法を採用しました。次に、この新しい目標は、既知の人口統計情報を持つデータの小さなデータセットに対して最適化されます。
使いやすさを向上させるために、敵対的なトレーニングから、無害な例の予測と人口統計情報の間の統計的依存性にペナルティを課す正則化フレームワークに切り替えました。これにより、モデルがグループ間でエラー率(例えば、無害なコメントを有害として分類するようなエラー)を等しくするようになります。
予測と人口統計情報の間のこの依存関係を符号化する方法はいくつかあります。最初のMinDiff実装では、予測と人口統計グループ間の相関が最小限に抑えられました。これにより、後の分布がまだ異なっている場合でも、予測の平均と分散がグループ間で等しくなるように基本的に最適化されます。
その後、最大平均不一致(MMD:Maximum Mean Discrepancy)損失を考慮することにより、MinDiffをさらに改善しました。これは、人口統計に依存せず、予測の分布を最適化に近づけるものです。この手法は、偏見を取り除き、モデルの精度を維持するために適していることがわかりました。
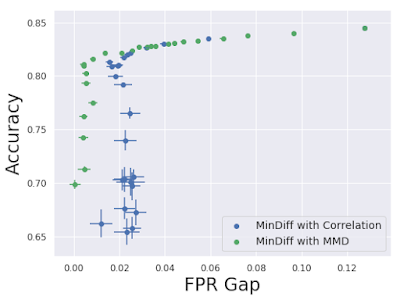
MMDを使用したMinDiffは、精度の低下を抑えながらFPRのグループ間差異を適切に扱います。
(学術界のベンチマークデータセットをつかった検証)
これまで、コンテンツの品質を評価する、Googleのいくつかの分類器についてモデリングの改善を立ち上げました。堅牢で責任ある規模拡大可能な手法を開発し、研究の課題を解決し、幅広い採用を可能にするために、複数の反復を繰り返しました。
分類器のエラー率のグループ間の差異は、対処すべき不公平な偏りの重要な一部ですが、MLアプリケーションで発生する唯一の偏見ではありません。MLの研究者や実務家にとって、この研究がさらに幅広いクラスの不公平な偏見に対処し、現実世界のアプリケーションで使用できる手法の開発に向けて研究を更に前進させる事を願っています。
更に、MinDiffライブラリと関連するデモとドキュメントのリリースが、ここで共有されているツールと経験とともに、実践者がモデルと製品を改善するのに役立つことを願っています。
謝辞
分類における機械学習の公平性に関するこの研究活動は、Jilin Chen, Shuo Chen, Ed H. Chi, Tulsee Doshi 及び Hai Qianの共同で主導されました。更に、この作品は、Jonathan Bischof, Qiuwen Chen, Pierre Kreitmann, 及び Christine Luuとの共同作業で研究されました。MinDiffインフラストラクチャは、Nick Blumm, James Chen, Thomas Greenspan, Christina Greer, Lichan Hong, Manasi Joshi, Maciej Kula, Summer Misherghi, Dan Nanas, Sean O’Keefe, Mahesh Sathiamoorthy, Catherina Xu, そして Zhe Zhaoと共同で開発されました。(全ての名前は姓のアルファベット順にリストされています)
3.MinDiff:機械学習モデルの不公平な偏見を軽減(2/2)関連リンク
1)ai.googleblog.com
Mitigating Unfair Bias in ML Models with the MinDiff Framework
2)arxiv.org
Toward a better trade-off between performance and fairness with kernel-based distribution matching
3)www.tensorflow.org
Remediation

