
1.新たに6モデルを追加したControlNet1.1が公開まとめ
・一週間くらい前に従来の8モデルの改良版+6モデルを追加したControlNet1.1がリリースされた
・線画を自在に色塗りする事ができるLineart系の機能も追加されたため注目度は高いが動作環境が混乱気味
・期間限定でオンライン講座内で利用可能な学習システムを無料体験できるようにしてあるので体験可能
2.ControlNet1.1とは?
アイキャッチ画像は何かをコントロールしている感じのイメージをchatGPT先生に伝えて作って貰ったプロンプトを私が修正してカスタムStable Diffusion先生に作って貰ったイラスト
2023年5月追記)直近、ControlNetは怒涛の勢いでアップデートが行われています。以下の記事も読んでおくとよいと思います。「Reference-only ControlNet:ついに前処理さえ不要になったコントロールネット」
ControlNetはイラスト生成AIの世界でゲームチェンジャーとなった新手法です。
Stable Diffusion等の従来のイラスト生成AIはプロンプトで大まかなポーズや構成を指定する事は出来ますが、細かい指定をする事は出来ませんでした。ControlNetは参照用の画像を与えると、その画像からポーズや構図を前処理で抽出し、その抽出した情報 + 使用者が与えたプロンプトを使って画像を生成するようにモデルに強いる事が出来るため、非常に自由且つ柔軟にポーズを指定できるようになったのです。
そして、少し前にControlNet1.0の更新版であるControlNet1.1がリリースされました。
Version番号は0.1しかあがっておらず、アーキテクチャは1.0と同じです。しかし、データセットを見直して全体的な品質が向上しており、アーキテクチャが変っていないので従来の仕組みにそのまま適用する事ができます。更に、1.0の8モデルに対してControlNet 1.1は14のモデルが含まれており、内訳は11の完成モデル、3つの実験モデルとなります。
また、本家lllyasvielさんが作成したモデル以外にも先日紹介したStable Diffusion 2.1系列用のモデルやMediaPipeを使ったMediaPipe Face Controlなど、様々な第三者モデルが登場しているため、ファイルの命名規則が新たに定められたとの事
(project name)_(version flag)(quality flag)_(Base SD Model)_(control method).pth
確かに、例えば顔をターゲットしたものであっても新たにjosephcatrambone-crucibleさんが作成したMediaPipe Face Control用のものであったり、openpose faceであったりと、複数のモデルが存在するので、どのケースに何を使うべきかが多少はわかりすくなりましが、それでもやっぱり前処理モデルとControlNetのモデル数が多すぎて中々厳しいです。
ControlNet1.0公開当時の記事については「ControlNet:棒人間で表現した好きなポーズをAIでイラスト化する」をご覧ください
全くの初心者の方向けに現在の状況を整理すると
・ControlNetはそれ単体でも画像を生成可能な独立したプロジェクトです。
・Stable Diffusionを動かす際に良く使われる人気の高いAUTOMATIC1111/webuiとの直接の関係はありません。
・しかしControlNetをAUTOMATIC1111/webuiで動かすための拡張機能「Mikubill/sd-webui-controlnet」が存在します。
