
1.2022年のGoogleのAI研究の成果と今後の展望~MLとコンピュータシステム編~(2/3)まとめ
・最近のMLPerfのコンペでは、TPUs v4が5つのベンチマークで新記録を達成し、2位に比べて平均1.42倍の差をつけた
・プラットフォーム対応型NASは、ニューラルアーキテクチャー探索(NAS)の探索空間にハードウェアの知識を取り入れた
・NaaSは、ニューラルネットワークアーキテクチャとハードウェアアーキテクチャを一緒に探索して更に性能が向上した
2.ハードウェアアクセラレータと機械学習
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Responsible AI」の意訳です。元記事の投稿は2023年2月2日、Mangpo PhothilimthanaさんとAdam Paszkeさんによる投稿です。
この昨年の振り返りシリーズは基本、過去にai.googleblog.comに投稿済みで既知のお話が多いのですが、新たな学びは常にあって、今回も凄い勉強になりました。
今ってモデルのアーキテクチャ探索とハードウェアのアーキテクチャ探索を同時にやる時代になっているのですね。
特定のタスクを効率よく処理できるモデルを設計するためには従来は職人芸が必要でしたが、2018年、自動で効率的な設計を探索(NAS:Neural Architecture Search)するAutoMLが発表され、それが2019年、視覚タスクで良く使われるEfficientNetモデルに繋がり、その後、特定のハードウェア上でより効率的に実行できるように調整されたEfficientNet-EdgeTPU等に進化していきました。更に、2021年にはより汎用的にハードウェアを意識してアーキテクチャを探索する「プラットフォームを意識したNAS(platform-aware NAS)」になりました。
ハードウェア側からも、チップやアクセラレータの設計時に効率的にMLを実行できるアーキテクチャを自動探索する研究が行われてきました。
しかし「モデルの探索とハードウェアの探索を別々にやるのって効率悪くない?同時に探索した方が良くない?」って事で、今の最先端は「NaaS(Neural Architecture and Accelerator Search)」と言って、ニューラルネットワークアーキテクチャとハードウェアアーキテクチャを一緒に探索する時代になっているとの事です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成
機械学習(ML:Machine Learning)用ハードウェアの設計
TPUやGPUなどのカスタマイズされたハードウェアの使用は、性能向上とエネルギー効率(つまり温室効果ガスの削減)の両面において、非常に大きなメリットを示しています。
最近のMLPerfのコンペでは、TPUs v4が5つのベンチマークで新記録を達成し、2位に比べて平均1.42倍のスピードアップを達成しました。しかし、最近の進歩に対応するため、特定の普及モデル向けにカスタマイズしたハードウェアアーキテクチャの開発も行っています。
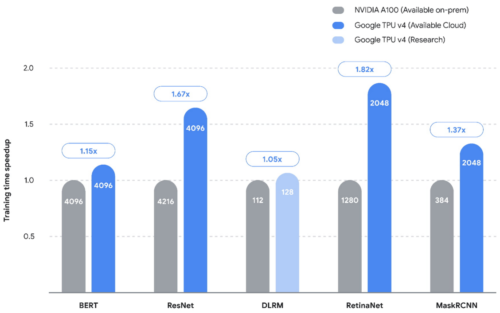
TPUは、公表されている5つのベンチマーク(MLPerf 2.0)すべてにおいて、Google以外で最速のエントリー(NVIDIA社の社内環境での計測)を上回る大幅なスピードアップを実証しました。棒グラフは背が高いほど良い事を表現しています。棒グラフの中の数字は、各エントリーに使用されたチップ/アクセラレータの数量を表しています。
しかし、ハードウェアアクセラレータを新たに構築するには、高い初期コストと開発・導入時間が必要です。
シングルワークロードアクセラレータを実現するためには、設計のサイクルタイムを短縮する必要があります。フルスタックサーチテクニック(FAST:Full-stack Search Technique)は、データパス、スケジューリング、重要なコンパイラの決定を同時に最適化するハードウェアアクセラレータ検索フレームワークを導入することで、この問題に対処しています。
FASTは、多様なアーキテクチャと汎用的なメモリ階層を記述できる近似テンプレートを導入したアクセラレータを実現しました。
