
1.Panoptic-DeepLab:総括的に風景を理解する新手法(2/2)まとめ
・Panoptic-DeepLabはエンコーダ、ASPP、デコーダ、予測ヘッドから構成される
・拡大畳み込みにより通常の畳み込みより物体の境界の詳細を保持する事ができている
・3つの学術データセットCityscapes、Mapillary Vista、COCOで優秀な成績を出せた
2.パノプティックセグメンテーションの設計
以下、ai.googleblog.comより「Improving Holistic Scene Understanding with Panoptic-DeepLab」の意訳です。元記事の投稿は2020年7月21日、Bowen ChengさんとLiang-Chieh Chenさんによる投稿です
アイキャッチ画像のクレジットはPhoto by Douglas Bagg on Unsplash
ニューラルネットワークの設計
Panoptic-DeepLabは4つの部品で構成されています。
(1)ImageNetで事前トレーニングされたエンコーダバックボーン。セマンティックセグメンテーションとインスタンスセグメンテーションの両処理で共有されます。
(2)DeepLabで使用されるものと同様のASPP(atrous spatial pyramid pooling)モジュール。
拡大畳み込み(atrous convolution)を使ってネットワークの各レイヤーで広い視野を維持して空間を意識したセグメンテーションを実行します。各処理で個別のモジュールをつかいます。
(3)各セグメンテーションタスクに固有のデコーダモジュール
(4)タスク固有の予測ヘッド
ImageNetで事前トレーニングされたエンコーダバックボーン(1)は、セマンティックセグメンテーションとインスタンスセグメンテーションの両アーキテクチャで共有される特徴マップを抽出します。
一般的に、特徴マップは、標準的な畳み込み処理を使用してバックボーンモデルによって生成されます。しかしこの処理は、出力マップの解像度を入力画像の解像度の1/32に減らすため、正確な画像セグメンテーションを行う用途には粗すぎます。
物体の境界の詳細を保持するために、代わりに、先端部分などの重要な特徴をより適切に保持できる拡大畳み込み(atrous convolution)を使用して、元の解像度の1/16の特徴マップを生成します。次に、2つのASPPモジュール(2)が続きます。各処理に1つあり、セグメンテーション用に様々な縮尺情報を捕捉します。
通常の畳み込み
■■■□□□□□
■■■□□□□□
■■■□□□□□
□□□□□□□□
□□□□□□□□
□□□□□□□□
拡大畳み込み(atrous convolution)
■□■□■□□□
□□□□□□□□
■□■□■□□□
□□□□□□□□
■□■□■□□□
□□□□□□□□
軽量デコーダモジュール(3)は、最新のDeepLabバージョン(DeepLabV3+)で使用されているモジュールに準拠していますが、2つの変更点があります。
最初に、追加の低レベルな特徴マップ(1/8スケール)をデコーダーに再投入します。
これは、バックボーンによって出力される最終的な特徴マップでは大幅に劣化してしまう可能性がある元画像(物体の境界など)の空間情報を保持するのに役立ちます。第2に、デコーダーは通常の3 x 3カーネルを使用する代わりに、5 x 5の深さ方向に分離可能なたたみ込みを使用します。これにより、最小限の追加計算コストでパフォーマンスがいくらか向上します。
2つの予測ヘッド(4)は、それぞれのタスクに合わせて調整されています。セマンティックセグメンテーション用のヘッドは、標準のブートストラップされたクロスエントロピー損失関数の加重バージョンを採用しています。これは、各画素に異なる加重を行います。小規模物体のセグメンテーションにより効果的であることが証明されています。
インスタンスセグメンテーションヘッドは、物体のクラスに関する知識なしに、物体の実体の重心と周囲の画素間のズレを予測するようにトレーニングされ、クラスにとらわれないインスタンスマスクを形成します。
結果
Panoptic-DeepLabの有効性を実証するために、3つの一般的な学術データセットCityscapes、Mapillary Vista、およびCOCOで検証を行いました。Panoptic-DeepLabはシンプルな設計ではありますが、タスク専用の微調整をせずとも、Cityscapesの3つのタスク全て(セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーション)で1位にランクされました。
更に、Panoptic-DeepLabは、ICCV 2019 Joint COCO and Mapillary Recognition Challenge WorkshopのMapillary Panoptic SegmentationトラックでBest Result、Best Paper、およびMost Innovativeの各賞を受賞しました。
2018年の優勝者のスコアを1.5%、かなり上回っています。最後に、Panoptic-DeepLabは、COCOデータセットに新しい最先端の手法(つまり、境界ボックスのない)パノプティックセグメンテーション結果を設定する事が出来、これとMask R-CNNを使った他の手法と比較できます。
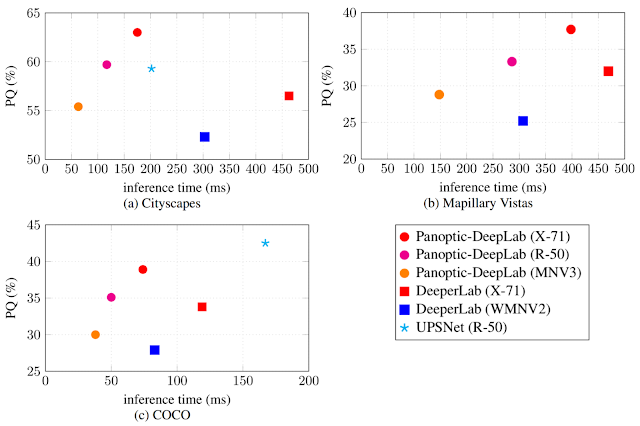
3つのデータセットで比較した精度(PQ)と速度(GPU inference time)
まとめ
シンプルな設計とわずか3つの損失関数で実装されたPanoptic-DeepLabは、Mask R-CNNを使った他の手法よりも高速でありながら、最先端のパフォーマンスを実現します。
まとめると、いくつかの公開ベンチマークで最先端のパフォーマンスを達成し、ほぼリアルタイムに実行可能なエンドツーエンドの推論速度を提供する最初のシングルショットパノプティックセグメンテーションモデルを開発しました。私達はシンプルで効果的なPanoptic-DeepLabが強固な基盤を確立し、研究コミュニティにさらなる利益をもたらすことを願っています。
謝辞
Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Florian Schroff及びGoogleモバイルビジョンチームのサポートと貴重な議論に感謝します。
3.Panoptic-DeepLab:総括的に風景を理解する新手法(2/2)関連リンク
1)ai.googleblog.com
Improving Holistic Scene Understanding with Panoptic-DeepLab
2)arxiv.org
Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation


コメント