
1.Big Transfer(BiT):視覚タスクで大規模な事前トレーニングを活用(1/3)まとめ
・視覚タスクにおけるラベル付きデータの欠如を軽減する一般的なアプローチは事前学習
・事前学習は実際にかなりうまく機能するが非常に大規模データセットを扱う際の知見が足りない
・事実上の標準(ILSVRC-2012)を超える規模のデータセットで効果的に事前学習する手法を研究した
2.BiTとは?
以下、ai.googleblog.comより「Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision」の意訳です。元記事の投稿は2020年5月21日、Lucas BeyerさんとAlexander Kolesnikovさんによる投稿です。
NeurIPS 2019の「その転移学習は本当に有用なのか?」の話を受けて出てきた、視覚タスクにおける大規模転移学習の有効性を調査したお話です。
アイキャッチ画像はケモノの形相を見せつつ笹に食いつくパンダでクレジットはPhoto by michael schaffler on Unsplash。食いつく=byte、byteの過去形と過去分詞がbitからの連想です。
コンピュータービジョンの研究者にとって一般的な制限は、最新のディープニューラルネットワークは常により多くのラベル付けされたデータに飢えているということです。現在の最先端のCNNは、100万を超えるラベル付けされた画像で構成されるOpenImagesやPlacesなどのデータセットでトレーニングする必要があります。 ただし、多くのアプリケーションでCOCOデータセットなどに匹敵する量のラベル付きデータを収集することは、平均的な機械学習開発者にとって法外なコストがかかる可能性があります。
コンピュータービジョンタスクにおけるラベル付きデータの欠如を軽減する一般的なアプローチは、一般的な画像を集めたデータセット(ImageNetなど)で事前学習したモデルを使用することです。
これは、一般的なデータで学習した視覚的特徴を、自分が関心を持っている視覚タスクに再利用するというアイディアです。
この事前学習は実際にかなりうまく機能しますが、それでも、「新しい概念をすばやく把握する能力」及び「異なる状況で学習した概念を理解して適用する能力」の両方がまだ足りません。
私達はBERTとT5が自然言語分野で大きな進歩を達成した際の姿勢を見習って、大規模な事前トレーニングがコンピュータービジョンモデルのパフォーマンスを向上させることができると信じています。
論文「Big Transfer (BiT): General Visual Representation Learning」では、事実上の標準(ILSVRC-2012)を超える規模の画像データセットを使用し、一般的な特徴を効果的に事前トレーニングするアプローチを考案します。
特に、事前トレーニングデータの量が増えるにつれて、正規化レイヤーを適切に選択し、モデルが大きなデータを許容できるようにモデル容量を拡大させる事の重要性を強調します。
私たちのアプローチは、少数ショット認識設定や最近発表された「現実世界の」ObjectNetベンチマークなど、幅広い新しい視覚タスクに適応できる前例のないパフォーマンスを示しています。
tensorflow2、Jax、PyTorch用のコードとともに、パブリックデータセットで事前トレーニングされた最高のBiTモデルをgithubで共有できることを嬉しく思います。これにより、分類したいクラス毎のデータがほんの一握りのラベル付き画像しかなくても、誰でも関心のあるタスクで最先端のパフォーマンスに到達できます。
事前トレーニング
データの規模の影響を調査するために、3つのデータセットを使用して、事前トレーニングを行う際の一般的な設定(アクティベーションと重みの正規化、モデルの幅と深さ、トレーニングスケジュールなど)をどのように設計選択するかを再検討します。
使用するデータセットは、ILSVRC-2012(1000クラスの128万画像)、ImageNet-21k(2.1万クラスの1400万画像)、およびJFT(1.8万クラスの3億画像)の3つです。
重要な事は、これらのデータセットを使用して、以前は十分に調査されていなかった大規模なデータに置ける事前学習の効果ついて集中して調べる事です。
まず、データセットのサイズとモデル容量の間の相互作用を調査します。これを行うために、シンプルで再現性がありながらパフォーマンスの高い従来のResNetアーキテクチャをトレーニングします。
