
1.EHR-Safe:プライバシー保護のために医療記録を合成して学習用データを生成(1/2)まとめ
・電子健康記録を機械学習で学習させる事は患者ケアなどに多大な可能性がある
・しかし、データのプライバシーを確保しながら学習させる事は簡単ではない
・EHR-Safeは学習用のデータを合成できる新アプローチで重要な特徴を維持可能
2.EHR-Safeとは?
以下、ai.googleblog.comより「EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records」の意訳です。元記事は2022年12月22日、Jinsung YoonさんとSercan O. Arikさんによる投稿です。
アイキャッチ画像はstable diffusion 2.1のDreamBooth拡張をstable diffusionのアウトペインティングで更にサイズ拡張した画像で、もっと看護士さんっぽくしたかったのですが、余計なものが映りこんでしまい中々難しく妥協した風の谷のナウシカ
電子健康記録(EHR:Electronic Health Records)の解析は、患者ケアの強化、臨床実践のパフォーマンスの定量的測定、臨床研究の促進に多大な可能性を持っています。
EHRデータで学習した統計的推定や機械学習(ML:Machine Learning)モデルは、さまざまな病気(糖尿病など)の発生確率の予測、患者の健康状態の追跡、特定の薬に対する患者の反応予測などに使用できます。
このようなモデルのために、研究者や実務家はEHRデータへのアクセスを必要とします。しかし、データのプライバシーを確保し、患者の守秘義務に関する規制(HIPAAなど)に準拠しながら、EHRデータを活用することは困難な場合があります。
従来の匿名化手法(例:非識別化)は、面倒でコストがかかることが多いです。さらに、元のデータセットから重要な特徴を歪めてしまい、データの有用性を著しく低下させる可能性があります。また、プライバシー侵害攻撃の影響を受ける可能性もあります。一方、合成データを生成するアプローチでは、データセットの重要な特徴とプライバシーの両方を維持することができます。
そこで、私達は論文「EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records」において新しい生成的モデリングのフレームワークを提案します。
私達はEHR-Safeにおいて、合成データが以下の2つの重要な特性を満たすことを示します。
(i)高い忠実度(high fidelity)
すなわち、診断モデルを学習させたときに下流タスクにおいて同等の性能を発揮できるなど、目的のタスクに有用である事
(ii)特定のプライバシー基準を満たす
すなわち、実際の患者の身元を明らかにしないこと
私達の最新の成果は、特徴のエンコード/デコード、複雑な分布の正規化、敵対的学習の条件付け、および欠損データの表現に対する新しいアプローチから生まれています。

EHR-Safeで元データから合成データを生成
リアルな合成EHRデータを生成するための課題
合成EHRデータを生成するためには、複数の基本的な課題があります。EHRデータは異なる特性や分布を持つ異質な特徴を含んでいます。
数値的特徴(例えば血圧)と、多数または2つのカテゴリを持つカテゴリ的特徴(例えば医療コード、最終的な患者の生死(mortality outcome))があり得えます。
これらの中には、静的なもの(すなわち、モデル化の間に変化しないもの)もあれば、定期的または散発的な検査測定など、時間的に変化するものもあります。
分布もさまざまな種類に分かれます。カテゴリカルな分布は非常に非一様であり(例えば、代表的なグループではない少数派グループ)、数値分布は非常に歪んでいる(例えば、値のごく一部が非常に大きく、大多数は小さい)可能性があります。
患者の状態によっては、受診回数が大きく異なる場合があります。1回しか受診しない患者もいれば、何百回も受診する患者もおり、他の時系列データと比較して、一般的に配列長に大きなばらつきが生じます。
すべての臨床検査値やその他の入力データが収集されているわけではないので、異なる患者や時間ステップ間で欠落した特徴の比率が高くなる可能性があります。
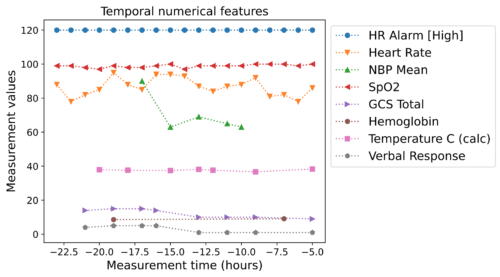
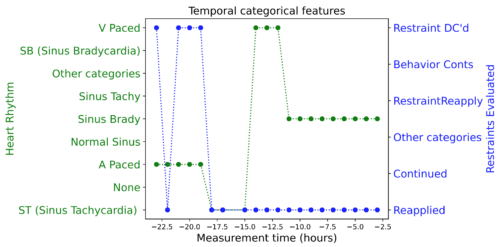
実際のEHRデータの例:時間的数値特徴(上)、時間的カテゴリ特徴(下)
EHR-Safe:合成EHRデータ生成フレームワーク
EHR-Safeは、下図に示すように、逐次エンコーダ・デコーダアーキテクチャと敵対的生成ネットワーク(GAN:Generative Adversarial Networks)から構成されています。EHRデータは前述のように異種混合データであるため、GANにとって生のEHRデータを直接モデル化することは困難です。これを回避するために、私達は逐次エンコーダ・デコーダアーキテクチャを利用し、生のEHRデータから潜在的な表現へのマッピング、あるいはその逆を学習することを提案します。
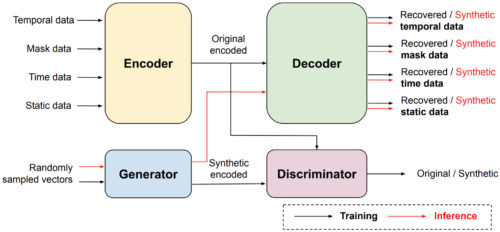
EHR-Safe:フレームワークのブロック図
マッピングを学習する際、数値で表現される特徴やカテゴリ値として表現される特徴の難解な分布は大きな課題となります。
例えば、あるカテゴリ値や数値範囲が分布の主要な部分を占める事になるかもしれませんが、稀なケースをモデル化する能力は不可欠です。
私達が提案する特徴マッピングと確率的正規化(元の特徴分布を情報を失わずに一様分布に変換する事)は、エンコーダーデコーダーやGANの学習がより安定する分布に変換する事が出来るので、このようなデータを扱う際の鍵となります。(詳細は論文に記載されています)
エンコーダで生成された潜在表現は、GANの学習に利用されます。エンコーダーデコーダーフレームワークとGANの両方を学習させた後、EHR-Safeは任意の入力から合成された異種混合EHRデータを生成することができます。生成する際、私達はランダムにサンプリングしたベクトルを供給します。
なお、合成データの生成には学習済みのジェネレータとデコーダのみが使用されます。
データセット
EHR-Safeのフレームワークを紹介するために、MIMIC-IIIとeICUという2つの実世界のEHRデータセットに焦点を当てます。どちらも入院患者のデータセットで、様々な長さのデータ長からなり、欠損成分を含む複数の数値およびカテゴリー特徴を含んでいます。
3.EHR-Safe:プライバシー保護のために医療記録を合成して学習用データを生成(1/2)関連リンク
1)ai.googleblog.com
EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records
2)www.researchsquare.com
EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records

