
1.Project Euphoniaの非標準音声用にパーソナライズした音声認識(2/2)まとめ
・部調整モデルはASLスピーチに関しては、ベースラインモデルに比べてかなり改善する事が検証された
・2つのレイヤーの微調整だけで全体を微調整した場合と比較して相対的に86%を達成している
・20分程度のパーソナライズ音声データで訓練する事により相対的エラー率を60%削減できている
2.ALSスピーチと標準的スピーチの認識ミスの分布
以下、ai.googleblog.comより「Project Euphonia’s Personalized Speech Recognition for Non-Standard Speech」の意訳です。元記事は2019年8月13日、Joel ShorさんとDotan Emanuelさんによる投稿です。
結果
制限されたテストセットを用いたケースでの絶対ワードエラー率を以下に示します。非常に非標準的なスピーチ、つまりALS機能評価スケール(ALS Functional Rating Scale)で3未満、つまり非常に聞き取りにくいアクセントとASLスピーチに関しては、ベースラインモデルに比べてかなり改善があり、通常のスピーチに近い軽度のALS発声で中程度の改善が見られます。
基本モデルと微調整モデルの相対的な違いは、改善の大部分が微調整プロセスによるものであることを示しています。ただし、Arctic datasetにおけるRNN-Tの場合は例外です。RNN-Tベースラインは既に十分強力です。
| RNN-基本モデル | RNN-T微調整モデル | LAS基本モデル | LAS微調整モデル | |
| Arctic ※1 |
13.3 | 8.5 | 22.6 | 11.3 |
| ALS ※2 |
59.7 | 20.9 | 86.3 | 31.3 |
| ALS ※3 |
33.1 | 10.8 | 49.6 | 17.2 |
※1 L2-Arcticデータセットを使った非ネイティブスピーカーの英語スピーチのWER
※2 低FRS(ALS Functional Rating Scale)のスピーチ。FRS 2は何度か繰り返し発音すれば理解できる。FRS 1は非音声コミュニケーションと組み合わされた音声
※3 高FRSのスピーチ。FRS 3は発声に困難がある人だと他の人が気づくレベル
RNN-Tモデルは、2つのレイヤーだけを微調整することで改善の91%を達成しました。そのほとんどは入力層に近いものです。 アクセント付きデータセットでは、同じ2つのレイヤーを微調整すると、ネットワーク全体を微調整した場合に比べて相対的な改善の86%を達成しました。 これは以前の研究「Adapting acoustic and lexical models to dysarthric speech」の結果と一致しています。
パフォーマンスの向上のほとんどは、トレーニングの初期に達成されました。トレーニングしたモデルは、語彙と言語の複雑さが比較的限られた領域でテストされたため、パフォーマンスの数値は、モデルがより一般的なタスクでどの程度うまく機能するかと必ずしも関係しません。
私達はネットワークの一部を必要最小限微調整するだけで、一般的な音声モデルからの音響情報および言語情報を保持したまま、個別の新しい話者に適応できるようになることを願っています。今後の研究では、この仮説を検証します。
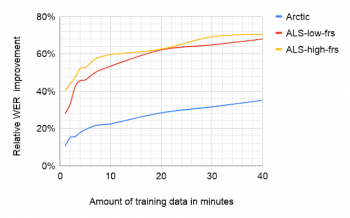
ALS-low-frsは、明瞭度の低いALSスピーカー(FRS 2や1)を表し、ALS-high-frsは、音声への影響がそれほど大きくないALSスピーカー(FRS 3)に相当します。
モデルの動作を理解する
微調整後にモデルがどのように改善されたかをよりよく理解するために、音素をミスしたパターンに注目しました。 最初に、標準的な音声で訓練した基本ASRモデルが出力した音素誤りの分布を、ALS音声で訓練がされた際の誤りと比較することから始めました。
ALSデータと標準スピーチデータの5つの最大の違いはSAMPA音素(ASCII 文字のみで表現された音声記号)で、p、U、f、k、およびZであり、削除ミスの20%を占めています。同様に、nとmの音素が共に、挿入/置換のミスの17%を占めています。微調整されたモデルで同じ分析をした結果、認識されていない音素の分布が標準的な音声の分布により類似していることが検証されました。
分析の結果、すべての間違いには2つの側面がある事がわかりました。。システムが理解できない音素と、システムが発声されたと考えた(誤って聞き取った)音素です。