・AUTOMATIC1111/webuiは、Version 1.1のリリース作業に集中しているため直近4週間くらい更新が止まっています。更新停止前後で、pytorch2.0がリリースされたり、gradioも3.28になったり、動作に必要な主要ライブラリに大きな更新がありました。そのため、人によってはVersion 1.0最新版のAUTOMATIC1111/webuiが動かなくなってしまっています。不具合を回避するため、少し古い版のAUTOMATIC1111/webuiを使っている人も多いと思うのですが、その場合、Version 1.0最新版のAUTOMATIC1111/webuiで動作確認している拡張機能が逆に動かなくなってしまっているケースなどもあり、私も最新版が問題なく動作可能になるタイミングを待とうと思っていたのですが、いつになるのかわからないので今回、状況を整理してみる事にしました。
・「Mikubill/sd-webui-controlnet」のインストール方法そのものは変わっていません。使い方も含めて過去記事「Stable Diffusion 2.1用のControlNetのセットアップ方法」に書いてあるので興味のある方はご確認ください。
・ControlNet 1.1を動かすためには「前処理を行うモデル(annotator/preprocessor)」と「前処理に対応したControlNet1.1用のモデル」と「Stable Diffusin1.5、もしくは1.5をベースにカスタマイズしたモデル」の3つが必要です。
・前処理を行うモデルは必要になった時にスクリプトが自動でダウンロードしてくれるようになっているので気にする必要はありません。「ControlNet1.1用のモデル」は、lllyasviel/ControlNet-v1-1から使いたいモデル(.pth)をダウンロードしてmodels/ControlNetフォルダに格納する必要があります。設定ファイル(yaml)は配布パッケージ内に全て含まれるようになりました。Stable DiffusinのモデルはStable Diffusion 1.5系列のものであったら何もせずにそのまま使えます。Stable Diffusion 2.1系列のモデル(Waifu Diffusion1.5など)用のControlNet1.1はまだ公開されていないと思います。
ControlNet 1.1の使い方
基本的な流れは以下です。
1)参考にしたい画像を選ぶ or 自分でControlNet拡張機能内のキャンパスに落書きを描く
2)1)の画像から何の特徴を抽出したいのかを考えて、その特徴によって適切な前処理モデルを選ぶ (沢山ある)
3)2)の前処理モデルに対応したControlnetモデルを選ぶ( 1.1だけで全14モデルで他にも沢山ある )
4)ControlnetのEnableチェックボタンをチェックして画像を生成する
2)の部分は、本記事の後半でも解説してありますが、Previewボタンで確認するのが手っ取り早いです。しかし、Previewボタンやキャンパスを出現させるボタンの位置が以前と少し変わっているので以下の動画で解説しています。
ControlNet 1.1の用途
様々な使い方ができると思いますが、自分が生成したイラスト、もしくは自分自身を取った写真からポーズを抽出して使う事を私はよくやります。
1)どうしても綺麗に生成出来ないイラストを2段階で生成する
AIチャットボットが幻覚を見て嘘をついてしまっている状態をイラストで表現したくなった事がありました。嘘をついている状態を絵で表現するためにピノキオを連想させるように鼻を伸ばしたかったのですが「鼻が伸びたロボット」を生成する事がどうしてもできなかったです(顎が伸びたりしてしまう)。そのため、普通のロボットを生成 → Controlnet Scribbleで枠を抽出 → 鼻を手書きで描き足してControlnet Scribbleで再生成、の流れで生成したイラストが以下です。妖精も単体で生成したものを枠抽出→小さくして手書き内に配置しています。
