
1.Look and Talk:視線を検知して呼び出しを認識するアシスタント(1/2)まとめ
・現在のGoogle Assistantは「OK Google」と呼びかける事で起動する仕組みに依存している
・ホームデバイスとの自然で直感的な対話方法を実現するために起動方法の改善を試みた
・「Look and Talk」ではユーザーは画面を見て話すだけで対話を開始する事が可能になる
2.Look and Talkとは?
以下、ai.googleblog.comより「Look and Talk: Natural Conversations with Google Assistant」の意訳です。元記事は2022年7月27日、Tuan Anh NguyenさんとSourish Chaudhuriさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by James Yarema on Unsplash
自然な会話では、私たちは何かを言う際に毎回、人の名前を呼ぶわけではありません。その代わりに、私たちは文脈に応じたシグナル伝達メカニズムに頼って会話を始めますが、多くの場合、アイコンタクトがそのために必要なすべてです。
Google Assistantは、現在95カ国以上、29以上の言語で利用可能ですが、主にホットワード(「Hey Google」または「OK Google」)の仕組みに依存し、毎月7億人以上がAssistantデバイス間で何かを成し遂げるのを助けてきました。仮想アシスタントが日常生活に欠かせない存在になるにつれ、私たちはより自然に会話を開始する方法を開発しています。
Google I/O 2022にて、Google Assistantを搭載したホームデバイスとの自然で直感的な対話方法を実現するための大きな進展である「Look and Talk」を発表しました。
これは、音声、ビデオ、テキストを同時に分析し、Nest Hub Maxに話しかけている事を判断する、初のマルチモーダルで、オンデバイスのアシスタント機能です。
8つの機械学習モデルを併用することで、このアルゴリズムは、アシスタントと関わるユーザーの意図を正確に特定するために、意図的な対話と通りすがりに見ただけの視線を区別することができます。デバイスから5ft以内に入ると、ユーザーは画面を見て話すだけで、アシスタントとの対話を開始することができます。
Look and Talkは、私たちの「AI原則」に沿って開発されました。音声と映像の処理に関する厳しい要件を満たしており、他のカメラセンシング機能と同様に、映像がデバイスから他に送信されることはありません。アシスタントの活動は、myactivity.google.comでいつでも停止、確認、削除することができます。これらの保護レイヤーを追加することで、あなたのデータを安全に保ちながら、Look and Talkをオンにした人のためだけに機能させることができます。
 Googleアシスタントは、ユーザーが話しかけているタイミングを正確に判断するために、さまざまなシグナルに依存しています。右側は、使用されている信号のリストで、ユーザーのデバイスへの近接度と視線方向に基づいて、各信号がいつトリガーされるかを示すインジケーターが表示されています。
Googleアシスタントは、ユーザーが話しかけているタイミングを正確に判断するために、さまざまなシグナルに依存しています。右側は、使用されている信号のリストで、ユーザーのデバイスへの近接度と視線方向に基づいて、各信号がいつトリガーされるかを示すインジケーターが表示されています。モデリングの課題
この機能は、学術研究用に開発されたモデルをベースにした技術的なプロトタイプとしてスタートしました。しかし、この機能を大規模に展開するためには、この機能特有の現実的な課題を解決する必要がありました。その課題とは
・さまざまな人口統計学的特性(年齢、肌の色など)をサポートすること
・照明(逆光、影のパターンなど)や音響(残響、暗騒音など)など、実世界の多様な環境に対応すること
・通常とは異なるカメラの視点への対処。スマートディスプレイは一般的にカウンタートップのデバイスとして使用されるので、ユーザーを見上げる形になります。モデルを学習するための研究データセットで通常使用される正面からの顔とは異なります。
・デバイス上でビデオを処理しながら、タイムリーな応答を保証するためにリアルタイムで実行すること
アルゴリズムの進化には、ドメイン適応やパーソナライゼーションから、領域固有のデータセット開発、フィールドテストとフィードバック、そしてアルゴリズム全体のチューニングの繰り返しに至るまで、様々なアプローチの実験が行われました。
技術概要
Look and Talkは、3つのフェーズで構成されています。第一段階では、アシスタントは視覚信号を使ってユーザーが自分に関わる意思を示していることを検知し、ユーザーの発話を聞くために「目を覚まします」。
第2段階では、視覚信号と音響信号を用いて、ユーザーの意図をさらに検証し、理解するように設計されています。Look and Talkは、第1と第2の処理段階におけるすべての信号を考慮し、その対話がアシスタントへの呼びかけを意図している可能性が高いかどうかを判断します。この2つのフェーズは、Look and Talkの中核となる機能であり、以下で説明されます。第3段階のクエリ実行は、典型的なクエリフローであり、このブログの範囲外です。
第1段階:アシスタントとの連携
Look and Talkの最初のフェーズは、登録ユーザーが意図的にアシスタントと会話しているかどうかを評価するように設計されています。Look and Talkは、顔検出を使用してユーザーの存在を特定し、検出された顔のボックスのサイズを使用して近接をフィルタリングして距離を推測し、次に既存のFace Matchシステムを使用して登録されたLook and Talkユーザーであるかどうかを判断します。
範囲内にいる登録ユーザーについては、カスタム視線モデルにより、そのユーザーがデバイスを見ているかどうかを判断します。このモデルは、マルチタワー畳み込みニューラルネットワークアーキテクチャを使用して、画像フレームから視線角度と視線有無のを信頼度の両方を推定し、1つのタワーは顔全体を処理し、別のタワーは目の周りの断片化画像を処理します。
デバイスの画面は、ユーザーが自然に見るであろうカメラの下の領域をカバーしているため、視線角度と視線有無予測は、デバイスの画面領域にマッピングされます。最終的な予測が誤った個別予測や不随意的な目の瞬きや急速な変化に堅牢なことを保証するために、個別フレームベースの平滑化関数を適用して誤った個別予測を除去しています。
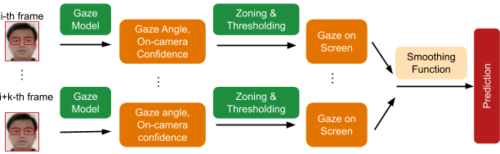
視線予測、後処理の概要
3.Look and Talk:視線を検知して呼び出しを認識するアシスタント(1/2)関連リンク
1)ai.googleblog.com
Look and Talk: Natural Conversations with Google Assistant

