
1.RigL:ニューラルネットワークの冗長性を動的に最適化(2/3)まとめ
・RigLはランダムマスクから開始し大きな勾配を持つ接続をアクティブする
・大きな勾配を持つ接続は損失を最も迅速に減少させることが期待出来るため
・RigLは他の手法よりも必要な計算機資源を最小に抑えながら最大精度を達成
2.RigLとは?
以下、ai.googleblog.comより「Improving Sparse Training with RigL」の意訳です。元記事の投稿は2020年9月16日、Utku EvciさんとPablo Samuel Castroさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by fran hogan on Unsplash
RigLの概要
RigLは、ランダムに疎にマスクしたネットワークから開始します。等間隔で、重みの大きさが最小の接続の一部を削除します。このような戦略を取ると、損失にほとんど影響しない事が先行研究で示されています。
次にRigLは、瞬間的な勾配情報を使用して、つまり過去の勾配情報を使用せずに、新しい接続を行います。接続を更新した後、次の定期更新まで、更新されたネットワークでトレーニングを続行します。次に、システムは、大きな勾配を持つ接続をアクティブにします。こういった接続は、損失を最も迅速に減少させることが期待出来るからです。

RigLは、ネットワークをランダムで疎な形状にマスクする事から始まります。次に、ネットワークをトレーニングし、活動的でない弱い接続を削除します。再構成したネットワークで勾配を計算し、新しい接続を拡大し、再度トレーニングするサイクルを繰り返します。
パフォーマンスの評価
RigLはトレーニング中にニューロンの接続を動的に変更する事で最適化し、より良いネットワーク構造を見つける事に役立ちます。
これを実証するために、精度が低く性能が悪いモデルをRigLで再トレーニングします。RigLのマスクを使った最適化は、静的トレーニングと比較して損失を改善できることがわかります。ネットワークの連結性(connectivity)は変わりません。
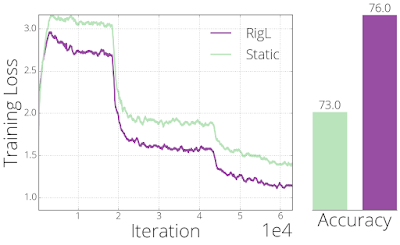
同じ接続条件から開始したRigLと静的手法のトレーニング損失と最終的な精度の比較。
以下の図は、80%疎なResNet-50アーキテクチャを使って、様々なトレーニング手法のパフォーマンスを比較したものです。
RigLを、同様な疎なトレーニングメソッドであるSETとSNFS、及び3つの比較対象手法(Static(静的)、Small-Dense(小密度)、Pruning(刈り込み))と比較しました。
これらの方法のうち2つ(SNFSとPruning)では、大規模なネットワークをトレーニングするか、その勾配を格納する必要があるため、密なリソースが必要です。
全体として、トレーニング時間が増えると、全ての手法でパフォーマンスが向上することがわかります。そのため、各手法について、100エポックのトレーニングを基本として最大5倍までトレーニングしました。
多くの研究で指摘されているように、スパース性を固定してゼロからネットワークをトレーニング(Static)すると、Pruningで見つかるソリューションと比較してパフォーマンスが低下します。
同じ数のパラメーターを使用して小規模な高密度ネットワークをトレーニング(Small-Dense)すると、Staticよりも優れた結果が得られますが、動的スパースモデルのパフォーマンスには匹敵しません。
同様に、SETはSmall-Denseよりもパフォーマンスを向上させますが、約75%の精度で飽和し、ランダムに新しい接続を増加させる手法の限界を明らかにします。
勾配情報を使用して新しい接続を拡張する手法(RigLとSNFS)は、一般に高い精度を取得しますが、RigLは他の手法よりも一貫して必要なFLOP(および使用メモリ)を最小限に抑えながら最高の精度を実現します。
3.RigL:ニューラルネットワークの冗長性を動的に最適化(2/3)関連リンク
1)ai.googleblog.com
Improving Sparse Training with RigL
2)proceedings.icml.cc
Rigging the Lottery:Making All Ticket Winners(PDF)
3)github.com
google-research/rigl
4)www.nature.com
Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science(SET)
5)arxiv.org
Sparse Networks from Scratch: Faster Training without Losing Performance(SNFS)
SNIP: Single-shot Network Pruning based on Connection Sensitivity
