
1.MediaPipe KNIFT:テンプレートベースの画像検索を改善(1/3)まとめ
・KNIFTはSIFTやORBと同様に局所的な画像範囲をコンパクトにベクトル化する特徴表現
・KNIFTは局所的な範囲から直接学習するembeddingで経験則的な設計が含まれない
・軸移動以外にもある程度の遠近の違いを伴った歪みに対しても、より堅牢に見える
2.MediaPipe KNIFTとは?
以下、developers.googleblog.comより「MediaPipe KNIFT: Template-based feature matching」の意訳です。元記事の投稿は2020年4月22日、Zhicheng WangさんとGenzhi Yeさんによる投稿です。
MediaPipeシリーズの記事が結構揃ってきたのですが、MediaPipe KNIFTなど、いくつかはGoogle AIの方ではなく、developers.googleblog.comの方に投稿されていたので訳してみました。
アイキャッチ画像のクレジットはPhoto by Markus Spiske on Unsplash
2020年12月追記)その他のMediaPipeシリーズのまとめ記事はこちら。
KNIFEによる画像の特徴表現
多くのコンピュータービジョンアプリケーションで大切な土台となる技術は、異なる視点間で同一物体、または同一風景を認識し、信頼できる対応関係を確立することです。これは、テンプレートマッチング(訳注:入力として与えたテンプレート画像が検索対象画像の中に含まれているか否かを捜すタスク)、画像検索、SfM(Structure from Motion:二次元画像から三次元構造を再構成するタスク)などの技術における基盤となります。
通常、こういった同一物同士の対応は画像からSIFTやORBなどの視点に関わらず不変となるような特徴表現を抽出することによって計算されます。画像間の対応を確実に確立する特徴により、「複数の写真からパノラマ写真を構築する画像スティッチング(image stitching)アプリケーション」や、「ビデオ内の対象物体を検出するテンプレートマッチングアプリケーション」が実現されます。(図1を参照)
本日、SIFTやORBに類似した汎用で局所的(local)な特徴記述子であるKNIFT(Keypoint Neural Invariant Feature Transform)を発表します。
KNIFTもSIFTやORBと同様に局所的な画像範囲をコンパクトにベクトルで表現可能です。画像に対して均一な拡大縮小、方向変換、および照明が変化が行われても不変です。
ただし、経験則的なエンジニアリング技法を参考に設計されたSIFTやORBとは異なり、KNIFTは、近接するビデオフレームから抽出された多数の局所的な範囲から直接学習したembeddingです。このデータ主導アプローチは複雑な実世界の空間的変換と照明変更を暗黙的にembeddingにエンコードします。
この結果、KNIFTの特徴記述子は、平行移動(affine)の歪みだけでなく、ある程度の遠近を伴った歪みに対しても、より堅牢であるように見えます。
私達はMediaPipe上でKNIFTを実装しオープンソースとして公開しました。以下のセクションでKNIFTベースのテンプレートマッチングのデモを紹介します。

図1:KNIFEを使用して動画内の「一時停止標識」を「一時停止標識のテンプレート画像」と照合したデモ
トレーニング方法
機械学習では、embeddingのトレーニングとは、大まかに言って、高次元ベクトル(画像範囲など)を比較的低次元のベクトル(特徴記述子など)に変換する対応関係(mapping)を見つけることを意味します。
理想的には、この対応関係には次の性質が必要です。すなわち、画像内のキーポイント周辺は、異なる視点または照明の変化があったとしても同じまたは非常に類似した記述子となる性質です。
現実世界のビデオは、このような対応関係を含んだトレーニングデータとして優れている(図3および図4を参照)事がわかりました。このようなembeddingをトレーニングするために、私達は定評のあるトリプレット損失(Triplet Loss、図2を参照)を使用しました。
各トリプレットは、アンカー(a)、ポジティブ(p)、およびネガティブ(n)の特徴ベクトルで構成され、これらは対応する画像範囲から抽出されます。d()は特徴空間でのユークリッド距離を示しています。
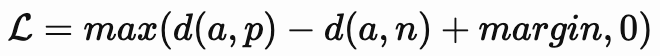
図2:トリプレット損失関数
トレーニングデータ
トレーニング用のトリプレットは、公開されているYouTube UGCデータセット内の全てのビデオクリップ(約1500)から抽出されました。
まず、既存の経験則的に手動設計されたローカル特徴検出器を使用してキーポイントを検出し、2つのフレーム間のアフィン変換を高精度で計算します。(図4を参照)
次に、この対応を使用してキーポイントのペアを見つけ、これらのキーポイントの周囲の画像範囲を抽出します。新しく識別されたキーポイントには、最初のステップで形状検証によって拒絶されたキーポイントが含まれる場合があることに注意してください。
一致した画像範囲のペア毎に、何らかの形式のデータ拡張(ランダムな回転や明るさの調整など)をランダムに適用して、アンカーとポジティブのペアを構築します。
最後に、別のビデオから任意の画像範囲をネガティブとしてランダムに選択し、このトリプレットの構築を完了します。(図5を参照)

図3:トレーニング用トリプレットをトリプレットを抽出するビデオクリップの例

図4:既存の局所的な特徴を使用してフレーム間の対応を見つけます

図5:上から下に、アンカー、ポジテイブ、ネガティブの各画像
3.MediaPipe KNIFT:テンプレートベースの画像検索を改善(1/3)関連リンク
1)developers.googleblog.com
MediaPipe KNIFT: Template-based feature matching
2)drive.google.com
Model Card Content: MediaPipe KNIFT(PDF)
3)google.github.io
MediaPipe KNIFT

