
1.Dataset Searchで検索可能なオンラインデータセットの分析(2/2)まとめ
・データセットの72%は既知のライセンスを指定しておりその89.5%が無料利用可能
・ライセンスとDOI(Digital Object Identifiers)を指定する事は使いやすさにとって重要
・Dataset Searchに登録されている検索対象となる資料の一部をKaggleで公開中
2.Datasetの利用を促進するために有効な事
以下、ai.googleblog.comより「An Analysis of Online Datasets Using Dataset Search (Published, in Part, as a Dataset)」の意訳です。元記事の投稿は2020年8月25日、Natasha NoyさんとOmar Benjellounさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Mael BALLAND on Unsplash
ライセンス情報を指定しているデータセットの中で、72%は既知のライセンスを指定していました。これらのライセンスには、英国やカナダで使われているのオープンガバメントライセンス(OGL:Open Government licenses、行政が公開しているデータを再利用する際に何を守って何に注意するべきかを明文化してくれているライセンス)、クリエイティブコモンズライセンス、およびいくつかのパブリックドメインライセンス(Public Domain Mark 1.0)が含まれます。これらのデータセットの89.5%が無料でアクセスできるか、再配布を許可するライセンスを使用している、またはその両方であることがわかりました。そして、これらのオープンなデータセットのうち、560万(91%)は商業的な再利用を可としています。
データの再利用性のもう1つの重要な要素は、ダウンロード可能なデータを提供することですが、データセットの44%だけがメタデータ内でダウンロード情報を指定しています。この驚くほど低い値の考えられる説明は、ウェブマスター(またはデータセットを保持しているプラットフォーム)がschema.orgで定義されているメタデータを介してデータダウンロードリンクを公開してしまうと、検索エンジンやその他のアプリケーションがユーザーにデータをダウンロードするための直リンクを公開してしまう事、つまりデータ公開者のウェブサイトへのアクセス数が減ってしまう事を恐れているためです。
別の懸念は、データが適切に使用されるために適切な使用条件が明示される(例えば、たとえば、方法論、脚注、およびライセンス情報)事が必要である事です。データ公開者はWebページのみが全体像を提供できると感じています。Dataset Searchでは、データセットのメタデータの一部として直接ダウンロードするリンクを表示しないため、ユーザーはデータ公開者のWebサイトにアクセスしてデータをダウンロードする必要があり、その際にデータセットの完全な使用条件が表示されます。
Dataset Searchのユーザーは何にアクセスしているのでしょうか?
最後に、Dataset Searchがどのように使用されているかを調べます。
2020年5月の14日間で上位100のデータセット検索結果に表示されたのは、210万の一意なデータセットです。これらのデータセットの公開元は2,600サイトです。
照会されたトピックの分布は、Dataset Searchで検索可能な資料全体の分布とは異なります。
例えば、地球科学ははるかに小さい割合を占め、逆に、生物学と医学はコーパスのシェアに比べて大きい割合を表しています。この結果は、COVID-19のパンデミックの最初の数週間に行われたため、分析タイミングによって影響を受けていると説明出来る可能性があります。
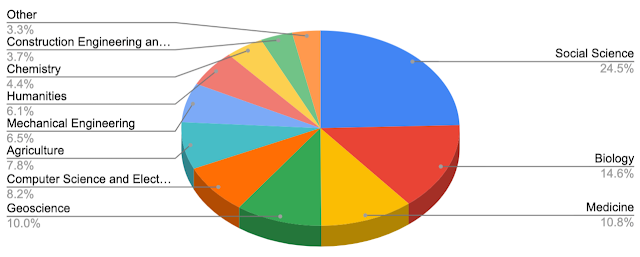
検索結果に表示されたデータセットがカバーしているトピックの分布
科学的データセットを公開する際のより良い方法
今回の分析結果に基づいて、データセットの検出、再利用、引用の方法を改善できる一連のベストプラクティスを特定しました。
(1)発見可能性(Discoverability)
データセットのメタデータは、ウェブクローラーがアクセスできる場所に設置され、発見しやすさを向上させるために、機械が読み取り可能な形式でメタデータを提供する必要があります。
(2)持続性(Persistence)
個人のWebページよりも永続性が高いと思われるサイトでメタデータを公開すると、データの再利用と引用が容易になります。
