
1.組成の一般化能力の測定(2/3)まとめ
・順守しなければならない文法規則を念頭におき「要素(atoms)」と「複合物(compounds)」を区別する
・理想的な組成性実験は要素の分布が類似して複合物の分布が異なっている事である
・「組成の一般化能力」実験するためにCompositional Freebase Questions(CFQ)データセットを作成
2.Compositional Freebase Questionsデータセット
以下、ai.googleblog.comより「Measuring Compositional Generalization」の意訳です。元記事の投稿は2020年3月6日、Marc van Zeeさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Raphaël Biscaldi on Unsplash
組成性の測定
システムの「組成の一般化能力」を測定するために、人間は事例を生成するための基本原則を理解しているという仮定から始めます。
例えば、質問に対する回答を生成する時、人間は、まずは順守しなければならない文法規則を念頭におきます。
次に、「要素(atoms)」と「複合物(compounds)」を区別します。「要素」は事例を組成するために使用される土台であり、「複合物」はこれらの「要素」を具体的な組成にしたものです。
例えば、以下の図では、全てのボックスが「要素」です。
(例:「Shane Steel」「brother」「<entity>’s <entity>」「produce」など)
これらが一緒になって以下のような「複合物」を形成します。
(例:「produce and <verb>」「Shane Steel’s brother」「Did Shane Steel’s brother produce and direct Revenge of the Spy?」など)
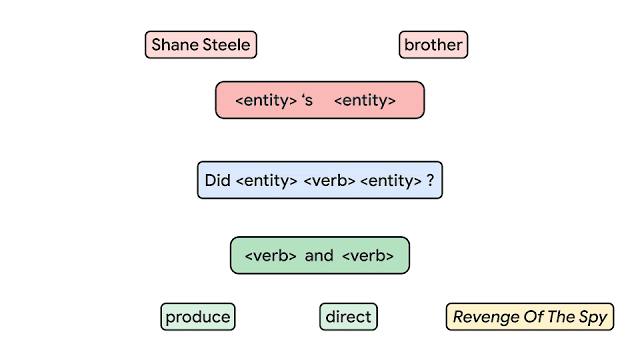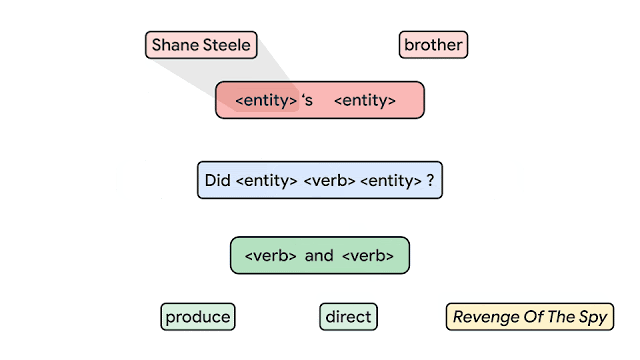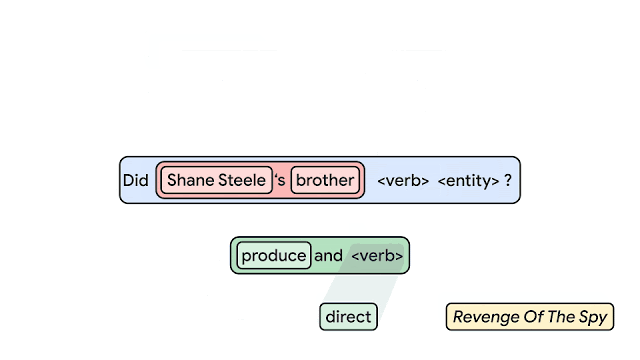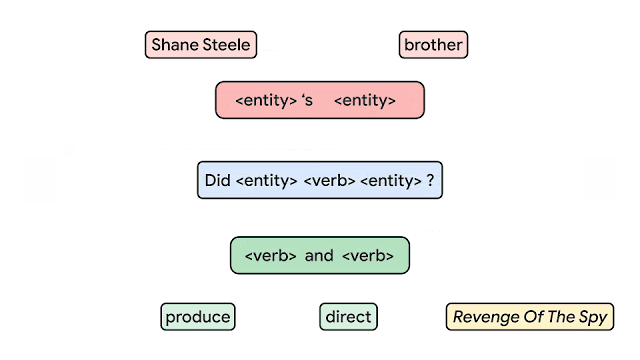
基礎(要素)から文(複合物)を構築します。
理想的な組成実験では、要素の分布が類似している必要があります。
つまり、トレーニングセット内の単語とサブフレーズの分布は、テストセット内のそれらの分布にできるだけ似ていますが、複合物の分布は異なっている事です。
例えば、映画に関する質問回答タスクの「組成の一般化」を測定するには、トレーニングセットとテストセットで次のような質問をします。
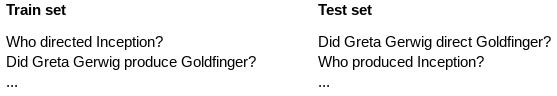
「directed」「Inception」「who <predicate> <entity>」などの要素は、トレーニングセットとテストセットの両方で表示されていますが、複合物は異なります。
Compositional Freebase Questionsデータセット
正確な「組成の一般化能力」実験を実施するために、公開されたFreebase知識ベースから生成された自然言語の質問と回答のシンプルでありながら現実的な大規模なデータセットである、Compositional Freebase Questions(CFQ)データセットを作成しました。
CFQは、テキスト入力/テキスト出力タスク、および意味解析に使用できます。実験では、意味解析に焦点を当てています。これは入力が自然言語の質問であり、出力がクエリ(問い合わせ文)であり、このクエリをFreebaseに対して実行すると正しい結果が生成されるタスクです。
CFQには約240kの例と約35kのクエリパターンが含まれており、比較可能な従来のデータセットよりも大幅に大きく複雑です。WikiSQLの約4倍で、Complex Web Questionsよりも約17倍のクエリパターンがあります。
質問と回答が自然なものになるように、特別な注意が払われています。また、各例の構文の複雑さを、「complexity level(L)」を基準として定量化します。この基準は、解析ツリーの深さにほぼ対応します。例を以下に示します。

3.組成の一般化能力の測定(2/3)関連リンク
1)ai.googleblog.com
Measuring Compositional Generalization
2)openreview.net
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
3)github.com
google-research/cfq/
4)arxiv.org
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks

コメント