
1.Reformer:効率的なTransformer(1/2)まとめ
・TransformerはLSTMより大きなコンテキストウィンドウを持つため文脈を理解する能力が高い
・しかしTransformerを更に拡張しようとするとAttentionとメモリ割り当ての問題に直面する
・ReformerはLocality-Sensitive-Hashingとreversible residual layersを使ってTransformerを改良したモデル
2.Locality-Sensitive-Hashingとは?
以下、ai.googleblog.comより「Reformer: The Efficient Transformer」の意訳です。元記事の投稿は2020年1月16日、Nikita KitaevさんとŁukasz Kaiserさんによる投稿です。Reformerは直訳すると改革家の意味ですが、gun reformで銃規制になるんですね、と言う事から連想したアイキャッチ画像のクレジットはPhoto by AndriyKo Podilnyk on Unsplash
言語、音楽、ビデオなどのシーケンシャルなデータ、つまり連続していくデータを理解することは人工知能にとって困難な作業です。前後の文脈に広く依存するデータを理解する事は非常に困難で、例えば、ビデオ画面から人物または物体が消えて、その後、同じ人物または物体が再表示された時、多くのモデルはどのようにそれが見えていたかを忘れてしまいます。
言語領域では、LSTM(long short-term memory)ニューラルネットワークが文単位で翻訳するのに十分なコンテキスト(文脈)をカバーできます。この場合、コンテキストウィンドウ(文脈を考慮する事が可能な文章範囲)は、数十から約100単語に及びます。
より最近のTransformerモデルは、文を文に翻訳する際のパフォーマンスを向上させただけでなく、複数の文書の要約を参照してウィキペディアの記事を生成する事も可能です。
これが可能な理由は、Transformerで使用されるコンテキストウィンドウが数千語に及ぶためです。このような大きなコンテキストウィンドウを持っているため、Transformerは画素や音符など、文書以外のアプリケーションにも使用できるので、音楽や画像の生成にも使用できます。
ただし、Transformerをさらに大きなコンテキストウィンドウに拡張しようとすると、制限に直面します。
Transformerの威力は、Attentionから生じています。Attentionは、コンテキストウィンドウ内で考えられる全ての単語のペアを考慮し、それらの単語間のつながりを理解する処理です。
従って、もし文書が10万単語から構成されている場合、10万 x 10万の単語ペア、または各ステップで100億ペアを評価する事が必要になりますが、これは現実的ではありません。
別の問題は、各レイヤーの出力を保存する方法にあります。大きなコンテキストウィンドウを使用するアプリケーションの場合、複数のレイヤーの出力を保存するために必要なメモリは、非常に大きくなります。(数レイヤーであればギガバイト級、数千レイヤーであればテラバイト級)。つまり、現実的なTransformerモデルは多数のレイヤーを使用する事ができず、数段落の文書や短い音楽の生成に留まっています。
本日、私達はReformerを紹介します。Reformerは、最大100万語のコンテキストウィンドウをすべて単一のアクセラレータで処理し、16 GBのメモリのみで利用出来るように設計されたTransformerモデルです。
Transformerの制限に繋がっているAttentionとメモリ割り当ての問題を解決するために、2つの重要な技術を組み合わせています。
Reformerは「局所性に敏感なハッシュ(LSH:Locality-Sensitive-Hashing)」を使用して、長いシーケンシャルデータを取り扱う際の複雑さを軽減します。そして、「可逆的な残余レイヤー(reversible residual layers)により、メモリをより効率的に使用しています。
Attentionの問題
Transformerモデルを非常に大きな文章に適用する際に最初に直面する課題は、Attentionレイヤーの処理方法です。
LSHは、全ベクトルの全ペアを検索する代わりに、類似したベクトルを一緒に扱うハッシュ関数を使う事でこれを実現します。例えば、翻訳タスクではネットワークの最初のレイヤーの各ベクトルは単語を表現します。異なる言語であっても同じ単語に対応するベクトルが同じハッシュを取得する場合があります。
次の図では、異なる色は異なるハッシュを表し、類似した単語は同じ色になっています。ハッシュが割り当てられると、並び順は再配置されて同じハッシュを持つ要素がまとめられ、部分的に(または一塊に)分割されて並列処理が可能になります。次に、これらの非常に短い塊(および隣接する隣接ノード)内でAttention処理が行われるため、計算負荷が大幅に削減されます。
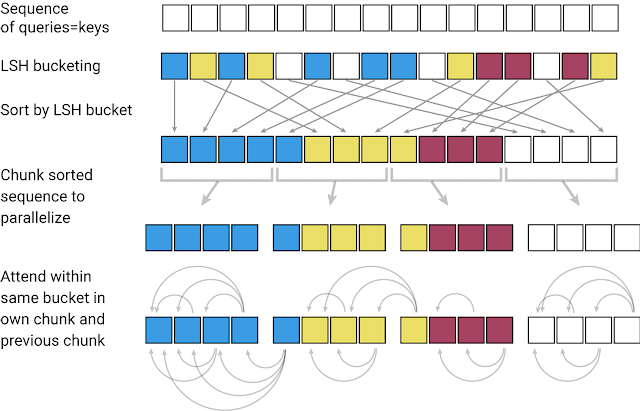
LSH:
Reformerは連続したキーをの入力として受け取ります。各キーは、最初のレイヤーでは個々の単語(または画像の場合は画素)、後半のレイヤーではより大きな文脈を表すベクトルです。
LSHがキーの並びに適用され、その後、キーはハッシュを使って整列され、一つの塊にまとめられます。Attentionは、単一の塊とそのすぐ隣の塊にのみ適用されます。
3.Reformer:効率的なTransformer(1/2)関連リンク
1)ai.googleblog.com
Reformer: The Efficient Transformer
2)github.com
trax/trax/models/reformer/