 ->
-> 
2)OpenPoseで綺麗な手やポーズを描く
自分の写真で挑戦してます。ポーズは行けますが、手はまだ試行錯誤が必要な実感があります。
3)ControlNet 1.1の実験的な機能を使う
1)と2)はControlNet 1.0でも実現できていた話です。ControlNet 1.1の実験的な用途として以下の3つがあります。それぞれ、ControlNetとは関係ない他のモデル/機能で従来も実現できていた機能ではあるのですが、ControlNetによってより高い精度や能力向上を実現しています。
3-1)Pix2Pix
プロンプトを使って画像全体を編集する事ができます。例:夜にする(make it night)で、画像を夜の場面にする事などが出来ます。従来のPix2Pixは専用のモデルが必要でしたが、ControlNetによって「ちょっと試す」と言う事が楽にできそうです。
3-2)Inpainting
画像の一部分だけを指定して描きなおす事ができます。仕組み的には動画にも対応できるポテンシャルがあるとの事です。
3-3)tile
本記事の後半で詳しく説明しますが「画像の解像度を上げる際に顔の部分だけを書き直して綺麗にする」事が出来てしまいます。
ControlNet 1.1用の14モデルの説明
以下、ControlNet 1.1と同時にリリースされた14モデルの紹介です。なお、これらはStable Diffusion 1.5用のモデルであるため、Stable Diffusion 2.1系のモデルでは使用できません。
1)ControlNet 1.1 Depth
モデル名「control_v11f1p_sd15_depth.pth」
深度マップを使って画像を制御します。
前処理はDepth_Leres, Depth_Zoe, Depth_Midasのいずれかにする事が必要です。
深度とは奥行情報の事で画像内の物体間の重なり具合などを抽出して制御情報に使用する事ができます。
Depth_Leres > Depth_Zoe > Depth_Midasの順で奥の方まではっきりと描写できます。
 original(秋の風景) |
 Depth_Leres |
 Depth_Leres + v11f1p_sd15(冬の風景) |
 Depth_Zoe |
 Depth_Zoe + v11f1p_sd15(冬の風景) |
|
 Depth_Midas |
 Depth_Midas + v11f1p_sd15(冬の風景) |
2)ControlNet 1.1 Normal
モデル名「control_v11p_sd15_normalbae.pth」
法線マップを使って画像を制御します。
前処理はNormal BAEにする事が必要です。
こちらも3D系画像を得意とする手法でゴテゴテした重なり具合を抽出して制御情報に使用する事ができます。
 |
 |
 |
3)ControlNet 1.1 Canny
モデル名「control_v11p_sd15_canny.pth」
キャニーを使って画像を制御します。
前処理はCannyにする事が必要です。
キャニーは画像内のふちを検出するアルゴリズムで写真なども扱う事ができます。
 |
 |
 |
 |
 |
 |
4)ControlNet 1.1 MLSD
モデル名「control_v11p_sd15_mlsd.pth」
ワイヤーフレーム(境界線)を検出する仕組みであるM-LSDを使って画像を制御します。
前処理はMLSDにする事が必要です。
室内画像などを上手く処理できるようです。
 |
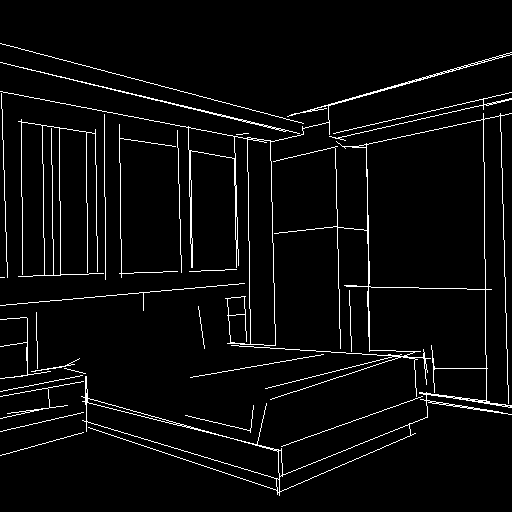 |
 |
5)ControlNet 1.1 Scribble