その結果、TPU v3と比較して、熱設計消費電力(総所有コスト(TCO)あたりの性能と高い相関があることが知られています)あたりの単一負荷性能が3.7倍向上しました。このことから、シングルワークロードアクセラレータは、中規模のデータセンターで実用化できる可能性があることがわかります。
ハードウェア設計のためのML
チップ設計プロセスを可能な限り自動化するために、私達は高レベルのアーキテクチャ探索、検証、配置配線など、ハードウェア設計の様々な段階でMLの能力を押し上げることを続けています。
私たちは最近、Circuit Trainingと呼ばれる分散強化学習インフラを、最近のNature誌で紹介された回路環境(circuit environment)とともにオープンソース化し、このインフラを利用して、最新世代のTPUチップのマクロ配置を作成しました。
アーキテクチャ探索の取り組みであるPRIMEは、ハードウェアシミュレーションを行わずに、既存のデータ(例えば、従来のアクセラレータ設計の取り組みから)のみを利用する、ハードウェア設計空間を探索するためのMLベースのアプローチを導入しています。
このアプローチにより、ターゲットアプリケーションのセットが変更された場合でも、時間のかかるシミュレーションを実行する必要性を軽減することができます。PRIMEは、シミュレーション時間を93%~99%削減しながら、最先端のシミュレーション駆動型手法に比べて約1.2倍~1.5倍性能を向上させます。AutoApproxは、各ニューラルネットワーク層を適切な近似レベルにマッピングすることで、精度を損なうことなく近似的な低消費電力のディープラーニングアクセラレータを自動的に生成します。
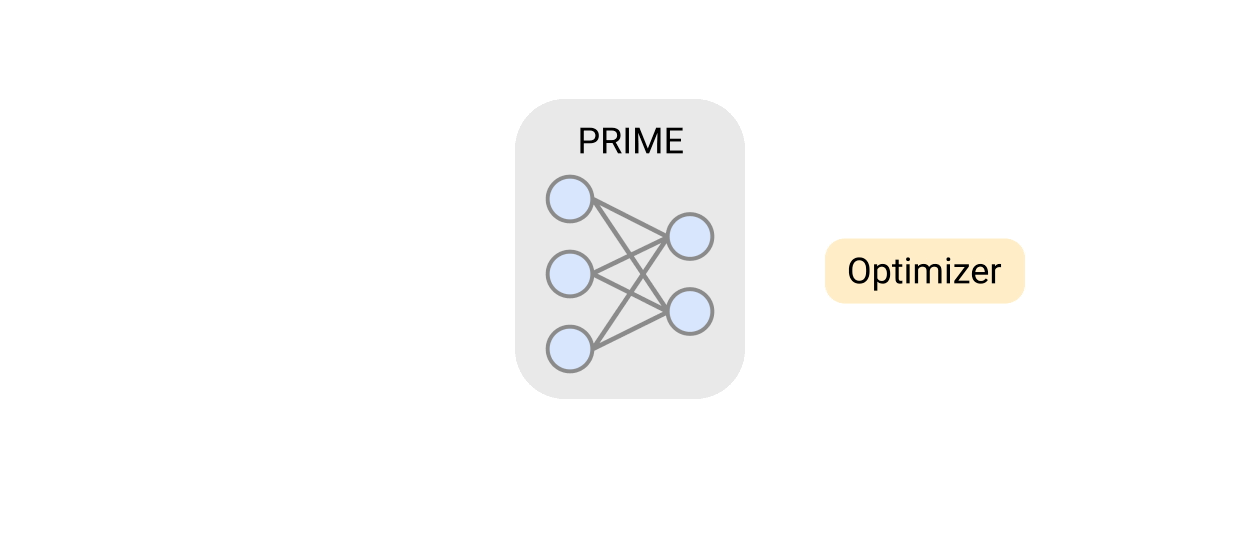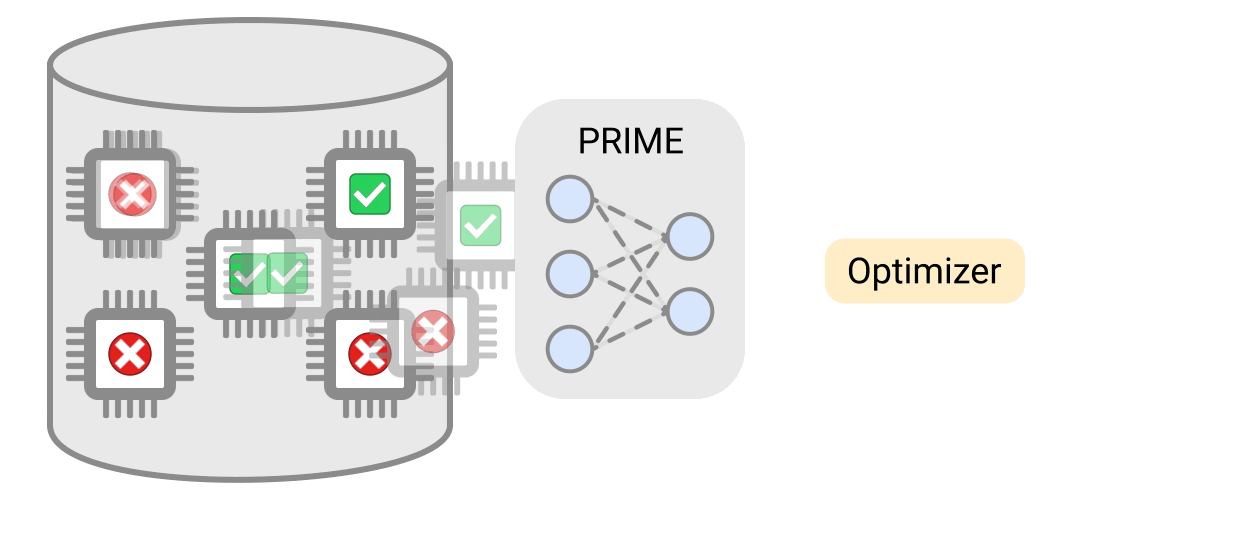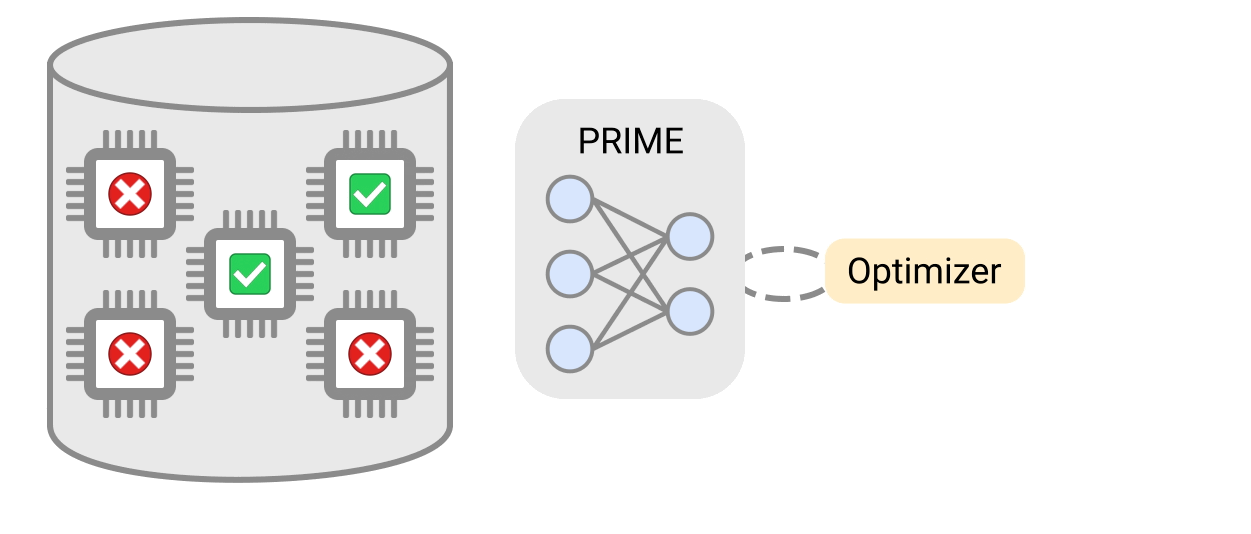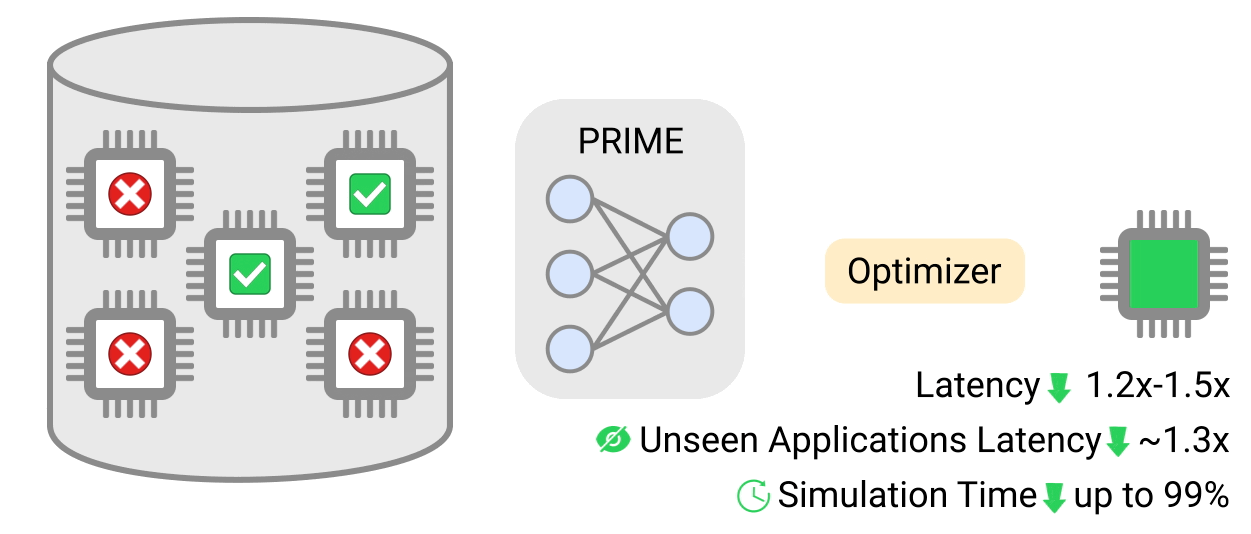
