
1.Performers:Attentionの規模拡大を容易にする(3/3)まとめ
・PerformerはAttentionをまったく使用していないモデルに非常に近い性能を発揮
・転移後に微調整すると元の勾配ステップ数のごく一部で精度をすばやく回復
・Attention、Transformersカーネル法の全く新しい考え方を開く可能性
2.Performersの性能
以下、ai.googleblog.comより「Rethinking Attention with Performers」の意訳です。元記事の投稿は2020年10月23日、Krzysztof ChoromanskiさんとLucy Colwellさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Marine Golfetto on Unsplash
Performerの性質
最初に、Performerの空間的、時間的複雑さに関する性能を測定し、Attentionのスピードアップとメモリ使用量削減が経験則的にほぼ最適化出来ている事、つまり、Attentionメカニズムをまったく使用していないモデルに非常に近いことを示します。
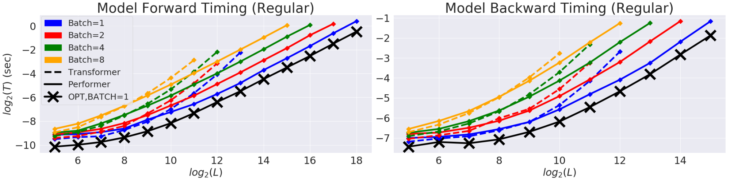
時間(T)と長さ(L)を対数化したグラフでの通常の双方向Transformerモデルの性能
横軸はGPUのメモリ制限一杯までです。黒い線(X)は、ダミーAttentionブロックを使用した際の可能な最大のメモリ圧縮と高速化を示します。ダミーAttentionブロックは本質的にAttention演算を行わないため、モデルが達成可能な最大の効率を示します。
PerformerモデルはAttentionコンポーネントを使用していますが、この最適なパフォーマンスにほぼ到達できます。
更に、Performerは、バイアスのないソフトマックス近似を使用して、少し微調整すれば、事前学習済みTransformerモデルと下位互換性があることを示します。これにより、既存のモデルを完全に再トレーニングすることなく、推論速度を向上させることでき、エネルギーコストを削減できる可能性があります。
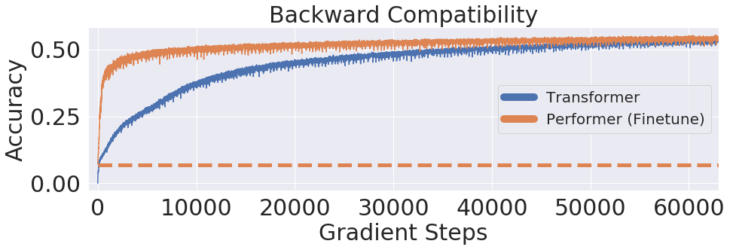
10億単語が含まれるベンチマーク(LM1B)データセットを使用して、事前にトレーニングされた元のTransformerの重みをPerformerモデルに転移しました。これにより、初期は0.07の精度となります(オレンジ色の点線)。ただし、微調整すると、Performerは元の勾配ステップ数のごく一部で精度をすばやく回復します。
アプリケーション事例:タンパク質モデリング
タンパク質は、生命に不可欠で複雑な3D構造と特定の機能を備えた大きな分子です。
単語と同様にタンパク質は線形な文字の並びとして表現され、各文字は20個のアミノ酸を表す基礎構造の1つです。
Transformerをタンパク質配列の大きなラベルなし資料(UniRefなど)に適用すると機能性高分子について正確な予測を行うために使用できるモデルが得られます。
Performer-ReLU(ReLUベースのAttention、softmaxとは異なる一般化されたAttentionのインスタンスを使用)は、タンパク質配列データのモデリングで強力に機能します。一方、Performer-Softmaxは、理論的な結果から予測されるように、Transformerのパフォーマンスと一致します。
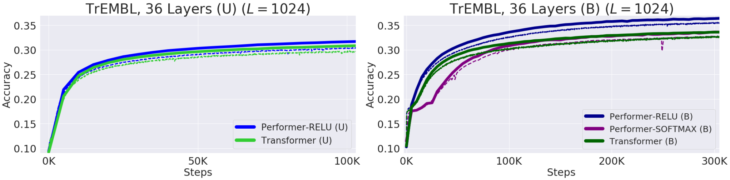
タンパク質配列のモデリングにおけるパフォーマンス
学習時=破線、検証時=実線、単方向=(U)、双方向=(B)。全ての実行でProGen(2019)の36層モデルパラメーターを使用し、それぞれが16 x 16TPU-v2を使用しています。対応する計算の制約を考慮して、バッチサイズは実行毎に最大化されました。
以下では、ReLUベースの近似Attentionメカニズムを使用してトレーニングされたタンパク質用のPerformerモデルを視覚化します。
Performerを使用してアミノ酸間の類似性を推定すると、既知の置換配列と同様の構造が得られます。この置換配列は、慎重に収集された配列アラインメント全体の進化的置換パターンを分析して得られたものです。
