
1.QuaRL:強化学習を量子化して高速化と環境負荷を低減(2/2)まとめ
・ActorQでトレーニングの大幅な高速化と性能の維持が可能な事が確認された
・ポリシーの量子化で1.9倍から3.76倍まで炭素排出量の削減も確認された
・今後は他の形式の量子化、圧縮、スパース性を採用してトレードオフを探る
2.QuaRLの性能
以下、ai.googleblog.comより「Quantization for Fast and Environmentally Sustainable Reinforcement Learning」の意訳です。元記事の投稿は2022年9月27日、Srivatsan KrishnanさんとAleksandra Faustさんによる投稿です。
アイキャッチ画像はstable diffusionの生成
量子化で強化学習のトレーニングと性能を改善
Deepmind Control SuiteやOpenAI Gymなど、様々な環境でActorQを評価します。D4PGとDQNによる高速化と性能向上を実証します。D4PGはACMEでDeepmind Control Suiteのタスクに最適な学習アルゴリズムであり、DQNは広く使われている標準的な強化学習(RL:Reinforcement Learning)アルゴリズムであるため、これを選択しました。
RLポリシーの学習において、大幅な高速化(1.5倍から5.41倍)が観測されました。さらに重要なのは、アクターがint8量子化推論を行う場合でも、性能が維持されることです。以下の図は、Deepmind Control SuiteとOpenAI GymタスクのD4PGとDQNエージェントについて、これを示しています。
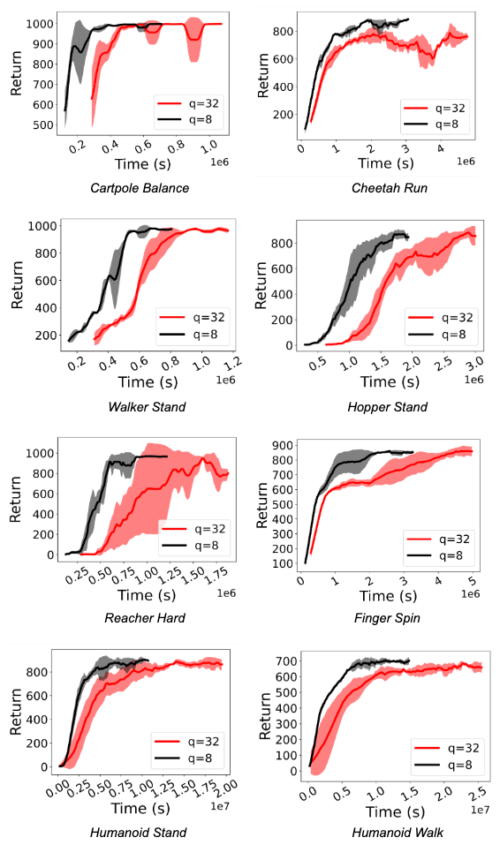
D4PGエージェントのFP32ポリシー(q=32)と量子化int8ポリシー(q=8)によるRL学習を、Deepmind Control Suiteの各種タスクで比較した結果。量子化により、1.5倍から3.06倍の高速化を実現しています。
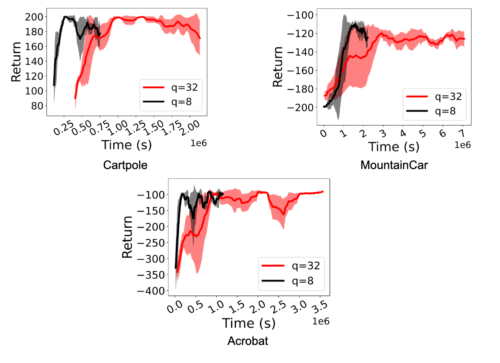
OpenAI Gym環境において,DQNエージェントのRL学習をFP32ポリシー(q=32)と量子化int8ポリシー(q=8)で比較した結果。量子化により、2.2倍から5.41倍の高速化を実現しています。
量子化により炭素排出量を削減
ActorQを用いたRLに量子化を適用することで、性能に影響を与えることなく学習時間を改善することができます。また、ハードウェアを効率的に使用することで、カーボンフットプリント(carbon footprint:温室効果ガスの総排出量)も削減することができます。ここでは、FP32を用いた場合の二酸化炭素排出量と、int8を用いた場合の二酸化炭素排出量の比を求め、二酸化炭素排出量の削減効果を測定しています。
RL学習実験のカーボンエミッションを測定するために、先行研究で提案された実験影響追跡システムを使用しました。ActorQシステムにカーボンモニターAPIを搭載し、各訓練実験のエネルギーと炭素排出量を測定します。
FP32で実行した場合の炭素排出量と比較すると、ポリシーの量子化により、タスクに応じて1.9倍から3.76倍まで炭素排出量が削減されることが確認されました。RLシステムは数千の分散ハードウェアコアやアクセラレータ上で動作するように拡張されているため、絶対的な炭素削減量(キログラム単位でCO2を測定)は非常に大きなものになると考えられます。
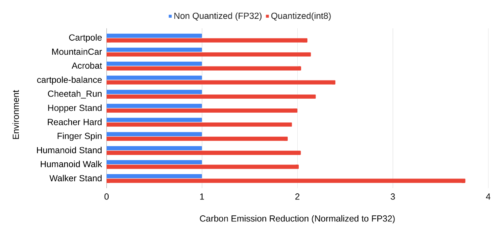
FP32 ポリシーと int8 ポリシーを用いたトレーニングのカーボンエミッションの比較。X軸のスケールは FP32 ポリシーのカーボンエミッションに正規化されています。1より大きい赤色のバーが示すように、ActorQは二酸化炭素排出量を削減しています。
まとめと今後の方向性
RLのトレーニングに量子化を適用し、性能を維持したまま 1.5~5.4 倍の高速化を実現する新しいパラダイム、ActorQ を紹介しました。さらに、ActorQは量子化を行わない全精度の学習と比較して、RL学習における二酸化炭素排出量を1.9~3.8倍削減できることを実証しました。
ActorQは、高品質で効率的な量子化ポリシーの取得から、トレーニング時間や二酸化炭素排出量の削減まで、量子化がRLの多くの側面に効果的に適用できることを実証しています。RLが実世界の問題解決に大きく貢献し続ける中、RL学習を持続可能なものにすることが、採用のために重要だと考えています。
RL学習を数千のコアやGPUにスケールアップした場合、(私達が実験的に示したように)50%の改善でも、絶対的なドルコスト、エネルギー、二酸化炭素排出量の大幅な削減を実現することができます。私達の研究は、量子化をRL学習に適用し、効率的で環境的に持続可能な学習を実現するための最初のステップとなるものです。
ActorQの量子化器の設計は単純な均一な量子化(uniform quantization)に依存していますが、私達は他の形式の量子化、圧縮、スパース性を適用できると考えています。(例:蒸留、疎化、など)。将来的には、より積極的な量子化・圧縮手法の適用を検討し、学習済みRLポリシーの性能と精度のトレードオフにさらなる利益をもたらすことが期待されます。
謝辞
共著者のMax Lam, Sharad Chitlangia, Zishen Wan, and Vijay Janapa Reddi(Harvard University), Gabriel Barth-Maron(DeepMind)に感謝します。また、この研究の根源となる研究クレジットを提供してくれたGoogle Cloudチームにも感謝します。
3.QuaRL:強化学習を量子化して高速化と環境負荷を低減(2/2)関連リンク
1)ai.googleblog.com
Quantization for Fast and Environmentally Sustainable Reinforcement Learning
2)openreview.net
QuaRL: Quantization for Fast and Environmentally Sutainable
Reinforcement Learning(PDF)

