
1.Context R-CNN:過去に撮影された写真を参照して仕掛けカメラの物体検出能力を改善(2/2)まとめ
・Context R-CNNはFaster R-CNNアーキテクチャの中にコンテキストメモリバンクを汲み込んで実現
・コンテキストメモリバンクに保存された設置場所に固有の情報をattentionを使って物体と関連付ける
・この仕組みによりFaster R-CNNでは捕捉が難しい物体もContext R-CNNでは捕捉できる
2.Context R-CNNの仕組み
以下、ai.googleblog.comより「Leveraging Temporal Context for Object Detection」の意訳です。元記事の投稿は2020年6月26日、Sara BeeryさんとJonathan Huangさんによる投稿です。
アイキャッチ画像のクレジットはAdam Mosley for sharing their work on Unsplash.
Context R-CNNモデル
Context R-CNNは、固定カメラで撮影された画像内の高度な相関関係を利用して、困難なデータの分類パフォーマンスを向上させます。人間が付与したラベルを追加せずとも、新規に設置したカメラ内で一般化を改善するように設計されています。
これを実現するために、一般的な2段階物体検出アーキテクチャであるFaster R-CNNを応用しています。
「カメラが設置された場所に固有の情報(コンテキスト)」を抽出するためには、まず重みを凍結した特徴抽出機を使用して、長い期間(最大1か月以上)にわたって撮影された画像からコンテキストメモリバンク(contextual memory bank)を構築します。
次に、Context R-CNNを使用してコンテキストメモリバンクから関連するコンテキストを集約し、各画像で物体を検出します。集約したコンテキストは、(前述の例のヌーを覆い隠すような濃い霧など)厳しい条件下で物体を検出する際に役立ちます。
コンテキストの集約はattentionを使用して実行されます。これは、固定監視カメラの設定によくある、まばらで不規則なタイミングで撮影される写真に対して堅牢です。
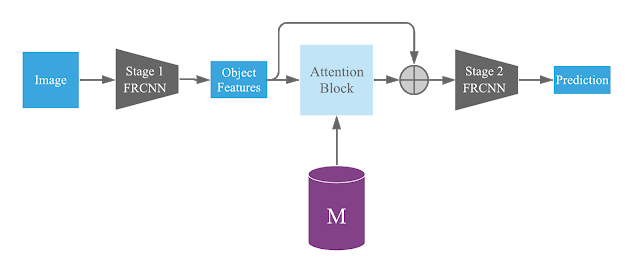
Context R-CNNがどのようにFaster R-CNNアーキテクチャ内に長期視点のコンテキストを組み込むかを示す俯瞰図。Mはコンテキストメモリバンクです。
Faster R-CNNでは、第1ステージで潜在的な物体を提案し、第2ステージで各提案された物体を「背景」または「分類すべきターゲットクラスの1つ」として分類します。
Context R-CNNでは、提案された物体をFaster R-CNNの最初の段階から取得します。それぞれについて、類似性ベースのattentionを使用して、コンテキストメモリバンク(M)の各特徴が現在の物体にどの程度関連しているかを判断します。
そして、Mの関連性の加重和を取り、それを元の物体の特徴に追加することにより、物体毎にコンテキスト特徴(context feature)を構築します。
次に、コンテキスト情報が追加された各物体が、Faster R-CNNの第2ステージを使用して最終的に分類されます。
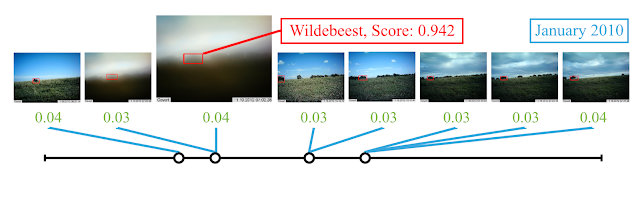
Context R-CNNは、最大1か月分の過去写真を利用して前述の困難なヌー写真を正しく分類できます。
緑の値は、境界ボックスで協調された各物体に対応するattentionの重みです。

Faster R-CNN(左)とContext R-CNN(右)を比較すると、Context R-CNNは難しい物体を捕捉できています。上から木陰の象、薄明かりの中の2匹のインパラ、中心から離れたベルベットモンキー(セレンゲティ国立公園のスナップショットから引用)
性能評価
Context R-CNNをSnapshot Serengeti(SS)データセットとCaltech Camera Traps(CCT)データセットを使ってテストしました。
どちらも、仕掛けカメラを使って撮影した動物種の生態データセットですが、地理的領域(タンザニア 対 米国南西部)が非常に異なっています。
各データセットを使ってFaster R-CNNと比較した結果は、以下の表で確認できます。注目すべき点は、SSではmAP(mean average precision)が47.5%増加し、CCTでは34.3%相対mAP増加した事です。
また、Context R-CNNをS3D(a 3D convolution based baseline)と比較したところ、パフォーマンスが44.7%mAPから55.9%mAP(25.1%の相対増加)に向上することを確認します。
最後に、参照する過去時間の範囲を分単位から月単位へと長くするにつれて、パフォーマンスが向上することがわかります。
| SS | CCT | |||
| Model | mAP | AR | mAP | AR |
| single frame Faster R-CNN | 37.9 | 46.5 | 56.8 | 53.8 |
| Context R-CNN | 55.9 | 58.3 | 76.3 | 62.3 |
単一画像のみを使って分類を行うFaster R-CNNとの比較
mAPとARを示します。
進行中および将来の研究
私達は、Wildlife Insightsプラットフォーム内にContext R-CNNを実装し、仕掛けカメラを介した大規模な地球規模の生態学的モニタリングを促進する作業に取り組んでいます。
また、CVPR Fine-Grained Visual Recognitionワークショップで毎年開催されるiWildCam種識別コンテストなどのコンテストを主催しています。こういったコンテストは、これらの課題にコンピュータービジョンコミュニティの注目を集めるのに役立ちます。
固定カメラを使った自動種識別で直面した課題は、生態学以外の研究分野でも発生する課題です。固定カメラだけでなく、音声センサーやソナーデバイスなど生物多様性を監視するために使用される他の固定センサーも同様です。私達の手法は一般的であり、Context R-CNNによるセンサー毎に設置場所固有の環境を考慮するアプローチは、固定センサーに有益であると予想しています。
謝辞
この投稿は、作者および次の主要な貢献者グループの成果を反映しています。Vivek Rathod, Guanhang Wu, Ronny Votel。Zhichao Lu, David Ross, Tanya Birch, the Wildlife Insights AI team、及び Pietro Perona, the Caltech Computational Vision Labにも感謝します。
3.Context R-CNN:過去に撮影された写真を参照して仕掛けカメラの物体検出能力を改善(2/2)関連リンク
1)ai.googleblog.com
Leveraging Temporal Context for Object Detection
2)arxiv.org
Context R-CNN: Long Term Temporal Context for Per-Camera Object Detection
3)github.com
models/research/object_detection

