
1.データ拡張を教師なしで実現し半教師付き学習の性能を向上(2/2)まとめ
・UDA、教師なしデータ拡張を使うと半教師付き学習が教師付き学習を上回る性能を出すようになる
・拡張元となるラベル付きデータが少なくとも多くとも教師付き学習の最先端のスコアを上回った
・また、UDAは画像分類タスクで既存の全ての半教師付き学習のスコアを上回った
2.UDAとは?
以下、ai.googleblog.comより「Advancing Semi-supervised Learning with Unsupervised Data Augmentation」の意訳です。元記事の投稿は、2019年7月10日、Qizhe XieさんとThang Luongさんによる投稿です。
自然言語処理と視覚処理でのベンチマーク
UDA(Unsupervised Data Augmentation)は、利用できるラベルき付データが少ないケースで驚くほど効果的です。わずか20のラベル付きサンプルを元に、UDAは50,000のラベルなしサンプルを作り出すことによってIMDb感情分析タスクでエラー率4.20を達成しました。この結果は、25,000のラベル付きサンプルで訓練されたエラー率4.32の最先端の教師付き学習モデルが出したスコアよりも優れています。
大規模データが利用できるケースでは、完全なトレーニングセットを使用して、UDAはまた着実な性能向上をもたらします。
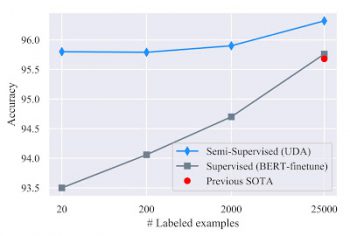
感情を分析するIMDbのベンチマーク。
UDAは、様々なトレーニングサイズで、教師あり学習モデルの最先端の結果を上回っています。
CIFAR-10を使った半教師付き学習(SSL:Semi-Supervised Learning)ベンチマークで比較した結果、UDAは、VAT、ICT、MixMatchなど、既存の全てのSSL手法よりも大幅に優れています。
ラベル付サンプルを4,000使用したUDAは5.27の誤り率を達成しており、これは50,000のラベル付サンプルを使用する完全教師付き学習モデルの性能に匹敵します。
更に、より高度なアーキテクチャであるPyramidNet + ShakeDropにより、UDAは2.7という新しい最先端のエラー率を達成し、過去の最高の半教師付き学習のスコアと比較してエラー率を45%以上削減しました。
SVHNでは、UDAは250のラベル付きサンプルのみで2.85のエラー率を達成し、これは約70,000のラベル付きサンプルでトレーニングされた完全教師付き学習モデルの性能と一致します。
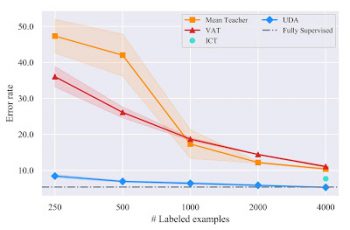
画像分類作業CIFAR-10で実行したSSLベンチマークの比較結果
UDAは、既存の全ての半教師付き学習(全てWide-ResNet-28-2アーキテクチャを採用しています)を上回っています。4000事例では、UDAは50,000事例で学習した完全教師付きモデルのパフォーマンスに匹敵します。
10%のラベル付きデータ含むImageNetでは、UDAはtop-1精度を55.1%から68.7%に向上させました。完全にラベル付されたセットと1.3Mの追加のラベリングされていないデータが利用可能な大規模データ利用可能体制下では、UDAはtop-1精度を78.3%から79.0%に更新させ続けています。
リリース
UDAのコードを私達の研究結果を再現可能なように、全てのデータ拡張手法と共にリリースしました。リリースされたデータ拡張手法には、例えば事前訓練済み翻訳モデルによる逆翻訳などが含まれます。このリリースによって、半教師つき学習の進歩がさらに進むことを願っています。
謝辞
論文の共著者であるZihang Dai, Eduard Hovy, Quoc V. Leに感謝します。また、Hieu Pham, Adams Wei Yu, Zhilin Yang, Colin Raffel, Olga Wichrowska, Ekin Dogus Cubuk, Guokun Lai, Jiateng Xie, Yulun Du, Trieu Trinh, Ran Zhao, Ola Spyra, Brandon Yang, Daiyi Peng, Andrew Dai, Samy Bengio そして Jeff Deanのこのプロジェクトへの協力に感謝します。論文「Unsupervised Data Augmentation for Consistency Training」のプレプリントはオンラインで入手できます。
3.データ拡張を教師なしで実現し半教師付き学習の性能を向上(2/2)関連リンク
1)ai.googleblog.com
Advancing Semi-supervised Learning with Unsupervised Data Augmentation
2)github.com
google-research/uda
3)arxiv.org
Unsupervised Data Augmentation for Consistency Training
