
1.Open Images V6:新しいタイプの注釈localized narrativesが特徴(1/2)まとめ
・多くの点で世界最大の画像データセットであるOpen Imagesのバージョン6が公開
・バージョン6では新しいタイプの注釈「localized narratives(物語化した注釈)」が追加された
・これはマルチモーダルな注釈、つまり音声や文章、マウスの動きを使って表現した全く新しい注釈
2.localized narrativesとは?
以下、ai.googleblog.comより「Open Images V6 — Now Featuring Localized Narratives」の意訳です。元記事の投稿は2020年2月26日、Jordi Pont-Tusetさんによる投稿です。
Narratives(ナラティブ)とは直訳すると物語文学、と言う事で物語っぽい事を重視して選んだけれども単なるコスプレ写真と言われればその通りな気もするアイキャッチ画像のクレジットはPhoto by Anthony Tran on Unsplash
Open Imagesは、視覚を扱うニューラルネットワークの学習で使用出来る、多くの点で世界最大の画像データセットです。Open Imagesは最新の畳み込みニューラルネットワークの学習で使用するための注釈(annotation)、つまり様々なタイプのラベルが含まれています。昨年5月のOpen Imagesバージョン5のリリースにより、Open Imagesデータセットには、36Mの画像レベルのラベル、15.8Mの境界ボックス、2.8Mのインスタンスセグメンテーションラベル、および391kの視覚的関係が注釈された9Mの画像が含まれるようになりました。データセット自体に加えて、関連するOpen Images Challengesは、物体検出、インスタンスセグメンテーション、および視覚的関係検出などの最新技術の進歩に拍車をかけています。

Open Images V5の様々なラベル
画像レベルのラベル、境界ボックス、インスタンスのセグメント化、視覚的な関係
画像ソース:D. Millerによる1969 Camaro RS / SS、
anita kluskaによる家、
Ari HelminenによるCat Cafe Shinjuku calico、
及びAndrea SartoratiによるRadiofiera – Villa Cordellina Lombardi, Montecchio Maggiore (VI) – agosto 2010
全ての画像はCC BY 2.0ライセンス
本日、Open Images V6のリリースをお知らせいたします。OpenImages V6は、Open Imagesデータセットの注釈を大幅に拡張し、多数の新しい視覚的関係(例:フライングディスクをキャッチする犬)、人間の行動(例:ジャンプする女性)、画像レベルのラベル(例:paisley、イギリス発祥と言われる模様のデザインの一種、勾玉模様)を追加しています。
特筆すべき事は、このリリースでは新しいタイプの注釈、「localized narratives(ローカライズ ナラティブ、物語化した注釈)」が追加されます。
訳注:localized narrativesとは下の動画を見ると一目瞭然ですが、画像を文章と音声で説明し、更にそれらが説明している画像の範囲をマウスカーソルの動きで伝える事です。かなり悩んだのですが、今までになかった新しい概念なので無理に「物語化した注釈」等の日本語訳すると逆に読んでいて混乱するので以下、localized narrativesで統一します。
これは物体をマルチモーダルな注釈、つまり音声や文章、マウスの動きなど様々な手段を使って表現したまったく新しい形式の注釈です。
Open Images V6では、これらの画像についての物語は50万画像で利用できます。更に、以前の作品との比較を容易にするために、COCOデータセットの完全な12.3万画像用に画像についての物語を注釈としてリリースします。
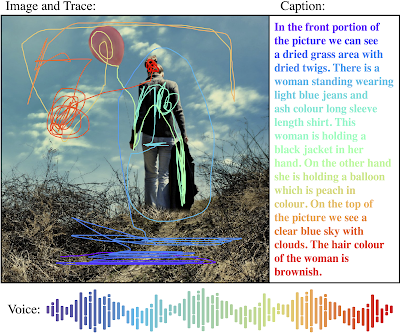
localized narrativesのサンプル
Image source: Spring is here:-) by Kasia.
localized narratives
localized narrativesの背後にある動機の1つは、視覚と言語の関係を研究し、活用することです。これは通常、画像とその画像に付与されるキャプション、つまり人間が作成した画像の内容を説明する文章によって行われます。
ただし、画像キャプションの制限の1つは、視覚的な下地の欠如、つまり、テキストで記述する単語が画像上でどの位置にあるか局所的な情報を持っていない事です。それを軽減するために、以前のいくつかの作品では、画像内に存在する分類対象の名詞について境界ボックスを描画して表現しています。対照的に、画像内の物語では、テキストによる説明文は全て画像内に存在している根拠に基づいた単語です。

画像とキャプションの間の異なるレベルの関連付け
左から右:画像全体を説明するキャプション(COCO)
境界ボックスで説明する名詞(Flickr30kエンティティ)
マウスの動きで各単語が示す部分を表現する(画像内の物語)
画像ソース:COCO、Flickr30kエンティティ、Sapa, Vietnam by Rama.
Localized narrativesは注釈作業者によって生成されます。注釈作業者は音声による画像の説明を提供し、同時にマウスを動かして現在説明されている領域にカーソルを合わせます。音声による注釈は、説明文を画像の領域と直接結び付ける事が出来るため、このアプローチの中核です。 説明文を取り扱いしやすくするために、注釈作業者は手動で説明文を書き起こし、その後、自動音声再生システムで再生させて同期を取りました。これにより、説明文の3つのモダリティ(音声、文章、およびマウスの動き)が正しく同期化されます。
![]()
手動および自動の文字起こしの調整
アイコンはウェブサイトFreepikのオリジナルデザインに基づきます。
3.Open Images V6:新しいタイプの注釈localized narrativesが特徴(1/2)関連リンク
1)ai.googleblog.com
Open Images V6 — Now Featuring Localized Narratives
2)storage.googleapis.com
Open Images Dataset V6 + Extensions


コメント