標準的な50層の深さを「R50x1」から4倍の幅152層の深さ「R152x4」までのバリアントをトレーニングします。 重要な観察は、より多くのデータから利益を得るために、モデルの容量を増やす必要があることです。 これは、下の図の左側のパネルにある赤い矢印で例示されています
前述の3つの各データセットを使って、50層の深さを持つ標準の「R50x1」、及び「R50x1」の幅を4倍まで拡張して152層の深さを持つ「R152x4」まで様々な版を事前学習させます。
重要な観察は、より多くのデータを活用するためには、モデルの容量を増やす必要があることです。 これは、下の図の左側のパネルにある赤い矢印で例示されています
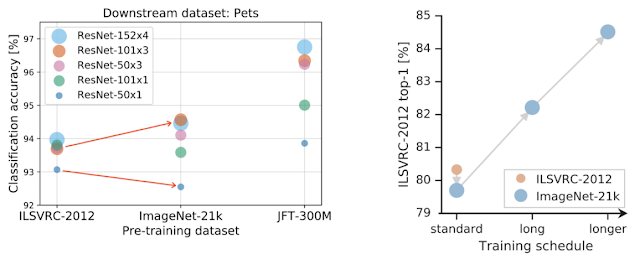
左図:事前トレーニングで大きなデータセットを効果的に使用するには、モデルの容量を増やす必要があります。赤い矢印はこれを示しています。大きなImageNet-21kで事前トレーニングすると小さなアーキテクチャ(小さな○)は性能が悪化しますが、大きなアーキテクチャ(大きな○)は性能が改善します。
右図:より大きなデータセットのみで事前トレーニングを行っても、必ずしもパフォーマンスが向上するわけではありません。例えば、ILSVRC-2012より大きなImageNet-21kを使っても性能が改善するわけではありません。しかし、計算量を増やしてトレーニングを長くすると、パフォーマンスの向上が顕著になります。
2番目の、更に重要な所見は、トレーニングの期間が重要だという事です。
利用可能な計算機資源を調整せずに大きなデータセットを使って事前トレーニングを行い、長時間トレーニングを行っても、パフォーマンスが低下する可能性があります。 ただし、新しいデータセットにスケジュールを適合させることにより、大幅な改善が可能になります。
調査段階で、パフォーマンスの向上に不可欠な別の変更を発見しました。
バッチ正規化(BN:Batch Normalization、アクティベーションを正規化することでトレーニングを安定させる一般的に使用されるレイヤー)をグループ正規化(GN:Group Normalization)で置き換える事が、大規模な事前トレーニングに有益であることを示します。
まず、BNの状態(ニューラルアクティベーションの平均と分散)は事前トレーニングから転移する際に調整が必要ですが、GNは状態を持たないので、この困難を回避できます。
第2に、BNはバッチレベルの統計を使用します。これは、大規模なモデルでは避けられない、デバイス毎に分割した小さなバッチサイズでは信頼できなくなります。GNはバッチレベルの統計も計算しないため、この問題も回避できます。
安定した動作を保証するための重みの標準化手法の使用など、技術的な詳細については、私達の論文を参照してください。

事前トレーニング戦略の概要
標準のResNetを使用し、深さと幅を増やし、「BatchNorm(BN)」を「GroupNormと重みの標準化(GNWS:GroupNorm and Weight Standardization)」で置き換えます。そして、更に多くの反復を行うために非常に大規模で汎用的なデータセットを使ってトレーニングします。
3.Big Transfer(BiT):視覚タスクで大規模な事前トレーニングを活用(1/3)関連リンク
1)ai.googleblog.com
Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision
2)arxiv.org
Big Transfer (BiT): General Visual Representation Learning
Group Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Weight Standardization
Self-training with Noisy Student improves ImageNet classification
Exploring the Limits of Weakly Supervised Pretraining
3)www.image-net.org
Large Scale Visual Recognition Challenge 2012 (ILSVRC2012)
4)objectnet.dev
ObjectNet
5)github.com
google-research/big_transfer
6)blog.tensorflow.org
BigTransfer (BiT): State-of-the-art transfer learning for computer vision

