
1.SEED RLによる大規模強化学習(2/3)まとめ
・従来の強化学習アーキテクチャにはいくつかの欠点がありハードウェアの性能が生かせきれていない
・SEED RLアーキテクチャは欠点を解決するように設計されており規模を拡大して実行する事が可能
・2つの最先端のアルゴリズムV-traceとR2D2の統合によりSEED RLが実現可能になった
2.SEED RLとIMPALAの違い
以下、ai.googleblog.comより「Massively Scaling Reinforcement Learning with SEED RL」の意訳です。元記事の投稿は2020年3月23日、Lasse Espeholtさんによる投稿です。それにしてもIMPALAは少なくとも2019年6月発表のGoogle Research Footballの記事では、まだ「最先端の強化学習アルゴリズム(state-of-the-art reinforcement learning algorithms)」と表現されていましたが、一年も経ってない2020年3月の本記事では「初期世代の強化学習エージェント(earlier generation RL agent)」との事で、歴史の教科書送りとなりつつあるようです、進化早すぎ。アイキャッチ画像のクレジットはPhoto by Kyle Head on Unsplash
初期世代のRLエージェント(IMPALAなど)のアーキテクチャには、いくつかの欠点があります。
(1)ニューラルネットワークの推論にCPUを使用することは、アクセラレータを使用する場合よりもはるかに効率が悪く低速であり、モデルが大きくなり、計算コストが高くなると言う問題があります。
(2)アクター(actor:役者)とラーンナー(learner:学習者)の間でパラメータと中間モデルの状態を送信するために必要なネットワークの帯域幅がボトルネックになる可能性があります。
(3)1台のマシンで2つの完全に異なるタスク(つまり、環境のレンダリングと推論)を処理しても、マシンのリソースを最適に利用できるとは限りません。
SEED RLのアーキテクチャ
SEED RLアーキテクチャは、これらの欠点を解決するように設計されています。
このアプローチでは、ラーンナーがニューラルネットワークの推論を集中的に専用ハードウェア(GPUまたはTPU)で行うため、推論を加速し、モデルのパラメーターと状態をローカルに保つことでデータ転送時のボトルネックを回避できます。
観測は環境の全ステップでラーンナーに送信されますが、非同期ストリーミングRPCを備えたgRPCフレームワークに基づく非常に効率的なネットワークライブラリにより、レイテンシは低く抑えられます。これにより、1台のマシンで1秒あたり最大100万回のクエリを実行できます。
ラーンナーは数千のコア(例:Cloud TPUで最大2048)に規模を拡大でき、アクターの数も数千のマシンに規模を拡大してラーンナーを完全に活用できるため、毎秒数百万フレームでトレーニングすることができます。SEED RLはTensorFlow 2 APIに基づいており、私たちの実験では、TPUを使って高速化されました。
