
1.COVID-19 Research Explorer:新型コロナウィルス関連文献に特化した検索システムまとめ
・Googleが新型コロナウィルス関連文献を検索しやすくするCOVID-19 Research Explorerを発表
・自然な英文で検索可能なセマンティック検索と検索結果に対して追加質問ができる機能が実装されている
・厳密にはキーワード検索とニューラル検索を組み合わせたHybrid Term-Neural Retrieval Model
2.COVID-19 Research Explorerとは?
2020年8月追記)COVID-19 Community Mobility Reports関係はこちらのページにまとめました。
以下、ai.googleblog.comより「An NLU-Powered Tool to Explore COVID-19 Scientific Literature」の意訳です。元記事の投稿は2020年5月4日、Keith Hallさんによる投稿です。
アイキャッチ画像は江戸時代に疫病の到来を予言し、自らの写しを世に広めよと警告したと伝えられ、現在インターネット上でアイドルになっている妖怪アマビエの内製写し
COVID-19のパンデミックにより、世界中の科学者や研究者がこの病気を理解し、これと戦うために膨大な量の新しい研究を発表しています。研究の量は非常に勇気づけられる事ですが、科学者や研究者が新しい出版物の急速な発行ペースに追いつく事が難しい場合があります。
従来の検索エンジンは「米国のCOVID-19の症例は何件ですか?」のような一般的なCOVID-19に関する情報をリアルタイムに検索するためには優れたツールですが、研究目的で行われる検索では背後にある真の意図を理解できない可能性があります。
更に、COVID-19の既存の科学文献を従来のキーワードベースのアプローチで検索する際に、複雑なキーワードを組み合わせて求める情報を正確に指定する事は困難な作業になる可能性があります。
この問題を解決するために、COVID-19関連情報をセマンティック検索(訳注:指定キーワードの存在有無ではなく、検索者の意図を理解して情報を捜す検索)用インターフェイスであるCOVID-19 Research Explorerをリリースしました。
COVID-19 Research ExplorerはCOVID-19 Open Research Dataset(CORD-19)の上に構築されており、これには、50,000を超えるジャーナルとプレプリントが含まれています。私達は、科学者や研究者がCOVID-19関連の質問に対する回答や証拠を探すために記事を効率的に調査できるように本ツールを設計しています。
ユーザーが最初の質問をすると、ツールは(従来の検索と同様に)一連の論文を返すだけでなく、質問に対する回答となっている可能性が高い論文を抜粋して強調表示します。
ユーザーは強調表示された箇所を確認し、その論文が更に読む価値があるかどうかをすばやく判断できます。更にユーザーが論文と強調表示箇所に満足した場合、回答として表示された論文に対して追加の質問を入力する事ができます。
以下のアニメーションを見て、検索の例と追加質問のやり方を確認してください。これらの機能が知識の探究と科学的仮説のエビデンスの効率的な収集を促進することを願っています。
セマンティック検索
COVID-19 Research Explorerを強化する重要なテクノロジーは、セマンティック検索です。セマンティック検索は、入力文と検索対象文書の間に同じ単語が存在しているか否かを調べるのではなく、入力文の意味を本当に理解し、検索の背後にあるユーザーの真の意図と関連しているか否かを調べます。
「What regulates ACE2 expression?」という検索文を考えてみてください。これは単純な質問のように見えますが、入力された単語の一致不一致のみしか見ない検索エンジンでは混乱招く可能性があります。例えば、「regulates(制御する)」は、様々な生物学的プロセスを指し得ます。
従来の情報検索(IR:Information Retrieval)システムは、入力文の拡張などの手法によりこの混乱を緩和しますが、セマンティック検索モデルは、これらの関係性を暗黙的に学習することを目的としています。
語順も重要です。ACE2(Angiotensin Converting Enzyme-2:アンジオテンシン変換酵素 2)自体も特定の生物学的プロセスを制御しますが、入力文は実際には「ACE2を制御するもの」を尋ねています。単語のみを照合しても、「ACE2を制御するもの」と「ACE2が制御するもの」は区別できません。
従来のIRシステムは、n-gram単語マッチングのようなトリックを使用しますが、セマンティック検索メソッドは、単語の順序とその順序が持つ意味をモデル化しようとします。
私達が使用するセマンティック検索テクノロジーは、最近Google検索の検索品質を向上させるために導入された人工知能BERTを利用しています。しかし、COVID-19 Research Explorerでは、生物医学文献の検索時に使用される検索語は、一般的なGoogle検索時に送信される検索語とは非常に異なる単語が使用されているという課題に直面しました。
BERTモデルを学習させるためには、教師となる学習用データが必要でした。具体的には、検索語とそれに関連する文書および強調表示箇所のセットです。
最終的な微調整作業のためにはBioASQによって生成された優れた学習用データに頼る事ができましたが、BioASQのような人間がまとめたデータセットは小さくなる傾向があります。
