
1.機械学習を用いて賢い繊維を実現(2/3)まとめ
・e繊維はシンプルなジェスチャーと操作に対して応答を行う事を設計ガイドラインを定めている
・12人の実験参加者から収集したジェスチャーを機械学習させ94%のジェスチャー認識精度を達成
・一般的なジェスチャーは指紋センサーの登録と同程度の30秒未満の時間で学習可能
2.ジェスチャーの学習
以下、ai.googleblog.comより「Enabling E-Textile Microinteractions: Gestures and Light through Helical Structures」の意訳です。元記事の投稿は2020年5月15日、Alex Olwalさんによる投稿です。
それと、都道府県別の時系列COVID-19 Community Mobility Reportsを5月16日(土)までのデータにひっそり更新してます。14日に39県で緊急事態宣言解除してるので解除後の初の週末となるデータです。解除後データでは一部のデータが欠落していて、これはミスなのか、それとも本当にデータ不足なのかがやや気になるところです。(例えば、5/15の住居データに欠けが多いです。都道府県単位のデータなのでないとは思うのですが、皆が一気にStayHomeを止めていたらデータ不足となる可能性はあるかもしれません)
2020年5月30日追記)都道府県別の時系列COVID-19 Community Mobility Reportsを5月21日(木)版に更新しました。16日データに確認された欠落は補完されていました。
アイキャッチ画像のクレジットはPhoto by K8 on Unsplash
対話的操作と設計のガイドライン
e繊維の構造により、布製コードがタッチセンサーを内包する事ができるようになりますが、その柔らかさと順応性のため、固い表面を持つ物体に内包されるタッチセンサーに比べて操作に制限が発生します。
e繊維が今までないユニークな素材である事を念頭に、私達は以下のような設計ガイドラインを定めました。
・シンプルなジェスチャー
ユーザーが一度だけジェスチャーを行うか、繰り返しジェスチャーを行う事で、e繊維の操作を行えるように設計します。
・操作に対して応答を行う(Closed-loop feedback)
ユーザーがe繊維の使い方を発見する事を手助けするため、ユーザーの操作に対して常に何らかの応答(紐が光るなど)を得られるようにしたいと考えています。可能な場合は、視覚、触覚、および音声による応答を提供します。
