
1.ALBERT:軽量化と冗長性排除をしたBERT(2/2)まとめ
・パラメータの因数分解と冗長性の排除を行う事でわずかなBERTよりパラメータを89%削減
・パラメータサイズを削減した事により計算機資源に余裕が生まれ、モデルの規模を改めて拡大できた
・ALBERT-xxlargeは全体で30%のパラメーター削減を達成しつつ読解力テストで最先端のスコアを更新
2.正確な言語理解に必要な事とは?
以下、ai.googleblog.comより「ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations」の意訳です。元記事の投稿は2019年12月20日、Radu SoricutさんとZhenzhong Lanさんによる投稿です。
2つの設計変更、すなわちパラメータの因数分解と冗長性の排除を同時に実装すると、パラメータ数がわずか12MのALBERTベースモデルが生成されます。これはBERTベースモデルと比較してパラメータ数を89%削減していますが、計測した全てのベンチマークで相当なパフォーマンスが実現します。
性能は少し低下してしまいますが、このパラメーターサイズの削減により、モデルの規模を再び拡大する機会が得られます。
使用可能なメモリが十分あると仮定すると、隠れ層のembeddingサイズを10から20倍に拡大できる見込みです。隠れ層のサイズが4096のALBERT-xxlarge構成は、BERT-largeモデルと比較して全体で30%のパラメーター削減を達成しつつ、更にパフォーマンスの大幅な向上を実現します。SQuAD2.0で+4.2(83.9から83.9に向上)、およびRACEで+8.5(73.8から82.3に向上)です。
これらの結果は、正確な言語理解は、堅牢で高い容量を持つ文脈特徴表現の開発に依存している事を示しています。
隠れ層のembeddingでモデル化された文脈情報は、単語の意味を捕捉し、文章の全体的な理解を促進します。そして、この性能の向上は、標準ベンチマークでモデルのパフォーマンスを調べる事で直接測定する事ができます。
RACEデータセットを使用したモデルパフォーマンスの最適化
SAT Reading Testのような読解力テストを実施してモデルの言語理解能力を評価する事が出来ます。(訳注:SAT Reading Testはアメリカの大学で導入されている共通試験です。アメリカへの留学試験時などには外国人も受ける事になるのですが、ネイティブ向けの試験なので非ネイティブにとってはTOEFLなどよりもかなり難しい単語が出て来る試験と言われています)
これは、この目的のために公開されている最大のリソースであるRACEデータセット(2017)を使用して実現できます。この読解力テストにおけるコンピューターのパフォーマンスは、過去数年間の言語モデリングの進歩をよく反映しています。
文脈に依存しない単語表現のみを事前学習するモデルは、このようなテストではスコアが低くなります。(45.9、左端の棒グラフ)、文脈に依存する言語知識を学習するBERTは、72.0と比較的良いスコアを獲得しています。
XLNetやRoBERTaなどのBERTを洗練したモデルは、スコアを82から83の範囲に更に伸ばします。前述のALBERT-xxlarge構成では、BERTが使ったのと同じデータセット(Wikipediaおよび本)でトレーニングすると、同程度の(82.3)のRACEスコアとなります。ただし、XLNetやRoBERTaが学習時に使った更に大きなデータセットでトレーニングすると、これまでの他の全てのアプローチを大幅に上回る、新しい最先端のスコア、89.4を達成します。
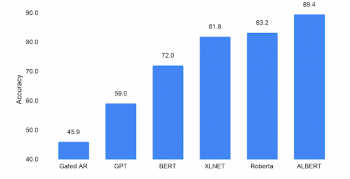
RACEチャレンジでの人工知能のパフォーマンス(SATのような読解力テスト)。全ての設問をランダムに回答した場合に期待できるスコアは25.0です。達成可能な最大スコアは95.0です。
ALBERTの成功は、モデルの何処が文脈の特徴表現を強力に増強するのかを識別する事の重要性を示しています。モデルアーキテクチャを改善する努力を上記ポイントに集中することにより、広範なNLPタスクでモデルの効率とパフォーマンスの両方を大幅に改善することができます。NLPの分野での更なる進歩を促進するために、私たちはALBERTを研究コミュニティにオープンソースとして公開しています。
3.ALBERT:軽量化と冗長性排除をしたBERT(2/2)関連リンク
1)ai.googleblog.com
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
2)arxiv.org
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
3)github.com
google-research/ALBERT
