
1.長文を読みあげる合成音声の品質を評価する(2/2)まとめ
・複数の文が含まれる長文を評価する事は人間の音声を評価対象にしても評価がぶれる
・長文を読みあげる合成音声の評価は簡単ではなく、人間の行動真理などが関係している可能性がある
・段落全体を評価するのが最も保守的なアプローチかもしれない
2.合成音声の品質の評価
以下、ai.googleblog.comより「Assessing the Quality of Long-Form Synthesized Speech」の意訳です。元記事は2019年9月9日、Tom Kenterさんによる投稿です。
合成音声を評価すると、違いがより顕著になります。
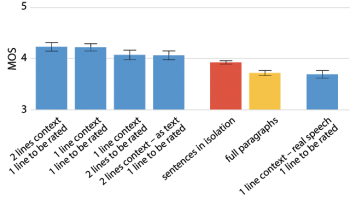
前項で使用したのと同じニュース記事データセットで機械が発声した合成音声に対するMOSの評価結果。特に指定がない限り、すべての行は合成音声です。
文脈の提供方法が評価の違いをもたらしているのかどうかを確認するために、いくつかの異なる方法を試しました。
評価される文に至るまでに1つまたは2つの文を合成音声または自然音声として提供します。
「評価対象の文以外の文」が音声合成で追加されると、スコアは上昇します。(左側の4つの青いバー)ところが、自然音声で追加された場合は、スコアは低下します。(右端の青いバー)
私達の仮説は、これはアンカー効果に関係しているということです。追加音声が非常に自然な場合(人間が実際に発声した音声な場合)、合成されたスピーチは不自然であると認識されてしまうと言う事です。
段落スコアの予測
合成された音声の段落全体(黄色のバー)が再生されると、これは他の設定よりもさらに不自然であると認識されます。最初の仮説は、最も悪い評価に引きずられる(weakest-link)という説でした。
つまり、「段落の評価」はおそらく「段落の中で最も評価が悪い文と同じくらい悪い評価」になるという仮説です。もし、それが正しいならば、段落の評価を予測する事は非常に簡単です。段落中の個々の文の評価の最低値を見つければ、段落の評価を簡単に予測できるはずです。しかし、このアプローチは機能しませんでした。
weakest-link仮説の失敗は、このような単純なアプローチでは解き明かすことが困難な、より微妙な要因による可能性があります。これをテストするために、機械学習アルゴリズムもトレーニングして、個々の文から段落スコアを予測しました。ただし、このアプローチでも、段落スコアを確実に予測することはできませんでした。
まとめ
複数の文が含まれる場合、合成音声の評価は簡単ではありません。文章を単独で評価する従来のパラダイムでは、全体像を把握することはできません。文脈が提供される場合、アンカー効果に注意してください。段落全体を評価するのが最も保守的なアプローチかもしれません。 この発見が、オーディオブックリーダーや会話エージェントなど、長文形式のコンテンツが関係する音声合成の将来の研究を促進することを願っています。
謝辞
論文のすべての著者に感謝します。Rob Clark, Hanna Silen, Ralph Leith。
3.長文を読みあげる合成音声の品質を評価する(2/2)関連リンク
1)ai.googleblog.com
Assessing the Quality of Long-Form Synthesized Speech
2)arxiv.org
Evaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs
