
1.Form2Fit:物体の分解と組立てを行う事でロボットが組合わせの概念を学習(2/3)まとめ
・Form2Fitは吸着、配置、マッチングの3つのネットワークにより構成される
・完成品を解体する事は組立より簡単であると言う洞察を元に分解データを時間的に反転して利用している
・時間反転分解(time-reversed disassembly)と呼ばれるこの概念により自己教師型学習を実現している
2.Form2Fitの構成
以下、ai.googleblog.comより「Learning to Assemble and to Generalize from Self-Supervised Disassembly」の意訳です。元記事の投稿は2019年10月31日、Kevin ZakkaさんとAndy Zengさんによる投稿です。
組立のための形状記述子
Form2Fitのコアコンポーネントは、2ストリームマッチングネットワークです。
視覚データから物体の「形状と向き」、「配置位置」を意識した画素単位の記述子を推測することを学習します。これらの記述子は、物体の向き、外面、及び状況をタスク毎に知識としてエンコードする圧縮された三次元の特徴表現として理解する事ができます。
Form2Fitはこれらの記述子を使用して、物体とその配置場所との対応を確立します。これらの記述子は向きを意識しているため、Form2Fitは、選択された物体を配置する前にどのように回転させるかを推測できます。
Form2Fitは、2つの追加ネットワークを使用して、何処を掴んで、何処に配置すべきかの候補を生成します。
吸着ネットワーク(suction network)は物体の3D画像を受け取り、吸着成功確率を画素単位で予測します。吸着確率マップはヒートマップとして視覚化されます。ここでは、暖色ピクセルは、対応する画素の位置が物体を把握するのに適した位置である事を示します。
並行して、配置ネットワーク(place network)に部品配置場所の3D画像が送られ、配置の成功確率を画素単位で予測されます。これらもヒートマップとして視覚化されており、高い信頼値の箇所は、ロボットアームが上空から接近して物体を配置するためのより良い場所として推測された場所です。
最後に、プランナーは3つのモジュールすべての出力を統合して、最終的に掴む位置、配置する位置、および回転角度を生成します。
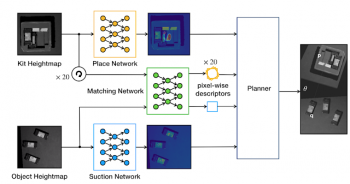
Form2Fitの概要
吸着および配置ネットワークは、それぞれの候補の選択および配置の場所を推測します。 マッチングネットワークは、画素単位の方向を意識する記述子を生成して、掴んだ場所を対応する配置場所に一致させます。次に、プランナーは全てを統合してロボットを制御し、最適な箇所を掴んで最適な配置場所に物体を移動するアクションを実行します。
分解から組立を学ぶ
ニューラルネットワークには大量の学習用データが必要です。組立作業などのタスクに関する大量の学習用データを収集する事は困難な場合があります。
ロボットにランダムに作業を行わせて組立が成功する可能性はわずかであるため、物体を正しい向きで狭いスペースに正確に配置するような組立作業を試行錯誤を通して学習させるのは困難です。
対照的に、完成品を解体する事は、組立時のようにパーツを正しい場所に挿入する必要がなく、単にパーツを取り除く方が簡単なため、試行錯誤を通して学ぶのが簡単な場合がよくあります。
Form2Fitのトレーニングデータを蓄積するために、この違いを活用しました。

時間反転による自己教師学習の例
消臭剤キットの分解手順を時間的に巻き戻すと、有効な組立手順が生成されます。
私達の重要な観察は、多くの組立て手順は、分解手順を時間的に逆再生すると有効な組立て手順になると言う事です。
時間反転分解(time-reversed disassembly)と呼ばれるこの概念により、Form2Fitは試行錯誤でランダムに選択して完全に組み立てられた物体を分解し、その分解手順を逆にして組立て方法を学習する事により、自己教師学習によって完全にトレーニングできます。
3.Form2Fit:物体の分解と組立てを行う事でロボットが組合わせの概念を学習(2/3)関連リンク
1)ai.googleblog.com
Learning to Assemble and to Generalize from Self-Supervised Disassembly
2)form2fit.github.io
Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly

コメント