
1.Meta-Dataset:少数ショット学習用のデータセットのためのデータセット(3/3)まとめ
・Meta-Datasetを使った研究によりサポートデータの数とアルゴリズムの重要性が判明
・様々なモデルは、微調整時に提供されるサポートデータが特定の数の際に最もよく機能する事が判明
・複数データセットを使ってメタ学習するとパフォーマンスが悪化する事もあり得る
2.サポートデータを使いこなす能力
以下、ai.googleblog.comより「Announcing Meta-Dataset: A Dataset of Datasets for Few-Shot Learning」の意訳です。元記事は2020年5月13日、Eleni TriantafillouさんとVincent Dumoulinさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Fabrizio Verrecchia on Unsplash
(2)一部のモデルは、他のモデルよりもサポートデータを使いこなす能力があります。
各テストタスクで微調整時に使用可能なサンプル数(サポートデータ数)を様々に変更して、モデルのパフォーマンスがどうなるかを分析しました。その結果、興味深いトレードオフが明らかになりました。
様々なモデルは、微調整時に提供されるサポートデータが特定の数の際に最もよく機能します。
使用可能なサンプル数(ショット数)が非常に少ない場合、一部のモデル(ProtoNetや私達が提案するfo-Proto-MAMLなど)が他のモデルより優れていることがわかりました。
ただし、他のモデル(例えば、Finetune baseline)は、サンプル数が非常に少ないタスクにはあまり適していませんが、与えられた数が多いほど迅速に改善します。
しかしながら、現実世界ではテスト時に利用できるサンプルの数が事前にわからない場合もあるため、特定の状況を過度に想定する事は避け、任意の数のサンプルを最大限に活用できるモデルを特定したいと考えています。
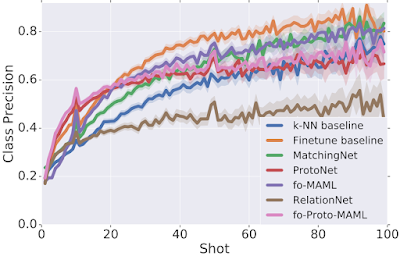
パフォーマンス(Y軸)と微調整時に使用可能なサンプル数(X軸)の関係
パフォーマンスは、各クラスの分類精度(正しくラベル付けされたサンプルの比率をクラス間で平均化)で測定しています。
(3)メタ学習の際に使用するアルゴリズムは、メタ学習そのものより、パフォーマンスに大きな違いを生みます。
メタ学習の利点を測定するための新しいベースラインセットを開発しました。
具体的には、それぞれのメタ学習に対して、同じアルゴリズムを適用する「メタ学習を行っていない推論」です。
特徴抽出器を事前トレーニングし、評価時にのみ、それらの特徴に対応するメタ学習と同じアルゴリズムを適用するのです。
ImageNetのみを使ってトレーニングする場合、メタ学習は多くの場合少し役立つか、少なくともそれほど害はありませんが、全てのデータセットを使ってトレーニングする場合、結果は様々です。
これは、特に複数データセットを使用するメタ学習を理解して改善するために、更なる研究が必要であることを示唆しています。
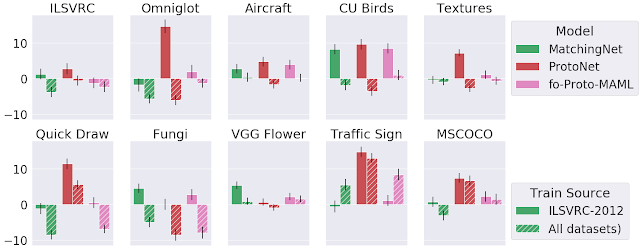
3つの異なるモデルを2つのデータセット(「ImageNet(ILSVRC-1012)のみ(棒グラフ)」または「全てのデータセット(斜め線が入った棒グラフ)」)でメタ学習した際のパフォーマンスの向上
各バーは「メタ学習」と「推論のみ」の違いを表現しており、正の値はメタ学習によりパフォーマンスが向上した事を示しています。
結論
メタデータセットは、少数ショット分類に新しい課題をもたらします。今回の初期調査で、既存手法の限界が明らかになり、追加の調査が必要になりました。
最近の研究で、Meta-Datasetを使ったエキサイティングな結果が既に報告され始めています。例えば、巧妙に設計されたタスク条件付け(cleverly-designed task conditioning)の使用、より高度なハイパーパラメータの調整、事前トレーニングとメタ学習の利点を組み合わせた「メタベースライン(meta-baseline)」、特徴選択により各タスクの普遍的な特徴表現の追求など。
Meta-Datasetが、機械学習のこの重要なサブフィールドの研究の促進に役立つことを願っています。
謝辞
Meta-Datasetは、Eleni Triantafillou, Tyler Zhu, Vincent Dumoulin, Pascal Lamblin, Utku Evci, Kelvin Xu, Ross Goroshin, Carles Gelada, Kevin Swersky, Pierre-Antoine Manzagol 及び Hugo Larochelleによって開発されました。
本ブログ投稿に関する有益なガイダンスを提供してくれたPablo Castro、実り多い議論とfo-MAMLの実装の正確さを保証してくれたChelsea Finn、改修元の初期データセットコードを提供してくれたZack NadoとDan Moldovan、モデルのランキングに関する問題を発見してくれたCristina Vasconcelosに感謝します。John Bronskillは、MAMLでより大きな内部ループ学習率を試す事を提案してくれ、それは実際にfo-MAMLの結果を大幅に改善する事に貢献しました。
3.Meta-Dataset:少数ショット学習用のデータセットためのデータセット(3/3)関連リンク
1)ai.googleblog.com
Announcing Meta-Dataset: A Dataset of Datasets for Few-Shot Learning
2)github.com
google-research/meta-dataset
3)openreview.net
Are Few-shot Learning Benchmarks Too Simple ?
4)arxiv.org
Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation


コメント