PRIMEは、実現可能なアクセラレータと実現不可能なアクセラレータの両方からなるアクセラレータのログデータを使用して伝統的なモデルを学習し、設計制約を満たしながらアクセラレータを設計するために使用されます。PRIMEは、必要なハードウェアシミュレーション時間を最大99%削減しながら、最大1.5倍まで応答遅延が小さいアクセラレータを設計することができます。
ハードウェアに特化したモデルの設計
NASは、精度や効率の面で最先端のモデルを発見することに多大な能力を発揮していますが、ハードウェアの知識が不足しているため、まだ限界があります。
プラットフォーム対応型NASは、ニューラルアーキテクチャー探索(NAS:Neural Architecture Search)の探索空間にハードウェアアーキテクチャの知識を取り入れることで、このギャップを解決します。その結果、EfficientNet-Xモデルは、TPU v3およびGPU v100において、EfficientNetと同等の精度で、それぞれ1.5倍から2倍高速に処理することが可能となりました。
プラットフォームを意識したNAS(platform-aware NAS)とEfficientNet-Xの両方が実運用され、様々な実運用された視覚モデルにおいて、大幅な精度向上と最大40%の効率改善を実証しています。NaaS(Neural Architecture and Accelerator Search)は、ニューラルネットワークアーキテクチャとハードウェアアーキテクチャを一緒に検索することで、さらに進化しています。Edge TPUでこのアプローチを使用すると、NaaSは、同じ精度で2倍以上のエネルギー効率を持つ視覚モデルを発見することができます。
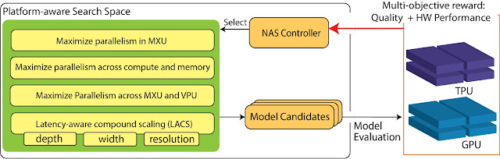
TPU/GPU上のプラットフォーム対応NASの概要、探索空間と探索目的を強調しています。
3.2022年のGoogleのAI研究の成果と今後の展望~MLとコンピュータシステム編~(2/3)関連リンク
1)ai.googleblog.com
Google Research, 2022 & beyond: ML & computer systems
2)github.com
google-research / circuit_training
