
1.MaxViTとMAXIM:ViTの効率を更に高めた視覚タスク用新モデル(1/2)まとめ
・視覚領域では畳み込みやAttentionを取り入れた手法が主流だがMLPという手法もある
・ViTとMLPは計算量が画像サイズに対して二次関数的に増加する事に苦労している
・新しい多軸アプローチを取り入れてこの課題に挑戦しMaxViTとMAXIMの両モデルを発表
2.MaxViTとは?
以下、ai.googleblog.comより「A Multi-Axis Approach for Vision Transformer and MLP Models」の意訳です。元記事は2022年9月8日、Zhengzhong TuさんとYinxiao Liさんによる投稿です。
多層パーセプトロンは行動認識用モデルであるCoVeRでも採用されていた事を記憶しています。
アイキャッチ画像はstable diffusionの失敗例で、「MaxViTとMAXIM」というタイトルの相棒物の仮想映画のポスターを作ってみようとしたのですが、意図は汲み取ってくれるのですが、タイトル文字を書かせるが出来ないので単に二人組と何語なのかも不明な謎文字が映っている謎画像が大量に出来てしまい苦悩しました。プロンプト力が足りない。
畳み込みニューラルネットワーク(CNN:Convolutional Neural Networks)は、2012年にAlexNetが導入されて以来、コンピュータビジョン向けの機械学習アーキテクチャとして支配的な存在となっています。
最近、自然言語処理(NLP:Natural Language Processing)におけるTransformersの進化に触発され、注意(Attention)の仕組みが視覚モデルに取り入れられる例が目立つようになりました。
Attentionとは、入力データの一部を増加させ、他の部分を最小化することで、ネットワークがデータの小さいが重要な部分に集中できるようにするものです。Vision Transformer(ViT)は、コンピュータビジョンのモデル設計において、畳み込みを完全に排除した新しい状況を作り出しました。
ViTは画像の断片を単語の列とみなし、その上にTransformerエンコーダを適用します。十分に大きなデータセットで学習させた場合、ViTは画像認識において説得力のある性能を発揮します。畳み込みもAttentionも良好なパフォーマンスを得る事ができますが、どちらかを使わなければ良好なパフォーマンスを得られないわけではありません。
例えば、MLP-Mixerは、画像の断片をすべての空間位置に渡って混合するために、単純な多層パーセプトロン(MLP:Multi-Layer Perceptron)を採用し、結果として全てを多層パーセプトロンで実装した設計を実現しています。
これは、精度と学習・推論に必要な計算量とのトレードオフの観点から、既存の最先端の視覚モデルに対して競争力のある代替案と言えます。しかし、ViTとMLPの両モデルは、計算量が画像サイズに対して二次関数的に増加するため、より高い入力解像度への拡張に苦労しています。
本日は、シンプルかつ効果的で、オリジナルのViTとMLPモデルを改良し、高解像度、高密度の予測タスクによりよく適応でき、高い柔軟性と低い複雑性をもって異なる入力サイズに自然に適応できる新しい多軸アプローチ(multi-axis approach)を紹介します。
このアプローチに基づき、私達は高レベルおよび低レベルの視覚タスクのための2つの基幹モデルを構築した。1つ目は、ECCV 2022で発表予定の「MaxViT: Multi-Axis Vision Transformer」で説明し、画像分類、物体検出、セグメンテーション、品質評価、生成などの高レベルタスクの現状を大幅に改善することを示しています。
2つ目は、CVPR 2022で発表された「MAXIM: Multi-Axis MLP for Image Processing」で、UNetに似たアーキテクチャに基づき、ノイズ除去、ぼやけ除去(deblurring)、かすみ除去(dehazing)、雨の影響の除去(deraining)、低光量強調などの低レベルの画像処理タスクで競争力のある性能を達成するものです。効率的なTransformerとMLPモデルに関するさらなる研究を促進するため、MaxViTとMAXIMの両方のコードとモデルをオープンソース化しました。

概要
ViTで用いられているフルサイズのAttention(各画素が全画素に注目する)を、局所的なAttentionと(疎な)大域的なAttentionに分解した、多軸注意(multi-axis attention)を用いた新しいアプローチです。
下図に示すように、multi-axis attentionはblock attentionとgrid attentionを連続して組み合わせています。block attentionは、局所的なパターンを捉えるために、重複部のないウィンドウ(中間特徴表現マップの小さな断片)として動作し、grid attentionは長距離(大域的な)な相互作用のために、まばらにサンプリングされた均一なグリッドとして動作します。
block attentionとgrid attentionのウィンドウサイズはハイパーパラメータとして完全に制御でき、入力サイズに対して線形な計算量を確保することができます。
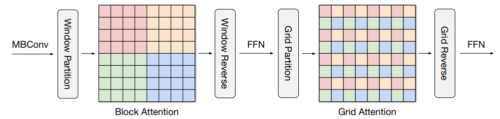
このような複雑性を低くしたAttentionは、多くの視覚タスク、特に高解像度の視覚予測に対する幅広い適用性を著しく向上させることができ、ViTで使用されているオリジナルのAttentionよりも高い汎用性を示します。私達はこの多軸Attentionのアプローチから2つの基幹的な実体、MaxViTとMAXIMを構築し、それぞれ高レベル、低レベルのタスクに対応させています。
MaxViT
MaxViTでは、まずMBConv(EfficientNet, V2で提案)と多軸Attentionを連結して、下図のような単一のMaxViTブロックを構築します。
この単一ブロックは、入力の解像度に関わらず、局所的および大域的な視覚情報を符号化することができます。そして、Attentionと畳み込みからなるブロックを単純に階層的に積み重ねることにより(ResNetやCoAtNetと同様)、均質なMaxViTのアーキテクチャが得られます。特に、MaxViTはこれまでの階層的アプローチとは異なり、初期の高解像度段階でもネットワーク全体を「見る」ことができ、様々なタスクでより強いモデル能力を発揮します。
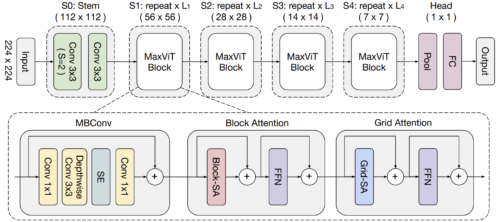
MaxViTのメタアーキテクチャ
3.MaxViTとMAXIM:ViTの効率を更に高めた視覚タスク用新モデル(1/2)関連リンク
1)ai.googleblog.com
A Multi-Axis Approach for Vision Transformer and MLP Models
2)arxiv.org
MaxViT: Multi-Axis Vision Transformer
3)openaccess.thecvf.com
MAXIM: Multi-Axis MLP for Image Processing(PDF)
4)github.com
google-research / maxvit
google-research / maxim