同じ精度の2つのシステムがあるとします。1つのシステムは常にf音素をg音素であると誤認し、別のシステムはf音素が何であるかを知らず、ランダムに推測します。これらの2つのシステムのパフォーマンスは同じ結果になり、音素ミスの分布は同じです。しかし、ミスが発生した場合に誤って予測された音素の分布は大きく異なります。
驚くべきことに、「Euphoniaによる微調整済みARSモデル」の音素毎のミスの傾向は、「通常音声に対するミスの分布」と「ALS音声に対するミスの分布」で非常によく似ています。
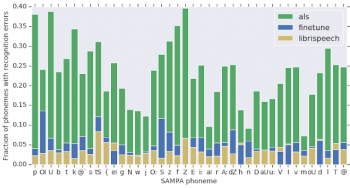
緑色:微調整前モデルでALSスピーチを音声認識、青色:微調整後モデルでALSスピーチを音声認識、および微調整後モデルで一般的なスピーチ(Librispeechデータセット)を音声認識した結果のSAMPA音素ごとの削除/置換ミスの比較
今後の研究
将来的には、利用可能な学習データが少ない状況で有用な追加のテクニックを検討する予定です。また、音素の間違いを使用して、トレーニング中に特定の例を重み付けしたり、ALSを患う人々が持つ最も一般的な音素の間違いを含むトレーニング文を選んで学習用データとして記録したいと考えています。また、同様の条件を持つ複数のスピーカーからのデータの蓄積を検討したいと思います。
この分野での継続的な研究が、より多くの人々、特に最も必要としている人々にとって音声インターフェースをアクセスしやすくする事を願っています。これを実現するための重要な要素の1つは、データの収集です。18歳以上であれば、音声データを寄付することで、より優れたパーソナライズモデルの構築を支援できます。
興味がある場合は、下部リンクから「Google Project Euphonia – Interest Form」に記入して、Googleからの連絡を許可することができます。
謝辞
この作業は、ALSセラピー開発研究所とALSコミュニティ、特にFernando Vieira、Maeve McNally、Taylor Charbonneau、Melissa Nollstadt、そして親切で忍耐強くボランティアをしてくれたALS患者の皆さんの多大な努力と支援なしには不可能だったでしょう。
この作業は、Googleの音声チームによる音声認識の先駆的な進歩、特にエンドツーエンドの音声認識モデルの最近の開発と展開に基づいています。Googleのスピーチチーム、特に初期モデルのトレーニングで私たちを導いてくれたAnshuman TripathiとHasim Sakにアドバイスと協力に感謝します。
また、技術的な貢献とプロジェクトガイダンスについてOran Lang, Omry Tuval, Michael Brenner, Julie Cattiau, Tara Sainath, Ding Zhao, Qiao Liang, Chung-Cheng Chiu, Dan Liebling, Ron Weiss, Anjuli Kannan, Dimitri Kanevsky, Ryan He, Gabor Simko, Benjamin Lee, Françoise Beaufays, Khe Chai Sim, Jimmy Tobin, Chet Gnegy, Jacqueline Huang, Ye Jia, Yu Zhang, Yonghui Wu, Michelle Ramanovich, Rus Heywood, Katrin Tomanek, Bob MacDonald, Pan-Pan Jiang, Ronnie Maor, Rif A. Saurous, Trevor Strohman, Dick Lyon, Avinatan Hassidim, Philip Nelson, そしてYossi Matiasに感謝します。
3.Project Euphoniaの非標準音声用にパーソナライズした音声認識(2/2)関連リンク
1)ai.googleblog.com
Project Euphonia’s Personalized Speech Recognition for Non-Standard Speech
2)arxiv.org
Personalizing ASR for Dysarthric and Accented Speech with Limited Data
3)www.blog.google
How AI can improve products for people with impaired speech
4)ieeexplore.ieee.org
Adapting acoustic and lexical models to dysarthric speech
