
1.機械学習を使ったコード補完で開発者の生産性はどのくらい向上するのか?(2/2)まとめ
・MLによるコード補完は正しく見えてもコンパイルできないコードを提案する欠点がある
・この欠点を克服するためにセマンティックエンジンを併用して精度を向上している
・これによりGoでは8%のコンパイルエラー提案が80%がフィルタリングされ受理率も向上
2.複数行を提案するMLコード補完
以下、ai.googleblog.comより「ML-Enhanced Code Completion Improves Developer Productivity」の意訳です。元記事は2022年7月26日、Maxim TabachnykさんとStoyan Nikolovさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jefferson Santos on Unsplash
単一行/複数行のML補完を意味的に正しいかどうかチェックする
推論時、MLモデルは一般的に入力ウィンドウの外側のコードを認識しません。また、学習時に見たコードは、活発に変化するリポジトリでの補完に必要な最近の追加を見落とすかもしれません。
これは、MLによるコード補完の共通の欠点、つまり、モデルは正しく見えるがコンパイルできないコードを提案するかもしれないことにつながります。この問題は、社内のユーザー体験調査によると、時間の経過とともにユーザーの信頼を損ない、生産性を低下させる可能性があります。
私たちは、セマンティックエンジン(SE:Semantic Engines)を使用して、与えられた応答時間内で高速な意味的正誤チェックを行い(開始から完了まで100ms未満)、キャッシュされた抽象構文木を使用して、「完全な」構造理解を可能にしています。典型的なセマンティックチェックには、参照解決(このオブジェクトは存在しますか?)、メソッド呼び出しチェック(正しい数のパラメータでメソッドが呼び出されたことの確認など)、割り当て可能性チェック(予想通りの型であることの確認)などがあります。
例えば、コーディング対象言語がGoの場合、意味的正誤チェックの前にコンパイルエラーが含まれる提案は8%程度です。しかし、セマンティックチェックの適用により、コンパイル不能な提案の80%がフィルタリングされました。また、この機能を取り入れてから最初の6週間で、1行補完の提案受理率が1.9倍に向上しましたが、これはおそらくユーザーの信頼が高まったためと思われます。比較として、意味的正誤チェックを追加しなかった言語では、受理率は1.3倍しか向上しませんでした。
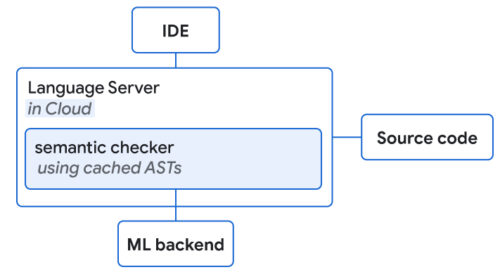
ソースコードにアクセスできる言語サーバとMLバックエンドはクラウド上に配置されています。両者はML補完候補のセマンティックチェックを行います。
成果
1万人以上のGoogle社内開発者がIDEで補完機能を有効にした結果、25-34%のユーザー受理率を測定しました。私達は、transformerベースのハイブリッドセマンティックMLコード補完は、コードの3%以上を補完し、Googlerのコーディング反復時間を(90%信頼水準で)6%減少させると判断しました。
この変動の大きさは、一般的にサブ集団にしか影響を与えない変換機能(主要なフレームワークなど)で観測される典型的な効果に対応するレベルのものですが、MLはほとんどの主要言語やエンジニアに一般化できる可能性を持っています。
| Fraction of all code added by ML | 2.60% |
| Reduction in coding iteration duration | 6% |
| Reduction in number of context switches | 7% |
| Acceptance rate (for suggestions visible for >750ms) | 25% |
| Average characters per accept | 21 |
1万人以上のGoogle社内開発者が8つの言語で日々の開発に使用し、実運用で測定された一行コード補完の主要な指標です。
| Fraction of all code added by ML (with >1 line in suggestion) | 0.60% |
| Average characters per accept | 73 |
| Acceptance rate (for suggestions visible for >750ms) | 34% |
複数行コード補完の主要な指標は、8つの言語で日々の開発に使用している5000人以上のGoogle社内開発者の実稼働状況に基づいて測定されています。
APIを探索しながら長い補完を提供する
また、セマンティック補完とフルライン補完を緊密に連携させました。セマンティックな単一トークン補完のドロップダウンが表示されたとき、MLモデルから返された単一行補完をインラインで表示します。後者は、ドロップダウンで選択されている項目の継続を表します。例えば、ユーザがあるAPIのメソッドに注目した場合、インラインのフルライン補完はメソッド呼び出しのすべてのパラメータを含む完全なメソッド呼び出しを表示します。

選択されているセマンティックドロップダウン補完の続きを継続するMLによる全行補完

MLによる複数行補完の提案例
結論と今後の課題
ルールベースのセマンティックエンジンと大規模言語モデルの組み合わせにより、より優れたコード補完を実現し、開発者の生産性を大幅に向上させる方法を示しました。
次のステップとして、推論時にMLモデルに追加情報を提供することにより、SEをさらに活用したいと考えています。例えば、長い予測がMLとSEの間を行き来し、SEが繰り返し正しさをチェックし、MLモデルにすべての可能な継続を提供するようなものです。MLを使った新しい機能を追加する際には、単に「賢い」結果だけでなく、生産性に良い影響を与えることを意識したいものです。
謝辞
本研究は、Google CoreとGoogle Research, Brain Teamの2年間の共同研究の成果です。Marc Rasi, Yurun Shen, Vlad Pchelin, Charles Sutton, Varun Godbole, Jacob Austin, Danny Tarlow, Benjamin Lee, Satish Chandra, Ksenia Korovina, Stanislav Pyatykh, Cristopher Claeys, Petros Maniatis, Evgeny Gryaznov, Pavel Sychev, Chris Gorgolewski, Kristof Molnar, Alberto Elizondo, Ambar Murillo, Dominik Schulz, David Tattersall, Rishabh Singh, Manzil Zaheer, Ted Ying, Juanjo Carin, Alexander Froemmgen, Maxim Kachurovskiy, and Marcus Revajの貢献に感謝します。
3.機械学習を使ったコード補完で開発者の生産性はどのくらい向上するのか?(2/2)関連リンク
1)ai.googleblog.com
ML-Enhanced Code Completion Improves Developer Productivity

