
1.Meta-Dataset:少数ショット学習用のデータセットのためのデータセット(2/3)まとめ
・Meta-Datasetは少数ショット画像分類用のこれまでで最大規模の複数データセットを交えたベンチマーク
・「事前トレーニング」と「メタ学習」を使ってMeta-Datasetを使って従来モデルの評価を実施
・既存のアプローチは、異種のトレーニングデータを活用して一般化を促進出来ていない事がわかった
2.Meta-Datasetによる検証
以下、ai.googleblog.comより「Announcing Meta-Dataset: A Dataset of Datasets for Few-Shot Learning」の意訳です。元記事は2020年5月13日、Eleni TriantafillouさんとVincent Dumoulinさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Fabrizio Verrecchia on Unsplash
最近の論文「Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation」では、mini-ImageNetを使ったトレーニングと様々なデータセットの評価について調査していますが、Meta-Datasetは、少数ショット画像分類用のこれまでで最大規模の組織化された、複数データセットを交えた、ベンチマークです。
また、様々な特性と難易度のタスクを生成するサンプリングアルゴリズムも備えています。各タスクのクラスの数、クラス毎に使用可能なサンプル数を変えることにより、クラスに不均衡を導入し、一部のデータセットでは、各タスクのクラス間の類似度を変化させる事もできます。Meta-Datasetのテストタスクの例を以下に示します。

Meta-Datasetのテストタスク
前述のmini-ImageNetタスクとは異なり、Meta-Datasetの様々なタスクは、様々なデータセットのテストクラスから派生させたものです。更に、クラスの数とサポートセットのサイズはタスク間で異なり、サポートセットはクラス間でバランスが取れていない場合があります。
Meta-Datasetを使った初期調査と調査結果
少数ショット学習の例として良く取り上げられる「事前トレーニング」と「メタ学習」を使ってMeta-Datasetのベンチマークを行いました。
事前トレーニングでは、まず、教師あり学習を使用してクラスを分類する分類器(ニューラルネットワークによる特徴抽出とそれに続く線形分類器)を単純にトレーニングします。
次に、事前トレーニング済みの特徴抽出器を微調整して新しいタスク固有の線形分類器をトレーニングするか、最近傍比較(この場合最も近いサポートサンプルのラベルが予測となります)を使用して、テストタスクのサンプルを分類します。
事前トレーニングは、少数ショット分類の関連文献では「ベースライン(新手法を比較する際の基準モデル)」の扱いを受けているにもかかわらず、最近注目を集め、競争力のある結果を出しています。
一方、メタ学習では多数の「トレーニングタスク」を作成します。トレーニングタスクの目標は、最終的に実行する各タスクを適切に実行する事です。そのため、各タスクに関連するサポートセットとそのクエリを使用して、タスクを解決するために必要な能力を習得させます。
各トレーニングタスクは、トレーニング時のクラスのサブセットとそのクラスのいくつかのサンプルをランダムにサンプリングし、サポートセットとそのクエリセットが作成されます。
以下に、Meta-Datasetで事前トレーニングおよびメタ学習モデルを評価した結果の一部をまとめます。
(1)既存のアプローチでは、異種のトレーニングデータを活用する事が出来ていません
私達は、より広範なトレーニングデータを使用することによりどの程度一般化が促進されるかを測定するため、ImageNetのトレーニングクラスのみを使用したモデルとMeta-Datasetに含まれる全てのトレーニングクラスを使ったモデルを比較しました。事前トレーニングとメタ学習の両方で行っています。
ImageNetで学習した特徴は他のデータセットにすぐに転移出来るため、ImageNetを選択しました。
全てのモデルで評価に使ったタスクは、トレーニング時に使用されたデータセットから抽出されたクラスで、少なくとも2つのデータセットは評価のために完全に抽出されています。(つまり、これらのデータセットのクラスはトレーニングには一切使用されませんでした)
異種混合ではありますが、より多くのデータで行ったトレーニングは、テストセットでより一般化される事が期待できます。しかしながら、これは常に当てはまるわけではありませんでした。
具体的には、以下の図は、メタデータセットの10個のデータセットのテストタスクにおける様々なモデルの精度を示しています。
ImageNetのみではなく、全てのデータセットでトレーニングすると、手書き文字/いたずら書き(OmniglotとQuickdrawデータセット)のテストタスクのパフォーマンスが大幅に向上することがわかります。これらのデータセットは視覚的にImageNetと大きく異なるため、これは妥当な結果です。
ただし、自然画像データセットを使ったテストタスクの場合、ImageNetでトレーニングするだけで同等の精度を得ることができ、現在のモデルでは異種混合データを効果的に活用して性能を改善できていないことがわかります。
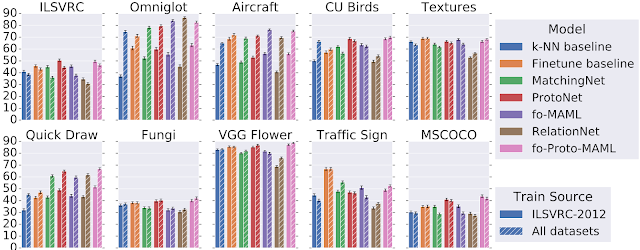
ImageNet(ILSVRC-2012)のみまたは全てのデータセットでトレーニングした後の各データセットのテストパフォーマンスの比較結果
3.Meta-Dataset:少数ショット学習用のデータセットためのデータセット(2/3)関連リンク
1)ai.googleblog.com
Announcing Meta-Dataset: A Dataset of Datasets for Few-Shot Learning
2)github.com
google-research/meta-dataset
3)openreview.net
Are Few-shot Learning Benchmarks Too Simple ?
4)arxiv.org
Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation