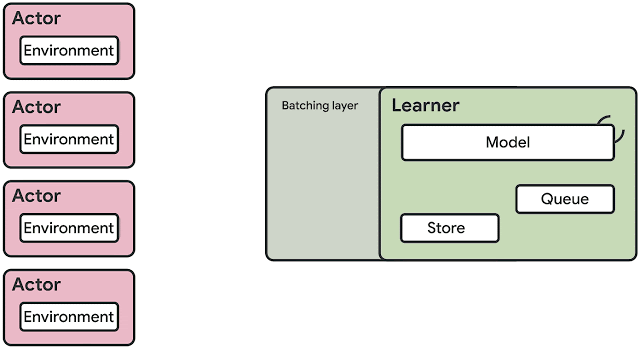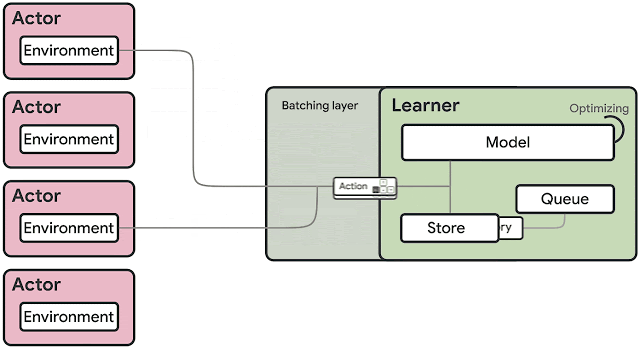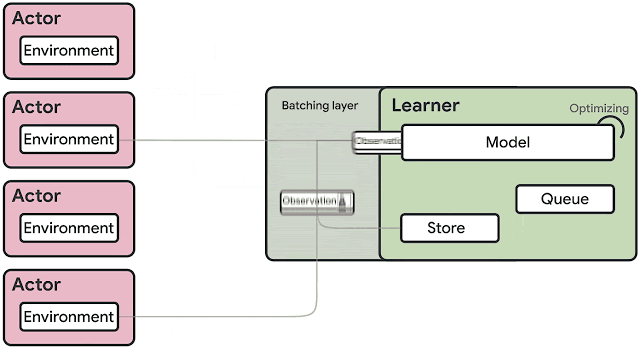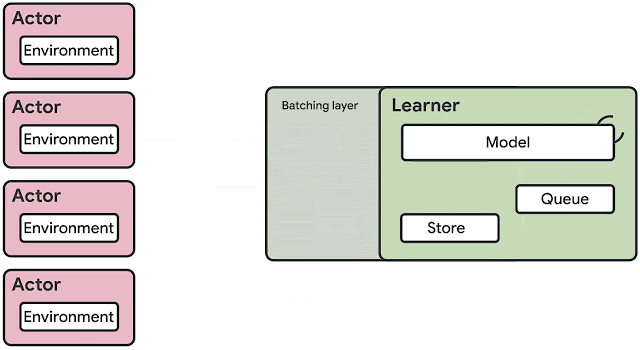
SEED RLのアーキテクチャの概要
IMPALAアーキテクチャーとは対照的に、アクターは環境内でのみアクションを実行します。 推論は、複数のアクターから送られるデータバッチを元に、学習者によってアクセラレータを使って集中的に実行されます。
このアーキテクチャを成功させるために、2つの最先端のアルゴリズムがSEED RLに統合されています。
1つ目は、IMPALAで最初に導入された、ポリシー勾配ベースの手法(policy gradient-based method)であるV-traceです。
一般に、ポリシー勾配ベースの手法は、アクションをサンプリングできるようなアクション分布を予測します。しかしながら、SEED RLではアクターとラーンナーは非同期に実行されるため、アクターのポリシーはラーンナーのポリシーよりわずかに遅れています。つまり、ポリシー外(off-policy)なのです。
一般的なポリシー勾配ベースの手法はアクターと学習者が同じポリシー内(on-policy)である事を想定しており、ポリシー外の設定では収束に問題が起こったり数値演算問題(訳注:numerical issues、パフォーマンスが非常に悪化したり、モデルが安定動作しなくなってしまう問題)が発生します。V-traceはポリシー外の手法であるため、非同期SEED RLアーキテクチャで適切に機能します。
2番目のアルゴリズムはR2D2です。これは、反復分散再生(recurrent distributed replay)を使用して、アクションの将来予測値に基づいてアクションを選択するQ-learning手法です。
このアプローチにより、Q-learningアルゴリズムを規模を拡大して実行しながら、リカレントニューラルネットワークを使用できます。つまり、リカレントニューラルネットワークを使ってエピソード内の過去の全てのフレームの情報に基づいて将来の値を予測できるのです。
3.SEED RLによる大規模強化学習(2/3)関連リンク
1)ai.googleblog.com
Massively Scaling Reinforcement Learning with SEED RL
2)arxiv.org
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
3)github.com
google-research/seed_rl
4)openreview.net
Recurrent Experience Replay in Distributed Reinforcement Learning