モデル名「control_v11p_sd15_scribble.pth」
手書きの落書きを使って画像を制御します。
前処理はScribble_HED, Scribble_PIDI、Scribble_XDOGにする事が必要です
画像内の枠線をおおざっぱに捉える事が可能で、手書きの線にも対応できます。
scribble xdog> scribble pidinet> scribble hedの順に精度が向上します。制度が高いと忠実度も増しますが、遊びがあった方がウサギの耳等で自然な画像が出来るケースもあります。
 original 手書きの円 |
 scribble xdog |
 xdog(ウサギ) |
 scribble_pidinet |
 pidinet(ウサギ) |
|
 pidinet(エイリアン) |
||
 scribble_hed |
 hed(ウサギ) |
6)ControlNet 1.1 Soft Edge
モデル名「control_v11p_sd15_softedge.pth」
人間の視覚特性に着目した境界抽出手法であるソフトエッジを使って画像を制御します。
前処理はSoftEdge_PIDI、SoftEdge_PIDI_safe、SoftEdge_HED、SoftEdge_HED_safeにする事が必要です。
推奨はSoftEdge_PIDだそうです。
ソフト エッジは画像内のふちを服のしわなどの柔らかい部分も含めて検出できます。
softedge pid > softedge pidsafe > softedge hed > softedge hedsafe の順に細かい描写にも対応できている感じでしょうか。
 original |
 softedge pid |
 softedge pid(ドレスをワインレッドに) |
 softedge pidsafe |
 softedge pidsafe(ドレスをワインレッドに) |
|
 softedge hed |
 softedge hed(ドレスをワインレッドに) |
|
 softedge hedsafe |
 softedge hedsafe(ドレスをワインレッドに) |
7)ControlNet 1.1 Segmentation
モデル名「control_v11p_sd15_seg.pth」
各領域を画素単位で塗り分けて区別するセマンティック セグメンテーションを使って画像を制御します。
前処理はSeg_OFADE20K, Seg_OFCOCO, Seg_UFADE20Kまたは手動作成したマスクにする事が必要です。
画像内の物体の配置を切り分ける事が出来るので風景画などに優れています。
Seg_UFADE20K > Seg_OFADE20K > Seg_OFCOCO の順に感度があがっているように見えます。
※ 美女がキングコングから逃げている構図にしようとしていたのですが、美女は画面内から逃げて戻りませんでした。
 original |
 Seg_UFADE20K |
 Segmentation UFADE(背景の岩をking kongに) |
 Seg_OFADE20K |
 Segmentation OFADE(背景の岩をking kongに) |
|
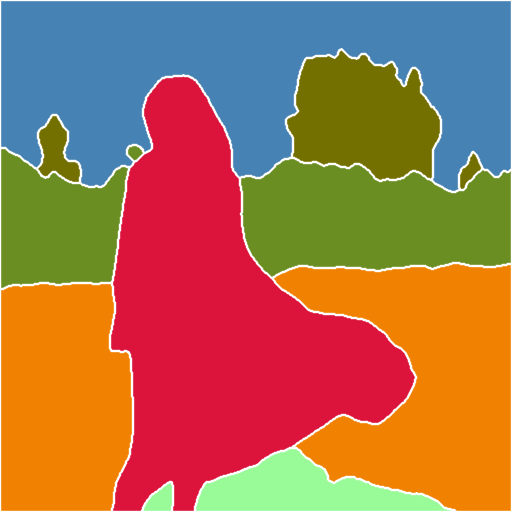 Seg_OFCOCO |
 Segmentation OFCOCO(背景の岩をking kongに) |
8)ControlNet 1.1 Openpose
モデル名「control_v11p_sd15_openpose.pth」
人間のポーズを棒人間形式で抽出する事ができるOpenposeを使って画像を制御します。
前処理はbody, hand, faceを組み合わせる事ができますが複雑すぎるので以下が用意されています。