実際、Dataset Searchの使用状況の分析中に、回転率が非常に高いデータがある事に気付きました。ある時点でデータセットをホストしていた多くのURLには、数週間または数か月後にそれがありませんでした。
Figshare、Zenodo、DataDryad、Kaggle Datasetsなどのデータ保管庫を利用する事は、データセットの永続性を確保するための優れた方法です。これらのデータ保管庫の多くは、データを永続的に保存するためにライブラリと協定を結んでいます。
(3)来歴(Provenance)
データセットは複数のデータ保管庫で公開されることが多いため、来歴情報をメタデータでより明確に記述すると便利です。来歴情報は、ユーザーがデータを収集した人、データセットの主要なソースがどこにあるか、またはデータがどのように変更されたかを理解するのに役立ちます。
(4)ライセンス(Licensing)
データセットには、ライセンス情報を、理想的には機械で読み取り可能な形式で含める必要があります。私達の分析は、データ公開者がライセンスを選択するとき、彼らはかなりオープンなものを選択する傾向があることを示しています。従って、データ公開者がデータのライセンスを選択する事を奨励および有効にすると、より多くのデータセットがオープンに利用できるようになります。
(5)永続的な識別子(DOIなど)の割り当て
DOI(Digital Object Identifiers)は、長期的な追跡と使いやすさにとって重要です。これらの識別子を使用すると、データセットの引用やバージョンの追跡がはるかに簡単になるだけでなく、逆参照、つまり、データセットの公開場所が移動した場合に識別子を移動先を指し示すように変更する事ができます。
永続的な識別子を持つデータセットのメタデータの公開
本日の発表の一部として、皆さんが使用できるようにDataset Searchに登録されている資料の一部をKaggleで「Dataset Search: metadata for datasets」として公開しています。
これには、DOIおよびその他のタイプの永続的な識別子を持つ300万を超えるデータセットのメタデータが含まれており、最も簡単に引用できるデータセットです。
研究者はこのメタデータを使用して、より深い分析を実行したり、このデータを使用して独自のアプリケーションを構築したりできます。
例えば、DOIは過去10年間に急速に使われるようになったようです。
この時間枠はデータセットとどのように関連していますか?DOIを使っているデータセットの分布はデータセット全体で均一ですか?それとも研究コミュニティ間で大きな違いがありますか?
データセットは定期的に更新していきます。最後に、永続的に引用可能な識別子を持つデータセットのみをこのデータ公開の対象とする事で、より多くのデータ公開者がデータセットをより詳細に説明し、より簡単に引用できるように努める傾向が助長されることを願っています。
結論として、Google Dataset Searchなどのツールを介してデータを見つけやすくすることで、科学者がデータをより広く共有し、データを真に公正な方法(fairsharing.org)で実行できるようになることを願っています。
謝辞
この投稿は、Dataset Searchチーム全体の作業を反映しています。Shiyu Chen, Dimitris Paparas, Katrina Sostek, Yale Cong, Marc Najork, そして Chris Gorgolewskiの貢献に感謝します。また、この分析を提案し、多くの役立つアイデアを提供してくれたHal Varianにも感謝します。
3.Dataset Searchで検索可能なオンラインデータセットの分析(2/2)関連リンク
1)ai.googleblog.com
An Analysis of Online Datasets Using Dataset Search (Published, in Part, as a Dataset)
2)datasetsearch.research.google.com
Google Dataset Search
3)research.google
Google Dataset Search by the Numbers
4)www.kaggle.com
Dataset Search: metadata for datasets
5)fairsharing.org
FAIRsharing
6)search.google.com
構造化データ テストツール


コメント