ニューラルセマンティック検索モデルには、大量の学習用データが必要です。人間が作成した小さなデータセットを補強するために、検索用データ生成技術の進歩を利用して、生物医学分野用の質問文と関連ドキュメントの大規模な学習用データを合成しました。
具体的には、大量の一般的な質問文と回答のペアを使用して、エンコーダー/デコーダーモデルをトレーニングしました。(下図の(a))
この種類のニューラルアーキテクチャは、1つのテキスト(例えば、英語の文章)をエンコードし、別のテキスト(たとえば、フランス語の文章)を生成する機械翻訳などのタスクなどで使用されています。今回は、回答文の数節からその節に関する質問を作り出すようにモデルをトレーニングしました。
次に、データセット内の全てのドキュメントからCORD-19関連の文章を取り出し、対応する質問文を生成しました。(b)
最後に、これらの合成質問文と節のペアを教師用データとして使用して、ニューラル検索モデルをトレーニングしました。(c)
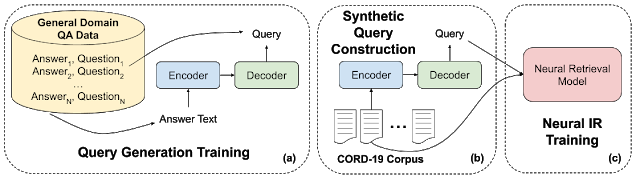
質問文の合成
ただし、ニューラルモデルによる検索がキーワードベースの検索よりもパフォーマンスが悪い例があることがわかりました。
これは、人工知能や心理言語学のほとんどの分野でよく知られているmemorization-generalization continuum問題によるものです。
キーワードベースのモデル、例えばtf-idfは、基本的に記憶ベースです。つまり、質問文から単語抜き出して記憶し、その単語を含む文を探します。
一方、ニューラル検索モデルは、概念と意味を一般化する事を学び、それらに基づいて照合しようとします。この手法は精度が重要な時に、一般化しすぎてしまう事があります。
例えば、「What regulates ACE2 expression?」と質問した場合、モデルに「regulates(制御)」の概念は一般化させたい(訳注:つまり、controlやsuperviserなどの似たような意味を持つ単語にもマッチさせたい)が、「ACE2」は頭字語を解釈する以外の一般化はさせたくない場合があります。
ハイブリッド単語ニューラル検索モデル
私達の検索システムを改善するために、ハイブリッド単語ニューラル検索モデル(Hybrid Term-Neural Retrieval Model)を開発しました。注目すべき部分は、キーワードベースの検索とニューラルベースの検索の両方をベクトル空間に割り当てていることです。
つまり、入力文と検索対象文書の両方をベクトルにエンコードし、検索を「入力ベクトルに最も類似したドキュメントベクトルを探す作業」として扱うことができます。
これは、k最近傍検索とも呼ばれます。これを大規模に機能させるために必要な多くの研究とエンジニアリングがありますが、これらの手法を組み合わせるとシンプルな検索メカニズムが実行可能になります。最も単純なアプローチは、ベクトルをトレードオフを制御するパラメータと組み合わせることです。
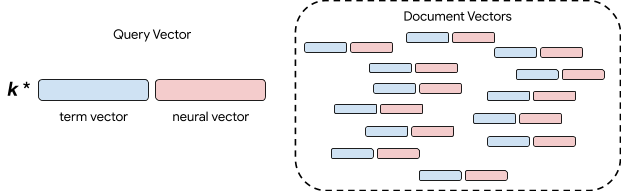
上の図では、青い箱が単語ベースのベクトルで、赤い箱がニューラルベクトルです。
これらのベクトルを連結して文章を表現します。
入力文の2つのベクトルも連結しますが、単語の完全一致とニューラルセマンティックマッチングの相対的な重要性はコントロールします。これは、重みパラメータkによって行われます。
より複雑なハイブリッドアプローチも可能ですが、この単純なハイブリッドモデルにより、生物医学文献検索の品質が大幅に向上することがわかりました。
使い方とコミュニティのフィードバック
COVID-19 Research Explorerは、オープンアルファとして研究コミュニティは無料で利用できます。今後、数か月にわたって、ユーザビリティの強化がいくつか行われる予定ですので、頻繁に確認してください。COVID-19リサーチエクスプローラーを試してみて、サイト内のフィードバックチャネルを介して私たちにあなたのコメントを共有してください。
謝辞
この取り組みは、以下を含む、しかし以下に限定されない、多くの人々の努力のおかげで上手くいきました。(姓のアルファベット順)
John Alex, Waleed Ammar, Greg Billock, Yale Cong, Ali Elkahky, Daniel Francisco, Stephen Greco, Stefan Hosein, Johanna Katz, Gyorgy Kiss, Margarita Kopniczky, Ivan Korotkov, Dominic Leung, Daphne Luong, Ji Ma, Ryan Mcdonald, Matt Pearson-Beck, Biao She, Jonathan Sheffi, Kester Tong, Ben Wedin
3.COVID-19 Research Explorer:新型コロナウィルス関連文献に特化した検索システム関連リンク
1)ai.googleblog.com
An NLU-Powered Tool to Explore COVID-19 Scientific Literature
2)covid19-research-explorer.appspot.com
COVID-19 Research Explorer
3)www.semanticscholar.org
CORD-19 COVID-19 Open Research Dataset


コメント