
1.MentorMix:現実世界の誤ラベルがディープラーニングに及ぼす影響を調査(1/3)まとめ
・ディープラーニングの学習には大規模データが必要だが大規模になると誤ラベルが混ざる
・ラベルにノイズが多い場合の対処法は研究されてきたが合成した誤ラベルを使っていた
・合成した誤ラベルとWeb世界の誤ラベルは性質が異なるのでデータセットが新規に必要
2.本当の誤ラベルと合成した誤ラベルの違い
以下、ai.googleblog.comより「Understanding Deep Learning on Controlled Noisy Labels」の意訳です。元記事の投稿は2020年8月19日、Lu JiangさんとWeilong Yangさんによる投稿です。
間違ったラベルが付けられているように見えるアイキャッチ画像のクレジットはPhoto by Jamie Matociños on Unsplash
ディープニューラルネットワークの成功は、高品質のラベル付きトレーニングデータへのアクセスに依存しています。トレーニングデータに間違ったラベル(ラベルノイズ)が存在すると、クリーンなテストデータを使ったモデルの精度が大幅に低下するためです。
残念ながら、大規模なトレーニングデータセットには、ほとんどの場合、ラベルが正確ではないか間違ったラベルが含まれています。これは逆説的ですが、一方では、より良いディープネットワークをトレーニングするために大きなデータセットが必要ですが、他方では、ディープネットワークはトレーニングラベルのノイズを記憶してしまう傾向があるため、実際にはモデルのパフォーマンスが低下してしまうのです。
AI研究コミュニティはこの問題の重要性を認識しており、ノイズの多いトレーニングラベルを理解しようとする研究が導入されています。例えば、Arpit等による研究「A Closer Look at Memorization in Deep Networks」や、MentorNetやco-teachingなどの緩和戦略を用いてこの問題を克服しようとしてきました。
データセット内のラベルが正しくないサンプルの割合を制御しながら実験する事は重要な役割を果たします。モデルのパフォーマンスに対するノイズレベルの影響を調査することにより、ノイズの多いラベルに対する理解が深まるためです。
ただし、従来の実験は合成ラベルを使って実行されています。つまり、ランダムにノイズを割り当てたラベルを使って実験しており、これでは現実世界のラベルノイズと異なった分布を持つノイズになってしまいます。
このような研究は、現実世界の実データがノイズ付きラベルから受ける影響と比較して、非常に異なる、あるいは矛盾する結果をもたらす可能性があります。更に、合成ノイズで十分に機能する方法は、現実世界の実際のノイズの多いラベルではうまく機能しない可能性があります。
ICML 2020で発表した論文「Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels」では、合成ではないノイズが多く含まれるラベルに関するディープラーニングの理解を深めるために3つの貢献をしています。
最初に、Webから発生した現実世界のラベルノイズ(つまり、Webラベルノイズ)を使った最初の制御されたデータセットとベンチマークを定めます。
第二に、私たちは、合成ノイズと現実世界のノイズの両方のラベル問題を克服するために、シンプルですが非常に効果的な方法を提案します。
最後に、様々な設定で合成およびウェブラベルノイズを比較する、これまでで最大の調査を実施します。
合成されたノイズと現実世界(Web)のノイズの特性
合成ノイズと現実世界(Web)のノイズでは、ノイズの分布にいくつかの違いがあります。まず、Webでラベルにノイズを持つ画像は、正確なラベルを持つ画像と視覚的または意味的に一貫性を持つ傾向があります。
第2に、合成ラベルノイズはクラスレベルであり(特定種別の全ての画像に同じ様にノイズが含まれる)、現実世界のラベルノイズは実体レベルです。(特定の画像が、種別に関係なく、他のものよりも誤ってラベル付けされる可能性が高くなる)。例えば、「ホンダシビック」と「ホンダアコード」の画像は、乗物を正面から撮影した場合よりも、横から撮影した場合の方が混乱を招きやすいです。
3番目に、現実世界のラベルノイズが含まれる画像は、そのデータセット内に含まれていないクラスがノイズとして含まれる場合があります。例えば、Webで「テントウムシ」のラベルに含まれるノイズには、「ハエ」やデータセットのクラスリストに含まれていないその他の虫が含まれます。
制御されたラベルノイズのベンチマークは、合成および実際のWebラベルノイズの違いをより定量的に理解するのに役立ちます。
Webから取得したラベルノイズを制御して行うベンチマーク
本研究のベンチマークは、2つのパブリックデータセットを使って構築されています。
通常の画像分類(coarse-grained image classification)用のMini-ImageNetと、きめ細かい画像分類(fine-grained image classification)用のStanford Carsです。合成データセットを構築する際の標準的な方法に従って、これらのデータセット内のクリーンな画像を、Webから収集された誤ってラベル付けされた画像に徐々に置き換えます。
これを行うために、クラス名(「テントウムシ(ladybug)」など)をキーワードとして使用して、Webから画像を収集します。手動でラベル付けするのではなく、ノイズの多いラベル付き画像をWebから自動的に収集します。
取得された各画像は、Google Cloud Labeling Serviceを使用して3~5人の注釈作業者によって検査され、与えられたWebラベルが正しいかどうかが識別され、21.3万件近くの注釈付き画像が生成されました。
元のMini-ImageNetおよびStanford Carsデータセットのクリーンなトレーニング画像を一定割合で置き換えるために、これらの誤ったラベルを持つWeb画像を使用します。ラベルノイズの割合が次第に高くなる10の異なるデータセットを作成しました。(0%のクリーンなデータから誤ったラベルが80%存在するデータまで)。データセットは、Controlled Noisy Web LabelsのWebサイトでオープンソースとして公開されています。
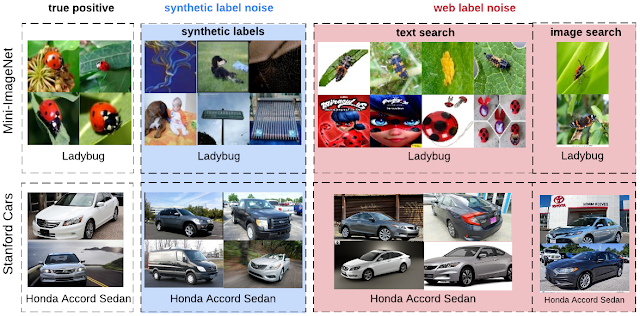
合成したラベルノイズとウェブラベルノイズの比較
左から右に、上段はMini-ImageNet、下段はStanford Carsデータセットで、正確なラベルを持つ画像、正しくない合成ラベルを持つ画像、および正しくないウェブラベルを持つ画像(今回の作業で収集)です。
3.MentorMix:現実世界の誤ラベルがディープラーニングに及ぼす影響を調査(1/3)関連リンク
1)ai.googleblog.com
Understanding Deep Learning on Controlled Noisy Labels
2)arxiv.org
A Closer Look at Memorization in Deep Networks
Do Better ImageNet Models Transfer Better?
Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels
CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
3)github.com
google-research/mentormix/
4)google.github.io
Controlled Noisy Web Labels

