
1.FindIt:テキストの指示に基づいて画像内からサンドイッチの左半分を特定可能な統合モデル(2/2)まとめ
・3つのタスク全てを同じ入力を取るように適応させ学習の効率化を行った
・全てのタスクに対して標準的な物体検出損失を使ったが驚くほど効果的だった
・テキストベースの位置特定タスクでは初見物体や親カテゴリにも汎化できた
2.FindItの性能
以下、ai.googleblog.comより「FindIt: Generalized Object Localization with Natural Language Queries」の意訳です。元記事は2022年9月20日、Weicheng KuoさんとAnelia Angelovaさんによる投稿です。
アイキャッチ画像はstable diffusionによる生成
マルチタスク学習
前述のマルチレベル融合とは別に、テキストベースの位置特定と物体検出タスクを、参照表現理解タスクと同じ入力を取るように適応(adapt)させます。
テキストベースの位置特定タスクでは、画像に存在するカテゴリとそれに対応する問い合わせ文をセットで生成します。
つまり、任意のカテゴリに対して、問い合わせ文を「Find the [object]」という形式をとるように生成します。ここで、[object]はカテゴリ名です。そのカテゴリに対応する物体は前景として、それ以外の物体は背景としてラベル付けされます。
物体検出タスクでは、先ほど作成した問い合わせ文を用いる代わりに、「全ての物体を見つけなさい(Find all the objects)」のような検出タスクのための固定した問い合わせ文を使用します。私達は、テキストベースの位置特定と物体検出タスクにおいて、問い合わせ文を洗練させる事は重要でないことを発見しました。
適応後、全てのタスクは同じ入力と出力、すなわち、画像入力、問い合わせ文、出力の境界ボックスとクラスのセットを共有します。次に、これらのデータセットを結合し、その混合物に対して学習を行います。最後に、全てのタスクに対して標準的な物体検出損失を用いますが、これは驚くほどシンプルかつ効果的であることが分かりました。
評価
FindItを参照表現理解(referring expression comprehension)タスクの代表的なベンチマークであるRefCOCOに適用しました。COCOとRefCOCOのデータセットのみが利用可能な場合、FindItは全てのタスクで最先端モデルよりも高い性能を発揮します。
外部データセットが許可されている設定では、FindItはCOCOと全てのRefCOCOデータ分割を一緒に使うことで(他のデータセットを使わない)、新しい技術水準を設定します。
難易度の高いGoogleやUMD設定におけるデータ分割では、FindItは10%幅で最先端モデルを上回り、マルチタスク学習の利点を実証しています。
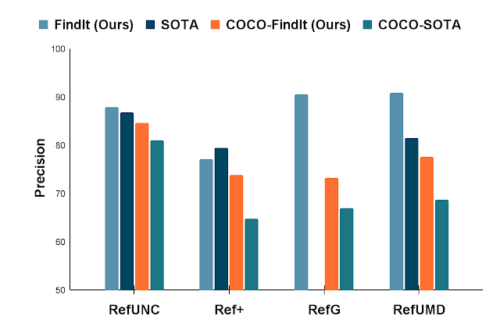
一般的な参照表現ベンチマークでの最先端技術との比較
COCOと制約なし(追加の学習データ可)の両設定でFindItが優れています。
テキストベースの位置特定ベンチマークにおいて、FindItは79.7%を達成し、GPV(73.0%)およびFaster R-CNN(75.2%)を上回りました。より定量的な評価については、論文を参照してください。
さらに、下図に示すように、FindItはCOCOおよびObjects365データセットにおいて、競合する単一タスクの比較対象手法と比較して、テキストベースの位置特定タスクにおいて新規カテゴリおよびスーパーカテゴリにうまく汎化することが確認されています。
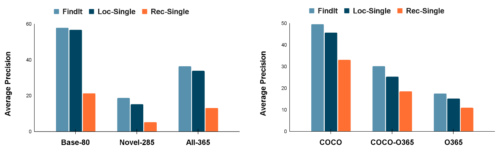
新規カテゴリとスーパーカテゴリにおけるFindIt
左:FindItは、特に新規カテゴリにおいて、単一タスクの比較対象手法を上回ります
右:FindItは、未知のスーパーカテゴリにおいて、単一タスクの比較対象手法よりも高い性能を示しました。「Rec-Single」は参照表現理解の単一タスクモデル、「Loc-Single」はテキストベースの位置特定を行う単一タスクモデルです。
効率性
また、参照表現理解タスクにおける推論時間の測定を行いました(下表参照)。
FindItは、より高い精度を達成しながら、既存の1段階のアプローチと同等の効率性を実現しています。公正な比較のため、すべての実行時間は1つのGTX 1080Ti GPUで測定されています。
| Model | Image Size | Backbone | Runtime (ms) |
| MattNet | 1000 | R101 | 378 |
| FAOA | 256 | DarkNet53 | 39 |
| MCN | 416 | DarkNet53 | 56 |
| TransVG | 640 | R50 | 62 |
| FindIt (Ours) | 640 | R50 | 107 |
| FindIt (Ours) | 384 | R50 | 57 |
まとめ
本稿では、参照表現理解、テキストベース位置特定、物体検出の各タスクを統合するFinditを紹介します。これらのタスクの多様な位置特定要件を統一するために、マルチスケールクロスアテンションを提案します。Finditは、タスクに特化した設計をすることなく、参照表現とテキストベースの位置特定において最先端技術を凌駕し、検出において競争力のある性能を示し、分布外データと新規クラスに対してより良く一般化することができます。これらは全て、単一の統一的かつ効率的なモデルで実現されています。
謝辞
本研究はWeicheng Kuo, Fred Bertsch, Wei Li, AJ Piergiovanni, Mohammad Saffar 及び Anelia Angelovaによって実施されたものです。また、Ashish Vaswani, Prajit Ramachandran, Niki Parmar, David Luan, Tsung-Yi Lin, および Google Research の他の同僚には、アドバイスと有益な議論をいただき、感謝しています。また、アニメーションを準備してくれた Tom Small に感謝します。
3.FindIt:テキストの指示に基づいて画像内からサンドイッチの左半分を特定可能な統合モデル(2/2)関連リンク
1)ai.googleblog.com
FindIt: Generalized Object Localization with Natural Language Queries
2)arxiv.org
FindIt: Generalized Localization with Natural Language Queries