私達はこれらの原則をe繊維の設計思想に取り込み、e繊維は感知能力(物体の接近、接触領域、接触時間、回転、圧力)に基づいて対話的操作を実現します。
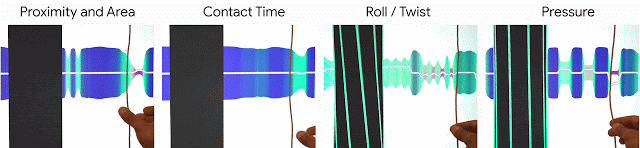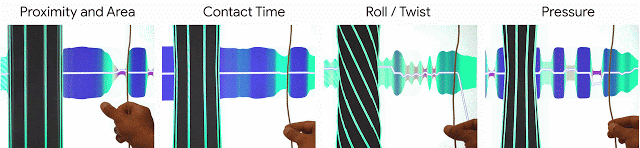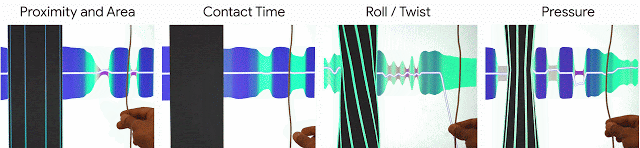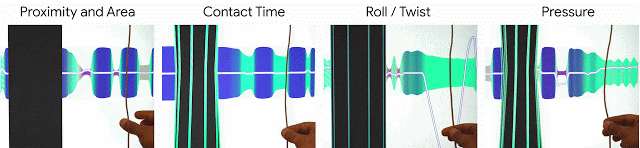
私達のe繊維は、物体の接近、接触領域、接触時間、回転、圧力)に基づいて対話的操作を実現します。
様々な強さで色を表示できる光ファイバーを含める事で、ユーザーに動的にリアルタイムに応答を提供できます。

組み紐された光ファイバーの発光は、光の動きに方向性があるかのような錯覚を生み出します。
サッと動かす動作(フリックとスライド)と掴む動作(ピンチ、グラブ、パット)
私達はジェスチャーを抽出する研究を行い、新たなジェスチャーを認識する機会を得ました。この結果に触発されて、5つの動きを調査することにしました。フリックとスライドに基づく動きと一度だけ触る動作に基づく動き(ピンチ、グラブ、パット)です。
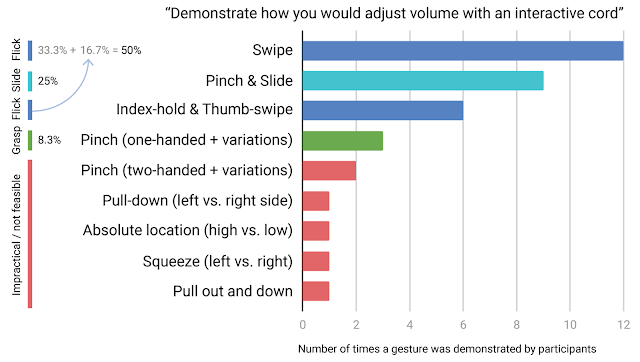
ジェスチャー抽出の研究
「もし、操作可能な紐があったとしてそれを使って音量を調整してみてください」と依頼して得られたジェスチャーの一覧
訳注:以下のイメージです。
フリック:素早く動かしたり弾いたりする操作
スライド:触れたままで左右、上下など一方方向に動かす操作
ピンチ:つまむ操作
グラブ:つかむ操作
パット:軽く叩く、抑える操作
12人の実験参加者からデータを収集した結果、864個のジェスチャーサンプルを得ました。(12人の参加者がそれぞれ8つのジェスチャーを実行し、それを9回繰り返しました)それぞれ16の特徴を線形補間し、80の観測値を時系列で補間しています。
個人差に対応するため、参加者には私達からジェスチャーに対するフィードバックをせず、各々独自のスタイルで8つのジェスチャーを実行しました。ジェスチャーの分類は、ユーザーのスタイル(触る)、好み(つまむ/つかむ方法)、および生体構造(手のサイズなど)に大きく依存するためです。