「Openpose」とはOpenpose bodyの事です。
「Openpose Full」とはOpenpose body + Openpose hand + Openpose faceの事です。
人のポーズを抽出する際に安定した性能で複数の人が映っていても対応できますが、手はまだ何かをもってしまったりバランスが崩れてしまう事もあります。以下は出来の良かったものを選別するのではなく敢えて初回生成画像を掲載しています。
 original |
 openpose full |
 openpose_full(angel) |
 openpose_full(angel) |
||
 openpose hand |
 openpose hand(a girl) |
|
 original |
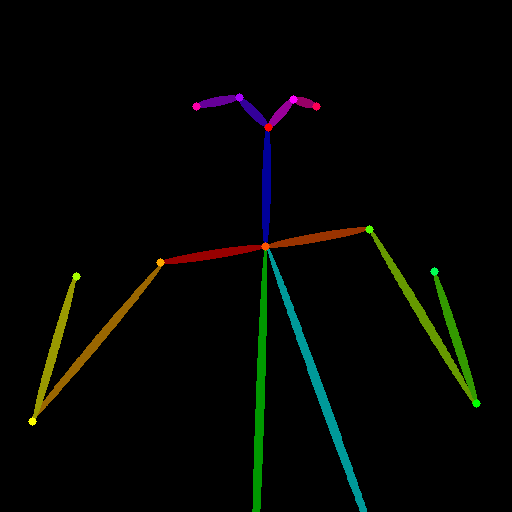 openpose |
 openpose(photo quality girl) |
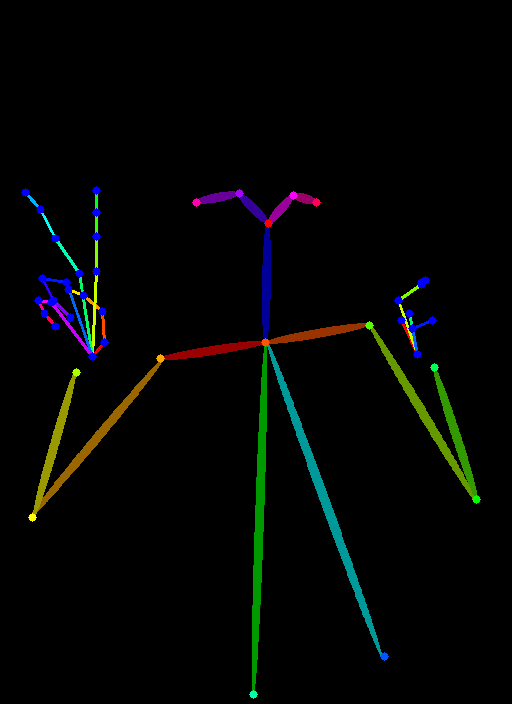 openpose hand |
 openpose hand(photo quality girl) |
|
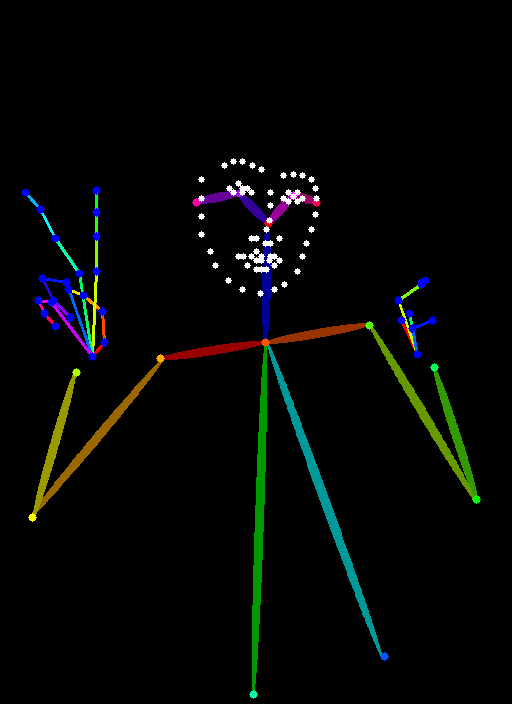 openpose full |
 openpose full(photo quality girl) |
9)ControlNet 1.1 Lineart
モデル名「control_v11p_sd15_lineart.pth」
線画を使って画像を制御します。
前処理はLineartかLineart_Coarseにする事が必要です。
線画を色塗りする使い方が出来るためControlNet 1.1で注目を集めている新モデルです。
10)ControlNet 1.1 Anime Lineart
モデル名「control_v11p_sd15s2_lineart_anime.pth」
アニメ系のイラストレーションを線画を使って制御します。
前処理は明記されていませんがおそらくLineartかLineart_Coarseと思います。
二次元絵の線画を色塗りする使い方が出来るためControlNet 1.1で注目を集めている新モデルです。
 original |
 lineart_anime_denoise |
 anime lineart_denoise(髪を銀色に) |
 lineart_anime |
 anime lineart(髪を銀色に) |
11)ControlNet 1.1 Shuffle
モデル名「control_v11e_sd15_shuffle.pth」
画像をシャッフルした再構成する事が出来るモデルです。
主にスタイルを変更する用途で使用される想定のようです。
12)ControlNet 1.1 Instruct Pix2Pix
モデル名「control_v11e_sd15_ip2p.pth」
Controlを使って、Instruct Pix2Pixと同等の事ができるモデルです。
例えば、「建物の画像」に「火をつける(make it on fire)」として燃えている画像を生成できるとの事。
「YをXにする(make Y into X)」より「Xにする(make it into X)」の方がプロンプトの効きが良いとの事です。
アイコン的なイラストを未来感溢れる感じにInstruct Pix2Pixした例
![]() ->
-> ![]()
13)ControlNet 1.1 Inpaint
モデル名「control_v11p_sd15_inpaint.pth」
画像の一部をマスクしてその部分を変更するinpaint用のモデルです。
将来的には動画にも対応可能になるかもしれないとの事です。
14)ControlNet 1.1 Tile
