
1.VTAB:視覚タスク用のベンチマーク(2/2)まとめ
・VTABによる評価では最高パフォーマンスを示した特徴表現学習アルゴリズムはS4L
・S4L(Self-Supervised Semi-Supervised Learning)は特に「構造」タスクのパフォーマンスを改善
・「自然」タスク以外では優位性が小さいため普遍的な視覚特徴表現のためには更なる研究が必要
2.VTABによる評価
以下、ai.googleblog.comより「The Visual Task Adaptation Benchmark」の意訳です。元記事は2019年11月6日、Neil HoulsbyさんとXiaohua Zhaiさんによる投稿です。
VTABによる評価の結果
多くの一般的な視覚特徴表現学習アルゴリズムをVTABを用いてテストする大規模な研究を実施しました。この研究の対象には、生成モデル(GANおよびVAE)、自己教師モデル、半教師モデル、教師付きモデルが含まれていました。
全てのアルゴリズムは、ImageNetデータセットで事前にトレーニングされています。また、事前にトレーニングされた特徴表現を使用しない、つまり「最初から(from-scratch)」トレーニングした場合のパフォーマンスもそれぞれ比較しました。以下の図は、結果の主なパターンをまとめたものです。
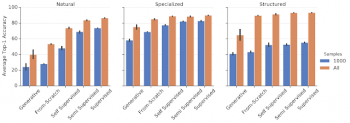
様々なタスクグループ(自然、専門、構造)にわたるさまざまなクラスの特徴表現学習アルゴリズムのパフォーマンス。 各バーは、グループ内の全てのタスクにわたる平均パフォーマンスを示します。
全体として、生成モデルは他の手法と同レベルには機能せず、最初からトレーニングした結果よりも更に悪いことがわかります。しかし、自己教師モデルのパフォーマンスははるかに優れており、最初からトレーニングした結果よりも大幅に優れています。更に優れているのは、ImageNetラベルを使用した教師あり学習です。興味深いことに、教師あり学習は「自然」のタスクグループでは非常に優れています。しかし、自己教師学習は、ImageNetに含まれている画像に似ていない画像を多く含んでいる「専門」や「構造」のタスクグループで教師あり学習に迫るスコアを出しています。
私たちがテストした中で、最高のパフォーマンスの特徴表現学習アルゴリズムはS4L(Self-Supervised Semi-Supervised Learning)です。これは、教師あり学習と自己教師付き学習の両方の事前トレーニング損失を組み合わせたものです。下の図は、S4Lと標準の教師あり学習のImageNet事前トレーニングを比較しています。S4Lは、特に「構造」タスクのパフォーマンスを改善するようです。ただし、特徴表現学習は「自然」タスク以外では最初からトレーニングしたグループに対する優位性が小さいため、普遍的な視覚特徴表現を達成するためにより多くの進歩が必要であることを示しています。
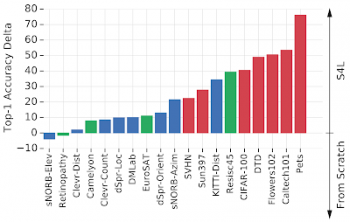
S4Lと「最初からトレーニング(スクラッチ)」した結果のパフォーマンス比較。各バーはタスクに対応しています。 正の値のバーは、S4Lが優れているタスクを示します。負のバーは、スクラッチのパフォーマンスが優れていることを示します。
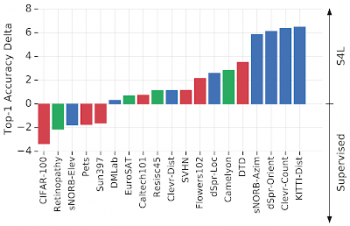
ImageNetを使ったS4Lと教師有り学習のパフォーマンス比較
正の値のバーは、S4Lのパフォーマンスが高いことを示します。バーの色は、タスクグループを示します。赤=自然、緑=専門、青=構造。ImageNetラベルを使用するだけでなく、追加の自己教師が構造タスクに役立つ傾向があることがわかります。
まとめ
VTABを実行するコードは、19の評価データセットと正確なデータ分割を含み、GitHubで利用可能です。ベンチマーク用の公開セットを使用すると、結果の再現性が保証されます。進行状況はパブリックリーダーボードで追跡され、モデルの評価はTF Hubにアップロードされ、公共に参照および複製可能になります。全タスクに評価を実行するためのシェルスクリプトが提供されており、VTABを業界全体の標準化された評価手法として簡単に使用する事ができます。VTABはTPUとGPUの両方で実行できるため、非常に効率的です。単一のNVIDIA Tesla P100アクセラレータで数時間で同じ結果を得ることができます。
Visual Task Adaptation Benchmarkは、どの視覚的特徴表現が広範囲な視覚タスクに一般化されるかをよりよく理解し、将来の研究の方向性を提供するのに役立ちました。これらのリソースが、一般的かつ実用的な視覚的特徴表現の進歩を促進するのに役立ち、その結果、利用可能なラベル付けされたデータが限られていると言う問題を抱える様々な視覚関連タスクにも、ディープラーニングを適用できるようになる事を願っています。
謝辞
本研究の背後に存在するコアチームはJoan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, Lucas Beyer, Olivier Bachem, Michael Tschannen, Marcin Michalski, Olivier Bousquet, そして Sylvain Gellyです。
3.VTAB:視覚タスク用のベンチマーク(2/2)関連リンク
1)ai.googleblog.com
The Visual Task Adaptation Benchmark
2)arxiv.org
The Visual Task Adaptation Benchmark
S4L: Self-Supervised Semi-Supervised Learning
3)github.com
google-research/task_adaptation