より一般的には、タンパク質データでトレーニングされたTransformerモデルと一致する局所的、および大域的なAttentionパターンが見つかります。
Performerによる密なAttentionの近似は、複数のタンパク質配列にわたる大域的な相互作用を捕捉する可能性があります。
概念実証として、長い連結タンパク質配列でモデルをトレーニングします。これは通常のTransformerモデルのメモリを過負荷にしますが、空間効率が高いためにPerformerは過負荷になりません。
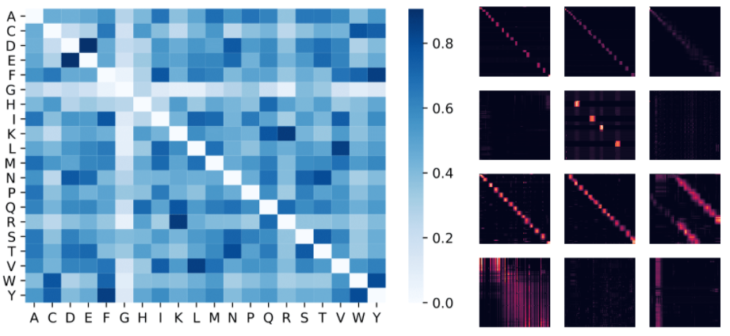
左:Attentionの重みから推定されたアミノ酸類似性マトリックス
このモデルは、生化学に関する事前情報がなく、タンパク質配列にしかアクセスできないにもかかわらず、(D, E)や(F, Y)などの非常に類似したアミノ酸ペアを認識します。右:中央:BPT1_BOVINタンパク質の4つのレイヤー(行)と3つの選択されたヘッド(列)からのAttention行列。局所的、および大域的なAttentionパターンを示しています。
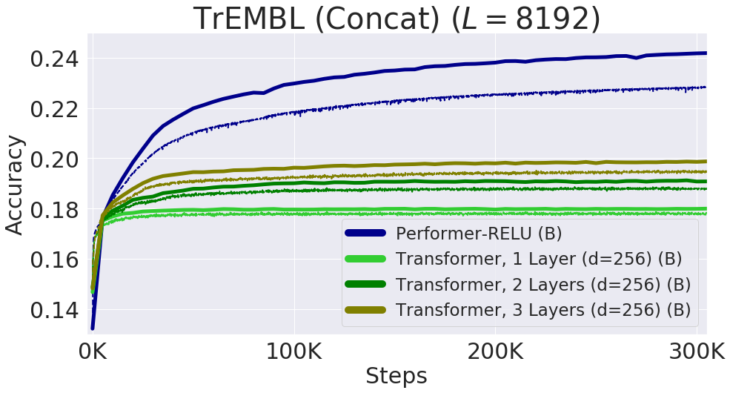
個々のタンパク質配列を連結することによって得られる長さ8192までの配列でのパフォーマンス
TPUメモリに収まるように、Transformerのサイズ(レイヤー数とembedding次元)が縮小されています。
結論
私達の研究は、Transformerの非スパース性ベースの手法とカーネルベースの解釈に関する最近の取り組みに貢献しています。
私達の方法は、リバーシブルレイヤーなどの他の手法と相互運用可能なため、FAVORをReformerのコードと統合しています。論文、Performerのコード、およびタンパク質言語モデリングコードへのリンクは下部に記します。
私達の研究は、Attention、Transformersアーキテクチャ、更にはカーネル法についてのまったく新しい考え方を開くと信じています。
謝辞
本研究は、David Dohan, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Wellerの貢献と共に、コアPerformerデザイナーのKrzysztof Choromanski(Google Brain Team、Tech and Research Lead)、Valerii Likhosherstov (University of Cambridge) and Xingyou Song (Google Brain Team)によって実施されました。
効率的なTransformerアーキテクチャをタンパク質配列データに適用する研究を共同で主導してくれた応用科学チームに特に感謝します。
更に、生物学的データに関する多くの有益な議論とこのドラフトに関する有益なコメントを提供してくれたJoshua Meier, John Platt, そして Tom Weingarten、およびベースラインの比較に関する議論をしてくれたYi Tay とMostafa Dehghaniに感謝します。
Reformerについて複数の議論をしてくれた Nikita KitaevとWojciech Gajewskiに感謝し、Routing Transformerについて複数の議論をしてくれたAurko RoyとAshish Vaswaniに感謝します。
3.Performers:Attentionの規模拡大を容易にする(3/3)関連リンク
1)ai.googleblog.com
Rethinking Attention with Performers
2)arxiv.org
Rethinking Attention with Performers
Efficient Transformers: A Survey
3)github.com
google-research/performer/fast_self_attention/
google-research/performer/
google-research/protein_lm/