モデル名「control_v11u_sd15_tile.pth」
4月25日に更新版の「control_v11f1e_sd15_tile.pth」が出ており、未完成モデルから実験的なモデル扱いになりました。
より大きな画像を生成する際に有用となる機能を試す実験的なモデルです。
大きな画像を生成する際は一気に作成する事はメモリなどの制限で難しいので、少しずつ(タイル単位で)書き足していく事になりますが、そうすると「1人の綺麗な女の子」を描きたくとも書き足す度に「綺麗な女の子」も書き足されてしまって複数の「綺麗な女の子」の絵が出来てしまう事が多いです。ControlNet 1.1 Tileは、タイル内に描かれている物体を認識し、その物体の影響を増加させる事で、主題が複数描かれるような状況を防止する事目指しているとの事です。
以下はTileを使って768×768 -> 1200×768にアップスケーリングした例です。
従来のシンプルなアップスケーリング(超解像度手法)は画素間を補完して引き延ばすだけなので、画面に映っている物は変わらなかったです。ControlNetのTileを使ったアップスケーリングはプロンプトで指定した部分(この例では「人」)を認識し、プロンプトに従って描き直し(この例では「学生服を着た卒業写真」)ています。(更に付け加えれば、「人」と関係ない背景などは関係ない部分と認識してくれるので無理やり人の顔をつけ足したりしない)。同じ顔に見えますが、これはまだ私の試行錯誤が足りないためです。
 original |
 crop_and_resize_balanced |
 crop_and_resize_my_prompt_important |
|
 crop_and_resize_controlnet_important |
|
 resize_and_fill_controlnet_important |
以下は、OpenPoseで生成した512 x 512のイラストをTileで1024 x 1024にアップスケールしつつ、同時に顔を描き直したものです。このように全体として綺麗なイラストだけれども、人の顔だけ変、と言った残念な画像をアップスケーリングしつつ描き直してくれる用途にも使える有用な手法だと思います。
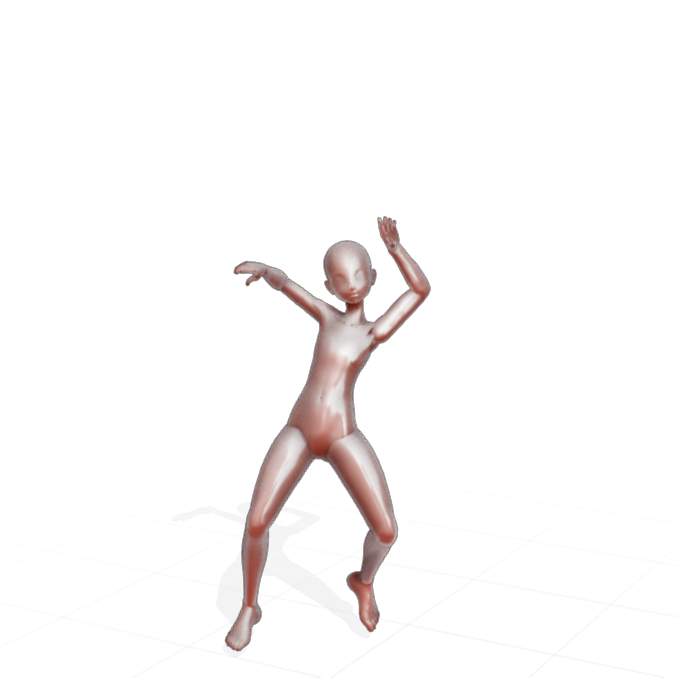 original |
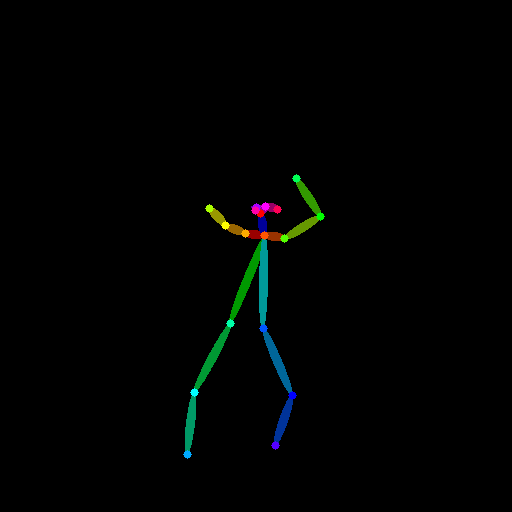 openpose前処理 |
 openpose(dancing kimono girl) |
| tile |  resize_and_fill(dancing kimono girl) |
|
 resize_and_fill(dancing kimono girl) |
以上、14モデルを紹介しましたが、上記に加えて前述の「MediaPipe Face Control」は1.5モデルと2.1モデルが両方出ている事もあり、前処理を含めるとかなりの数になっており、私もまだ全部を動かして試す事が出来ていません。
ですので、期間限定ではありますが、下記リンクよりオンライン講座内で利用可能な学習システムを無料体験できるようにしてあります。
無料体験期間は終了しました。

3.新たに6モデルを追加したControlNet1.1が公開関連リンク
1)github.com
lllyasviel / ControlNet-v1-1-nightly
Mikubill/sd-webui-controlnet
2)huggingface.co
lllyasviel / ControlNet-v1-1 (モデルのダウンロード先)
CrucibleAI / ControlNetMediaPipeFace (MediaPipeFaceのダウンロード先)

