
1.グラフデータを機械学習で扱いやすくするための革新(1/3)まとめ
・グラフはノード(頂点)とエッジ(辺)で構成され概念間の関係を表す事が出来る
・しかしグラフは離散的データであり機械学習が好む連続的データではない
・グラフを機械学習で良く使われるベクトルデータに変換する方法が必要となる
2.グラフデータを機械学習で扱うために必要な事
以下、ai.googleblog.comより「Innovations in Graph Representation Learning」の意訳です。元記事は2019年6月25日、Alessandro EpastoさんとBryan Perozziさんによる投稿です。
概念間の関係を表す関係データは、ウェブ上(オンラインのソーシャルネットワーク)や物理的世界(例えばタンパク質相互作用ネットワーク)に偏在しています。
このようなデータは、ノード(頂点。例えば、SNSのユーザやタンパク質)と、ノード間を接続するエッジ(辺。例えば、友人関係やタンパク質の相互作用)を有するグラフとして表すことができます。
グラフが広く普及していることを考えると、グラフの分析は、クラスタリング、リンク予測、プライバシーなどの用途で、機械学習においても基礎となる技術です。
グラフに機械学習手法を適用する(例えば、新たしく友情が生まれそうな繋がりを予測する、又は、まだ知られていない未知のタンパク質間に存在する相互作用を発見する)ためには、機械学習アルゴリズムが利用しやすいようなグラフの特徴表現を知る必要があります。
しかしながら、グラフは本質的にノードやエッジによる散らばった状態(離散的)で構成される組み合わせ構造ですが、ニューラルネットワークなどの一般的な機械学習法の多くは連続構造、特にベクトル表現を好みます。
ベクトル表現は、入力レイヤとして直接使用できるため、ニューラルネットワークでは特に重要です。
機械学習で離散的なグラフ表現を使用する際の問題を回避するために、グラフをembeddingsに変換する手法があります。この手法はグラフ内の各ノード(またはエッジ)をベクトル空間内の特定の位置に割り当て、グラフを連続するベクトル空間に変換します。
この分野で一般的なアプローチは、DeepWalkで紹介されているようなランダムウォークベースの表現学習です。
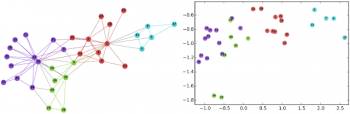
左:ソーシャルネットワークのグラフとして有名な空手クラブの関係性を示したグラフ。
右:DeepWalkを使ってグラフ内のノードを連続的なembeddingsに変換した結果
以下では、グラフのembeddingsに関する最近の2つの論文を紹介します。
WWW’19で発表された「Is a Single Embedding Enough? Learning Node Representations that Capture Multiple Social Contexts」とNeurIPS’18で発表された「Watch Your Step: Learning Node Embeddings via Graph Attention」です。
最初の論文では、ノードごとに複数のembeddingsを学習する新しい手法を紹介し、この手法は、ネットワークのコミュニティが重複しているケースでより良い特性表現を可能にします。
2つ目は、グラフのembeddingにおけるハイパーパラメーター調整の根本的な問題を解決します。この手法により、グラフのembeddingsをより少ない労力で簡単に配置できます。
また、グラフのembedding用のGoogle Research githubレポジトリで両方の論文のコードを公開したこともお知らせいたします。
3.グラフデータを機械学習で扱いやすくするための革新(1/3)関連リンク
1)ai.googleblog.com
Innovations in Graph Representation Learning
2)arxiv.org
Is a Single Embedding Enough? Learning Node Representations that Capture Multiple Social Contexts
3)papers.nips.cc
Watch Your Step:Learning Node Embeddings via Graph Attention(PDF)
4)github.com
google-research/graph_embedding/