従って、私達のジェスチャー検出機構は、参加者間で違いのある個々人のやり方を可能にするユーザー依存のトレーニング用に設計されました。例えば、時計回り/反時計回りなど回転に一貫性がなかったり、ジェスチャーが時間的に重複するケースです(例:素早くさっと画面を撫でる動作(フリック)をした後に撫でた後に画面にそのまま指を置いたままにする動作(フリックアンドホールド)、および同様にピンチ(摘んで)してグラブ(掴む))
個々のユーザーに依存しないシステムであれば、例えば、操作に一貫性をもたらすためにより厳密な指示を行ったり、より大きな母集団からデータを取得したり、より多様な実験を行い、これらの違いに対処する必要があります。操作訓練中にリアルタイムに指示をする事は、ユーザーが操作を習得する際の負荷を軽減する事に役立ちます。
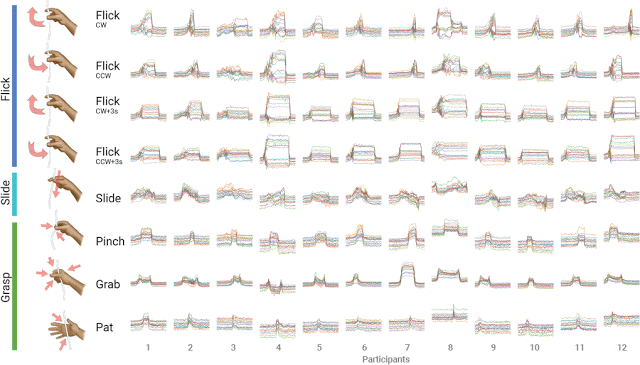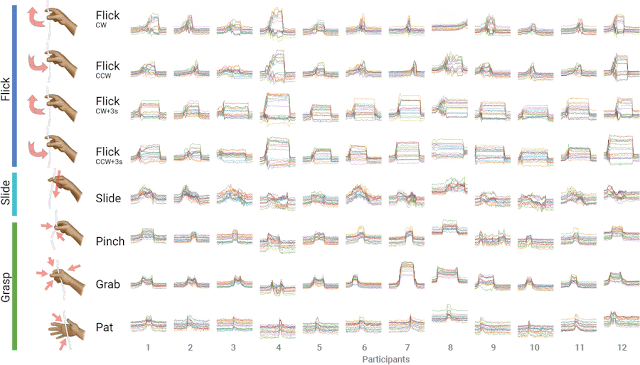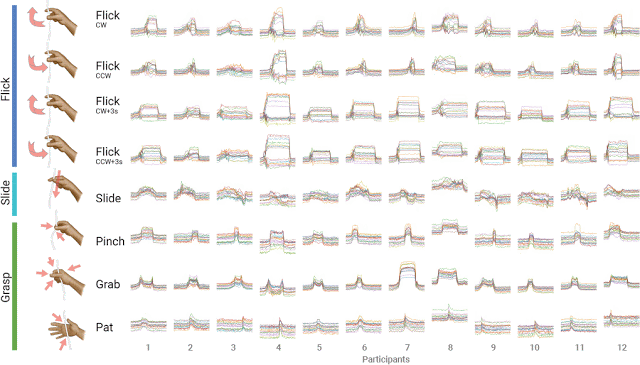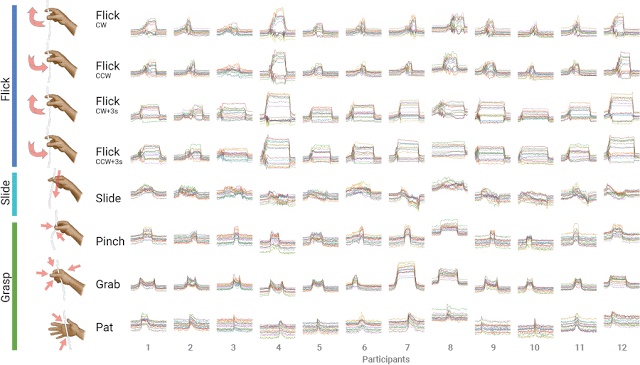
12人の参加者(横軸)が、8つのジェスチャー(縦軸)に対して9回繰り返し(アニメで表現)ました。
各イメージは、時系列で80の観測値を補間された16の特徴ベクトルを重ねて表示しています。
8回分のデータでトレーニングし、1回分でテストすることにより、ジェスチャー全体で各ユーザーの相互検証を行いました。これをテストデータを9回置換して行った結果、94%のジェスチャー認識精度を達成しました。このような低解像度のセンサー基盤(8つの電極)によって実現されたジェスチャー表現である事を考えると、この結果は非常に有望です。
ここで注目に値するのは、繰り返し検出基盤固有の相関性が、機械学習の分類に適していることです。
私達の研究で使用されている機械学習分類器は、限られたデータで迅速なトレーニングを可能にし、ユーザー依存の対話的システムを合理的なシステムにしています。私達の経験では、一般的なジェスチャーのトレーニングには30秒未満しかかかりません。これは、指紋センサーのトレーニングに必要な時間に相当します。
3.機械学習を用いて賢い繊維を実現(2/3)関連リンク
1)ai.googleblog.com
Enabling E-Textile Microinteractions: Gestures and Light through Helical Structures
2)dl.acm.org
E-Textile Microinteractions
